Cloud storage is useful for mobile and web apps because it provides an efficient and scalable way to store and retrieve data from anywhere in the world.
With cloud storage, mobile and web apps can easily scale their storage needs up or down depending on usage patterns. This means that developers don’t need to worry about running out of storage space or having to invest in expensive hardware to handle increased storage needs.
Files stored in the cloud can be accessed from anywhere in the world, as long as there is an internet connection. This makes it easy for mobile and web apps to store and retrieve data from different locations and devices.
Cloud services are typically offered as pay-as-you-go pricing model, which means that developers only pay for the storage and resources they actually use. This makes cloud storage an affordable option for mobile and web apps, especially those with limited budgets. also cloud providers typically have robust security measures in place to protect data from unauthorized access and ensure data privacy.
Amazon S3
Amazon S3 (Simple Storage Service) is a cloud-based storage service provided by Amazon Web Services (AWS). It is not an open-source technology, meaning that the source code of the service is not available for modification or redistribution by users. Instead, it is a proprietary technology owned and operated by AWS.
S3 Compatible services
An S3 compatible service is a cloud-based storage service that is designed to be compatible with the Amazon S3 (Simple Storage Service) API. This means that it provides a similar interface and functionality as Amazon S3, allowing users to easily migrate data and applications between the two services.
Some examples of S3 compatible services include:
Wasabi: A cloud storage service that provides an S3-compatible interface with no egress fees or API request fees.
DigitalOcean Spaces: A cloud storage service from DigitalOcean that provides an S3-compatible API with a simple pricing model.
Google Cloud Storage: A cloud storage service from Google Cloud Platform that provides an S3-compatible API along with additional features like object versioning and lifecycle management.
IBM Cloud Object Storage: A cloud storage service from IBM that provides an S3-compatible API along with features like built-in encryption and multi-region support.
Contabo: is a cheap alternative with unlimited free transfer to AWS S3 and other vendors. Billing is simple and month-to-month at all-inclusive rate and you can easily migrate from S3
Simple Storage Service gives you a URL for each file by assigning a unique URL to each object stored in the S3 bucket. The URL includes the bucket name, the key (or path) to the object, and the S3 endpoint, which is used to access the object.
For example, if you have an S3 bucket named “my-bucket” and a file named “my-file.jpg” stored in the bucket, the URL to access the file would be:
https://my-bucket.s3.amazonaws.com/my-file.jpg
As you can see the URL includes the domain name of your cloud provider but even when there is nothing technically wrong with it, can bring some disadvantages.
Some common problems on how URLs are created in S3 storage
Here are some of the of disadvantages of not using a custom domain with Amazon S3 storage can cause several problems, including:
URL appearance: When you access an S3 bucket using the default endpoint, the URL contains the bucket name and the Amazon S3 endpoint. The resulting URL can be long and difficult to remember, which can cause issues with branding and user experience.
SEO: Using the default S3 endpoint can also negatively impact your search engine optimization (SEO) efforts, as search engines may view the URL as less trustworthy or relevant.
SSL certificate: If you access an S3 bucket using the default endpoint, the SSL certificate presented to the user will be issued for the Amazon S3 endpoint, rather than your custom domain name. This can cause warnings to appear in the user’s browser, which can negatively impact trust and user experience.
CORS: If you are using cross-origin resource sharing (CORS) to allow access to your S3 bucket from other domains, the default S3 endpoint may not allow those requests due to security restrictions.
Maintenance: If you are using the default S3 endpoint, any changes to the S3 bucket or endpoint URLs may require updates to all references to the S3 bucket, which can be time-consuming and error-prone.
Overall, using a custom domain with an S3 storage can provide several benefits, including improved branding, better user experience, and stronger SEO.
There are several ways to provide a solution for the custom domain problem, most of the solutions you will find on the internet are related to cloud providers like Cloud Flare but in this article I want to propose a different approach of showing how this can be fixed using apache web server as a proxy, my goal is not to provide a step by step guide on how to setup a proxy but to provide the conceptual framework to understand how the proxy works
What is Apache
The Apache HTTP Server, commonly referred to as Apache web server, is a free and open-source cross-platform web server software developed and maintained by the Apache Software Foundation. It is one of the most widely used web servers in the world, serving as the backbone for many popular websites and web applications.
Apache web server is designed to be highly configurable and extensible, with a modular architecture that allows users to add or remove functionality as needed. It supports a wide range of features, including dynamic content generation, SSL/TLS encryption, proxying and caching, and authentication and authorization.
Apache web server is also highly portable, running on a wide range of operating systems including Windows, Linux, macOS, and Unix. It can be configured using a variety of tools and languages, including configuration files, command-line utilities, and programming languages such as Perl, PHP, and Python.
Overall, Apache web server is a versatile and powerful web server that provides a stable and reliable platform for serving web content and applications.
What is an Apache proxy
An Apache proxy, also known as an Apache reverse proxy, is a module of the Apache HTTP Server that allows the server to act as an intermediary between clients and other servers.
With an Apache proxy, incoming requests from clients are forwarded to one or more backend servers, which handle the request and return a response. The Apache proxy then forwards the response back to the client.
This can be useful for a variety of reasons, including load balancing, caching, and security. For example, an Apache proxy can be used to distribute incoming traffic across multiple backend servers to improve performance and availability. It can also be used to cache responses from backend servers to reduce the load on those servers and improve response times.
In addition, an Apache proxy can be used to add an extra layer of security to incoming traffic, by acting as a firewall and only allowing traffic from trusted sources.
Setting up an Apache proxy involves configuring the Apache HTTP Server to act as a reverse proxy and directing traffic to one or more backend servers. This can be done using the Apache mod_proxy module, which provides the necessary functionality to act as a reverse proxy.
#this is the configuration of the virtual hosting
SuexecUserGroup "#1010" "#1010"
ServerName files.jocheojeda.com
DocumentRoot /home/files/public_html
ErrorLog /var/log/virtualmin/files.jocheojeda.com_error_log
CustomLog /var/log/virtualmin/files.jocheojeda.com_access_log combined
ScriptAlias /cgi-bin/ /home/files/cgi-bin/
ScriptAlias /awstats/ /home/files/cgi-bin/
DirectoryIndex index.php index.php4 index.php5 index.htm index.html
<Directory /home/files/public_html>
Options -Indexes +IncludesNOEXEC +SymLinksIfOwnerMatch +ExecCGI
Require all granted
AllowOverride All Options=ExecCGI,Includes,IncludesNOEXEC,Indexes,MultiViews,SymLinksIfOwnerMatch
AddType application/x-httpd-php .php
AddHandler fcgid-script .php
AddHandler fcgid-script .php7.4
FCGIWrapper /home/files/fcgi-bin/php7.4.fcgi .php
FCGIWrapper /home/files/fcgi-bin/php7.4.fcgi .php7.4
</Directory>
<Directory /home/files/cgi-bin>
Require all granted
AllowOverride All Options=ExecCGI,Includes,IncludesNOEXEC,Indexes,MultiViews,SymLinksIfOwnerMatch
</Directory>
ProxyPass /.well-known !
RewriteEngine on
RemoveHandler .php
RemoveHandler .php7.4
FcgidMaxRequestLen 1073741824
<Files awstats.pl>
AuthName "files.jocheojeda.com statistics"
AuthType Basic
AuthUserFile /home/files/.awstats-htpasswd
require valid-user
</Files>
#these 2 likes are the one who forward the traffic from the custom domain files.jocheojeda.com to the contabo storage
ProxyPass / https://usc1.contabostorage.com/ade25b1c43c1457b87f0716a629d0ff8:files.jocheojeda/
ProxyPassReverse / https://usc1.contabostorage.com/ade25b1c43c1457b87f0716a629d0ff8:files.jocheojeda/
SSLProxyEngine on
Where the magic happens
You only need 2 lines in the configuration when you already have an apache virtual hosting already running to proxy the request from the client to the S3 storage service
ProxyPass / https://usc1.contabostorage.com/ade25b1c43c1457b87f0716a629d0ff8:files.jocheojeda/
ProxyPassReverse / https://usc1.contabostorage.com/ade25b1c43c1457b87f0716a629d0ff8:files.jocheojeda/ SSLProxyEngine on
Conclusions
As you can see is really easy to fix the problem of custom domains for an S3 storage, specially if you already have an apache webserver with virtual hosting running
I have been using XPO from DevExpress since day one. For me is the best O.R.M in the dot net world, so when I got the news that XPO was going to be free of charge I was really happy because that means I can use it in every project without adding cost for my customers.
Nowadays all my customer needs some type of mobile development, so I have decided to master the combination of XPO and Xamarin
Now there is a problem when using XPO and Xamarin and that is the network topology, database connections are no designed for WAN networks.
Let’s take MS SQL server as an example, here are the supported communication protocols
TCP/IP.
Named Pipes
To quote what Microsoft web site said about using the protocols above in a WAN network
In a fast-local area network (LAN) environment, Transmission Control Protocol/Internet Protocol (TCP/IP) Sockets and Named Pipes clients are comparable with regard to performance. However, the performance difference between the TCP/IP Sockets and Named Pipes clients becomes apparent with slower networks, such as across wide area networks (WANs) or dial-up networks. This is because of the different ways the interprocess communication (IPC) mechanisms communicate between peers.”
So, what other options do we have? Well if you are using the full DotNet framework you can use WCF.
So, it looks like WCF is the solution here since is mature and robust communication framework but there is a problem, the implementation of WCF for mono touch (Xamarin iOS) and mono droid (Xamarin Android)
You can read about Xamarin limitations in the following links
I don’t want to go into details about how the limitation of each platform affects XPO and WCF but basically the main limitation is the ability to use reflection and emit new code which is needed to generate the WCF client, also in WCF there are problems in the serialization behaviors.
So basically, what we need to do is to replace the WCF layer with some other technology to communicate to the database server
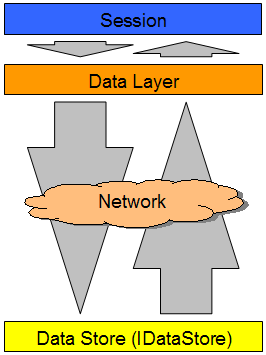
The technology I’ve selected for this AspNetCore which I would say is a really nice technology that is modern, multi-platform and easy to use. Here below you can see what is the architecture of the solution
AspNetCore
Rest API
So, what we need basically is to be able to communicate the data layer with the data store through a network architecture.
The network architecture that I have chosen is a rest API which is one of the strong fronts of AspNetCore. The rest API will work as the server that forward the communication from XPO to the Database and vice versa, you can find a project template of the server implementation here https://www.jocheojeda.com/download/560/ this implementation references one nuget where I have written the communication code, you can fine the nuget here https://nuget.bitframeworks.com/feeds/main/BIT.Xpo.AgnosticDataStore.Server/19.1.5.1
Note: you can download the full source code for this article in my GitHub repository
In the past few years, I have been working on developing mobile applications, in the mobile world most of the applications will consume some type of data service, the main problem here is how to choose the correct data service? There are a lot of technologies to expose data over the wire and all of them are good somehow, so for me, the quest is about to find a technology where can I use my current skill set.
Today subject of study is GraphQL, an open source technology developed by Facebook that is a data query and manipulation language for API.
The beauty of GraphQL is its efficient and flexible approach to develop web APIs that can be queried to return a different data structure in the opposite side of the REST API and traditional web services that return a fix data structure, you can learn more about the GrahpQL project on their website https://graphql.org/
First, we will start by creating a new Asp.net core web application
We name the application
Then we select Empty for the project type
Now that the project is created, we need to add a few NuGet packages, you can copy and paste the following snippet inside of your csproj file
Now let’s add 3 folders, schema, services and models
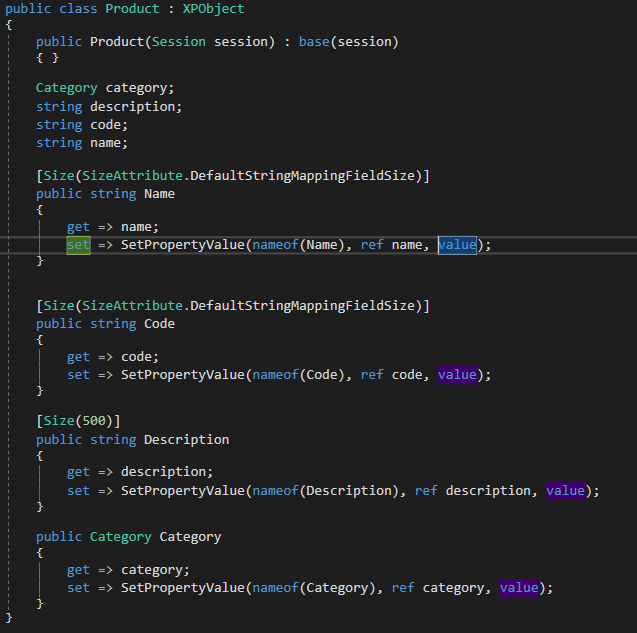
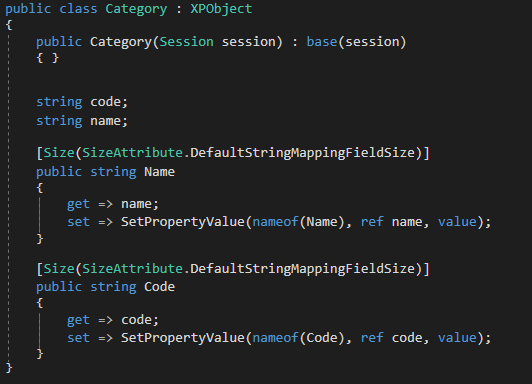
The basic structure of our project is ready, so let’s start adding some models, we will add 2 models products and categories, you can get the source of the files here
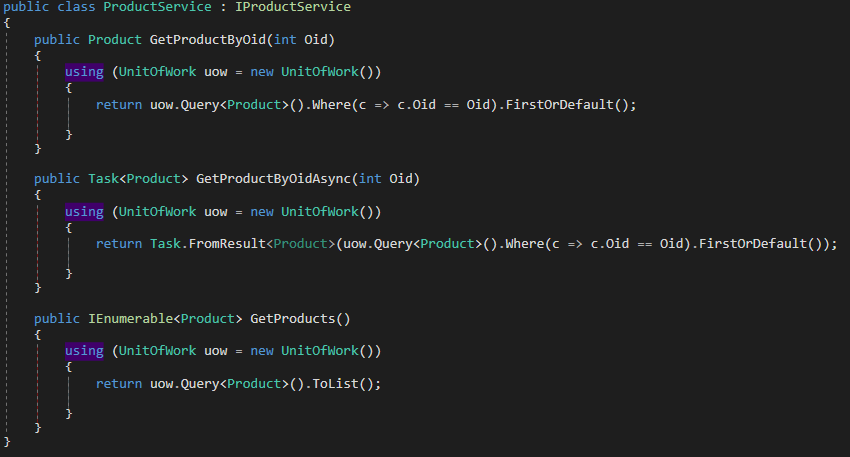
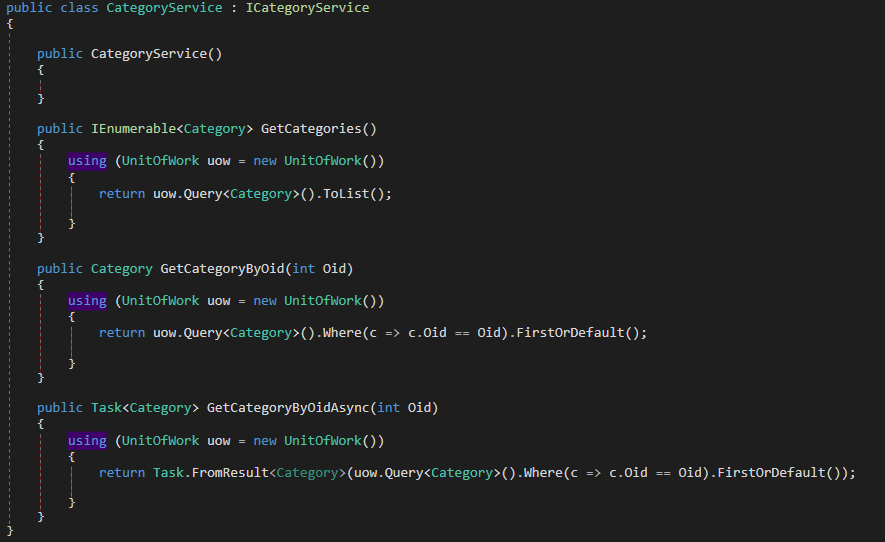
When you finish implementing the models the next step is to implement the services, remember that the main goal of GraphQL is to create a queryable layer between the client and the data service, you can architecture your service in the way that is more convenient for you but in this case I will create one service per entity, this services will be injected in our application using asp.net dependency injection. You can find the source for the services here
Product Service
Category Service
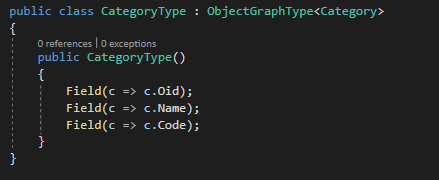
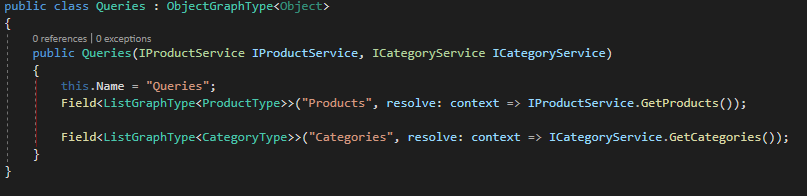
So far there we have not written any code related to GraphQL so now it’s the time. GraphQL does not directly expose your data model class instead it builds a type based on your model, let’s see how this will work for the Category model
As you can see, I have created a new class that inherits from ObjectGraphType<T> where T is our XPO persistent class. Also, in the constructor I used the fluent API to map the fields from the category model to the CategoryType class, the method Field contains several overloads so you can do any type of crazy stuff in here, but for now I’m going keep it simple, now lets create the type for the product model.
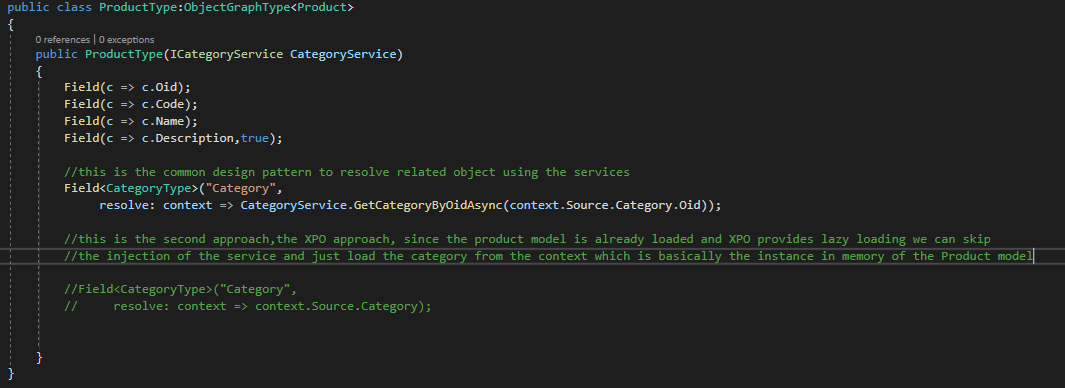
Now that we have created the ProductType class we can see that there are new characteristics here, the first new thing that you will notice is that in the constructor I injected the category service to load the category object related to the product, that is the common design pattern of GrahpQL, this approach is useful if you are using POCO objects. Also, if you see the commented-out code you can see that when we use XPO we don’t need to inject the category service since it can be loaded directly from the instance of the Product class using XPO lazy loading feature. You can find both graph types here
Now that we have our graph types, we need to create 2 more classes, an object that will hold our list of queries and a schema object that will provide information about the types and the queries that we are exposing, let’s start with the queries object
The Queries object is basically another graph type, but instead of exposing a model class is exposing the object class, it also uses the dependency injection to inject the 2 services that will forward the data to the fields. Now its time to create the schema for our GraphQL service
A GraphQL schema can only expose one query so that is why I have created the object queries to hold all the possible subqueries of our services. As you can see, I injected the queries object and the dependency resolver, you can find the code for these classes here.
Now its time to go back to the asp.net core service and start the configuration of GrahpQL, let’s start with the program class
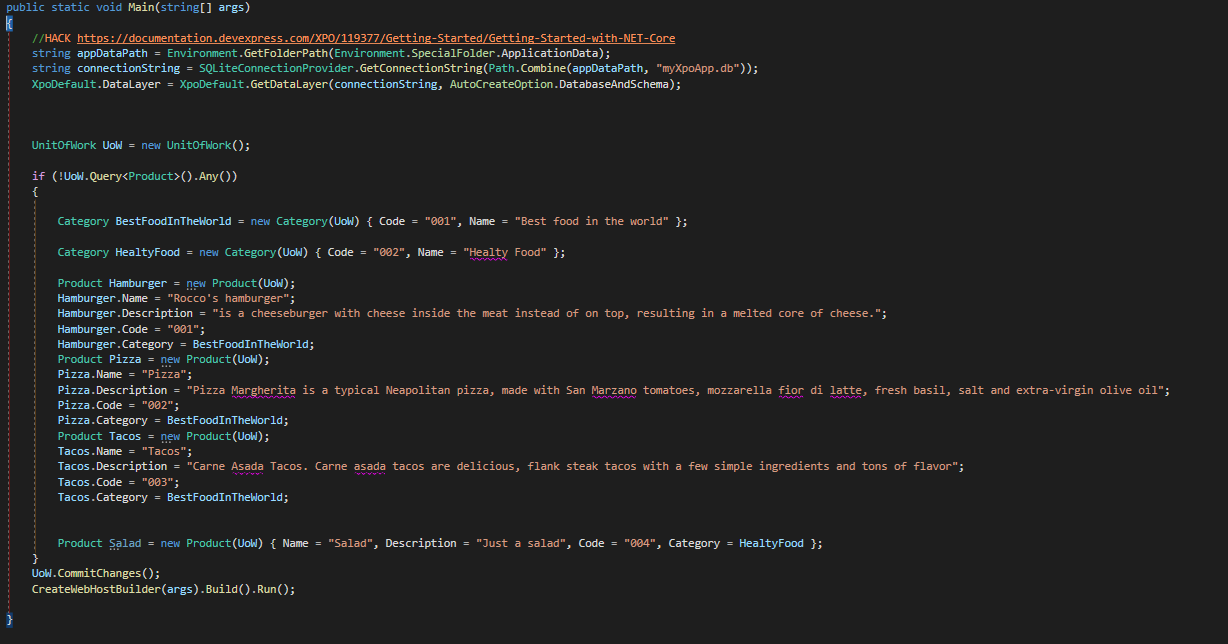
As you can see in the main method there is some boilerplate code to initialize XPO data layer and create some sample data, nothing new if you are an XPO user you might be already familiar with this code. Now let’s move to the startup class
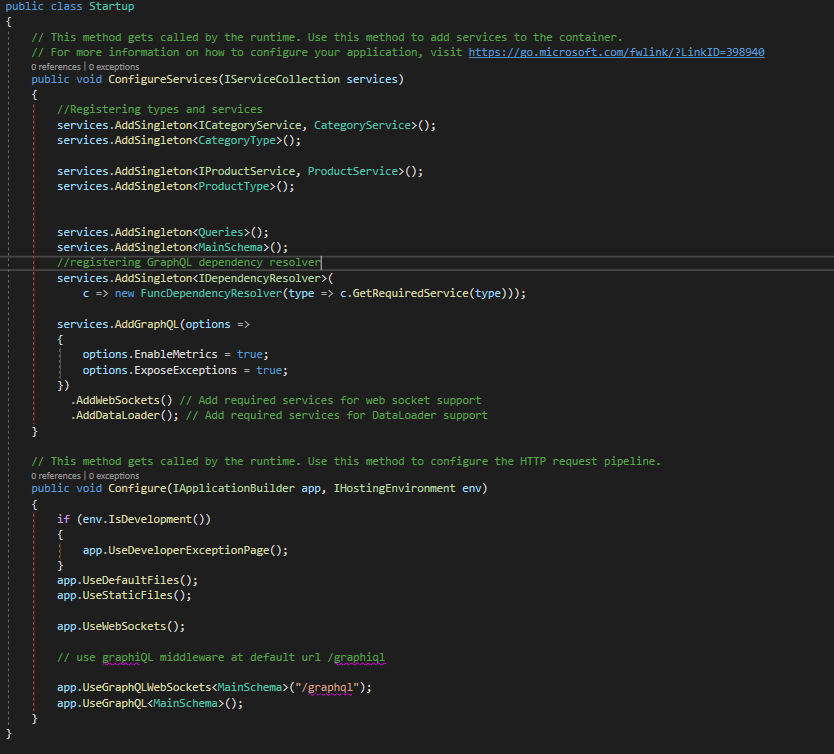
As any asp.net core web application, there are 2 important methods let’s see what happened on each of them.
In the configure services method I register the services I created and the graph types also added the GraphQL service and the web sockets and data loader.
Now in the configure method I enabled the use of default files and static files, web sockets also I exposed the GrahpQL schema using web sockets and GrahpQL (this is the HTTP version of the API)
Our API is almost done, there is only one last step we need to do, we need a way to test our API for that we will use Graphical which is a web client to query GrahpQL APIs, the graphical project is hosted here https://github.com/graphql/graphiql but to make it simpler you can download the files from my GitHub repository here
Let’s create a wwwroot folder and add the graphical files into it
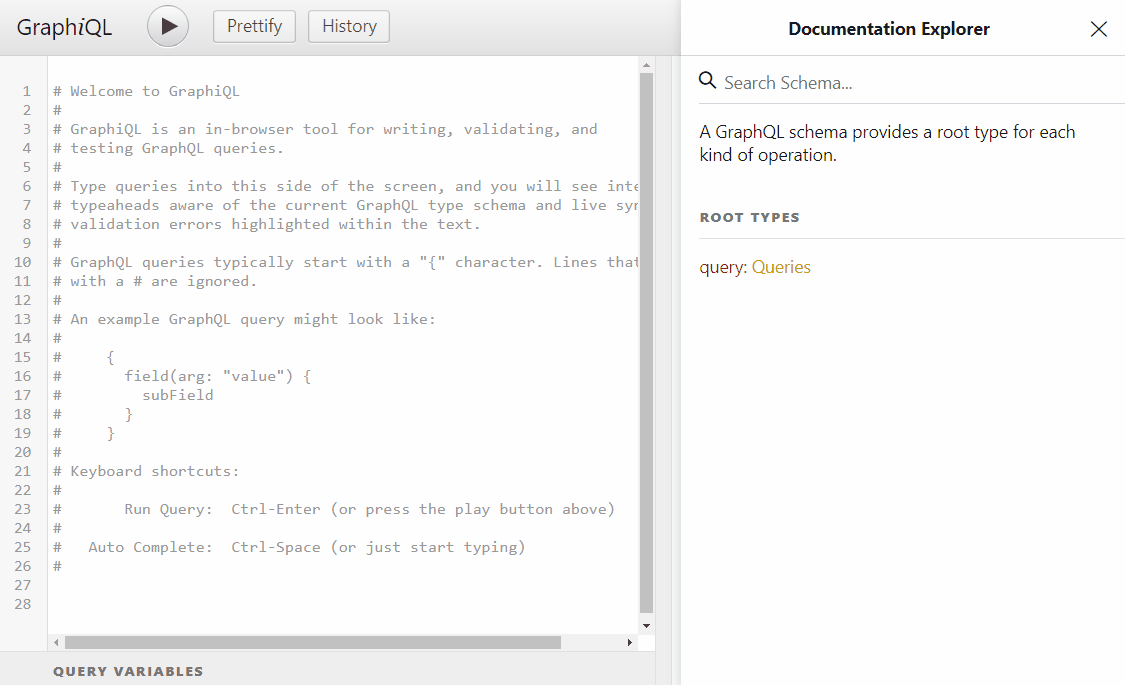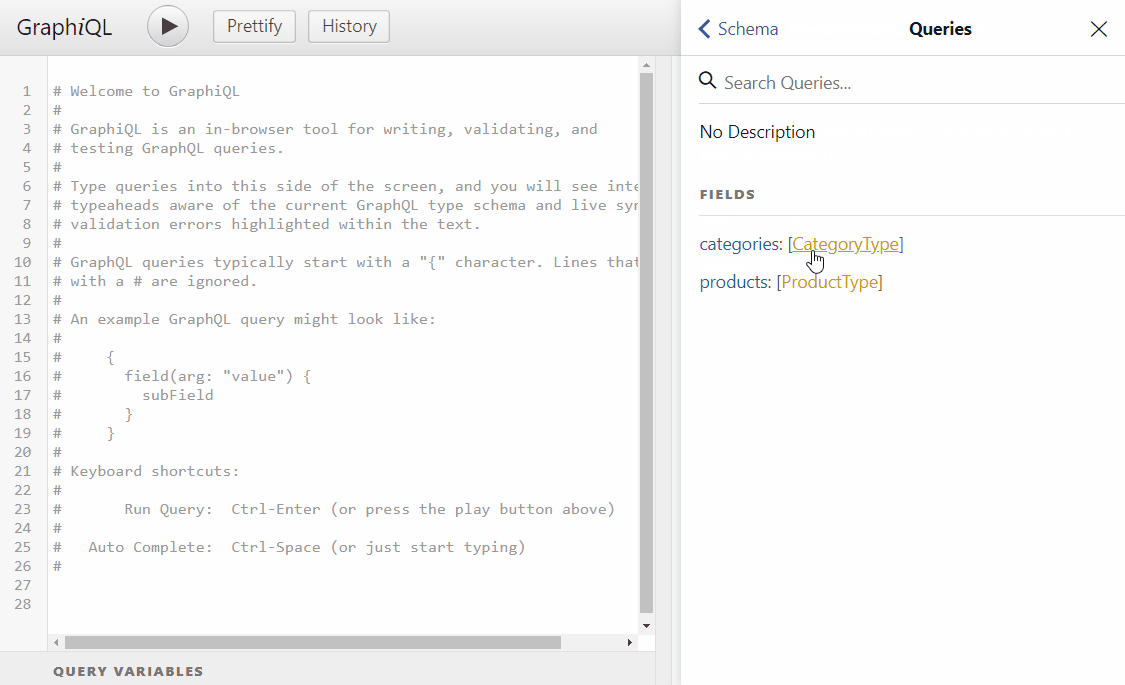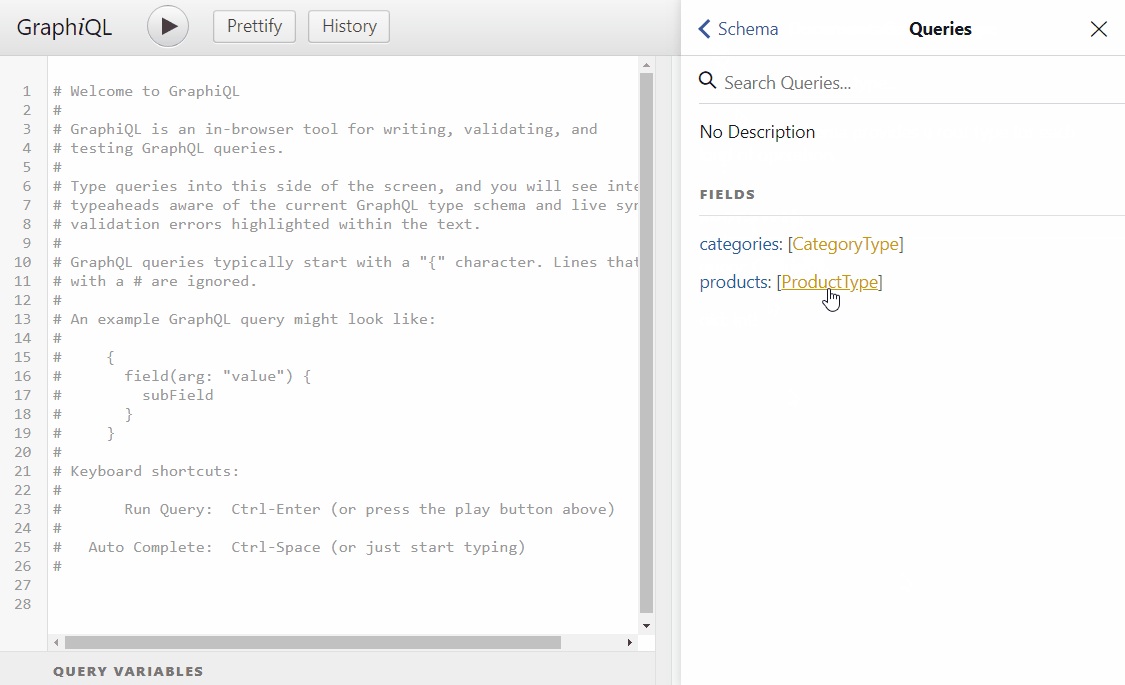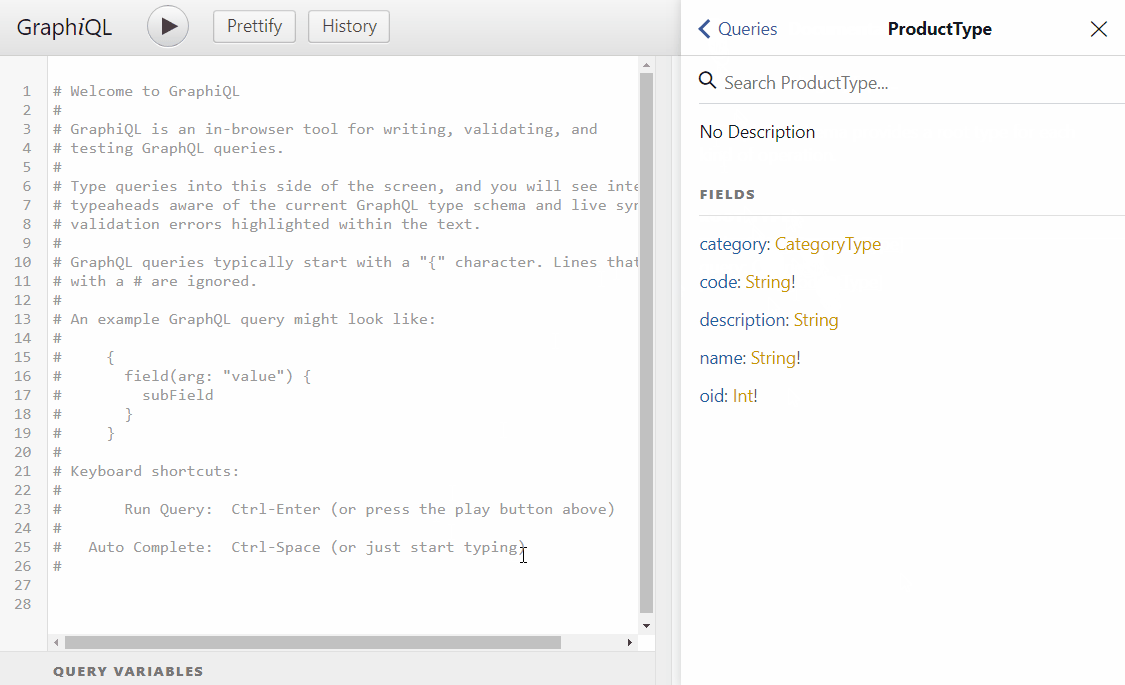
Run the application, you should see the graphical U.I and you should be able to navigate the API documentation
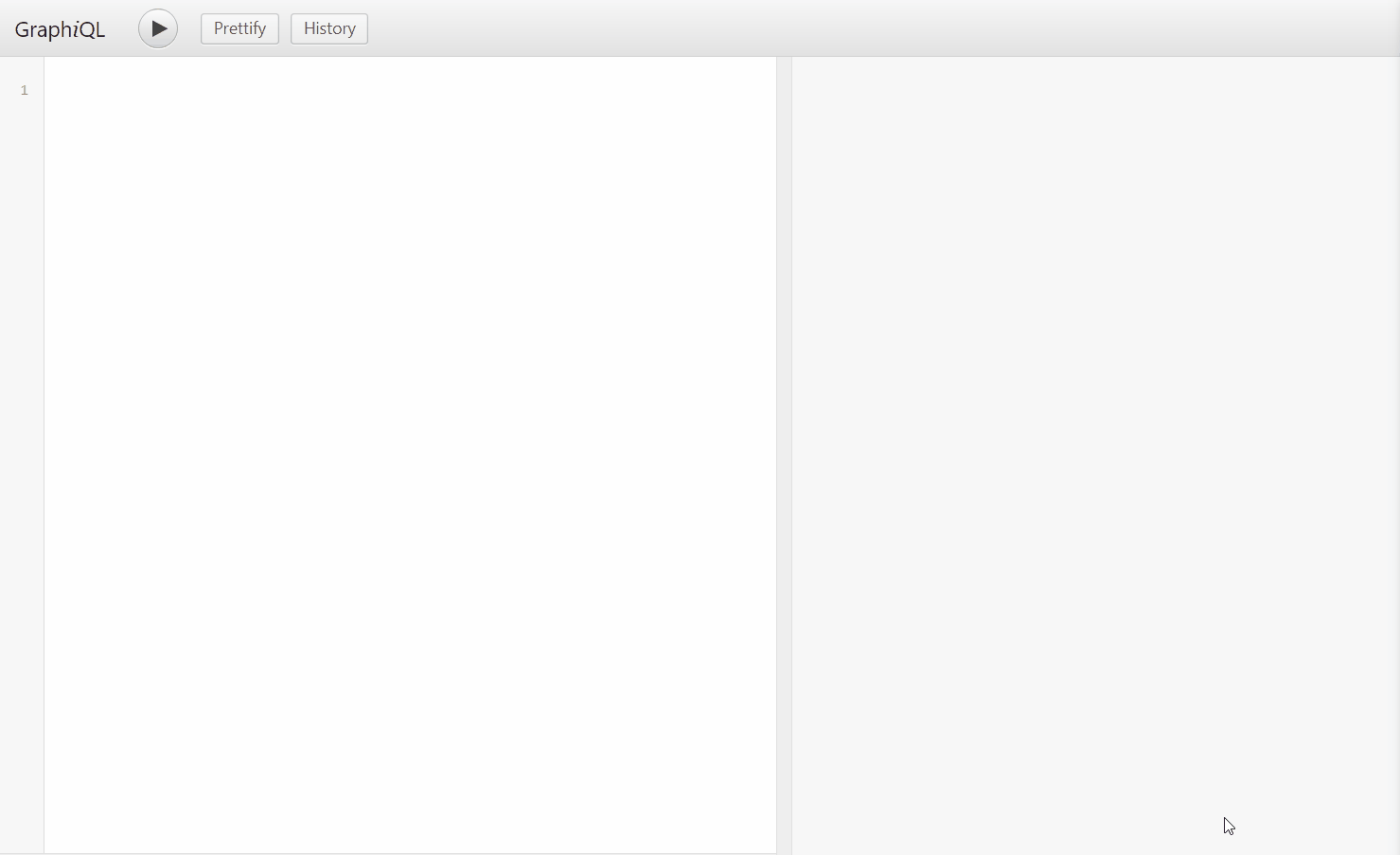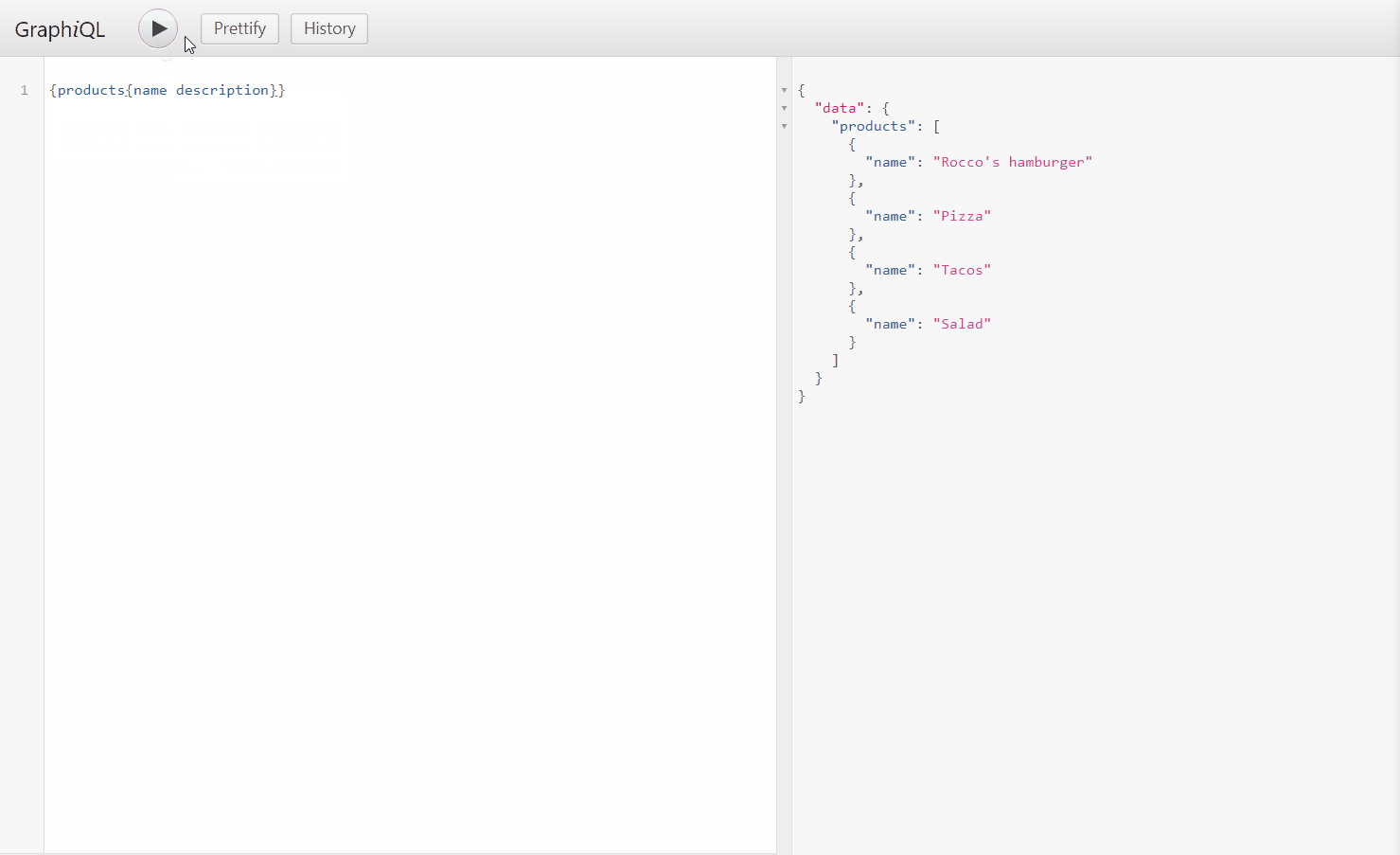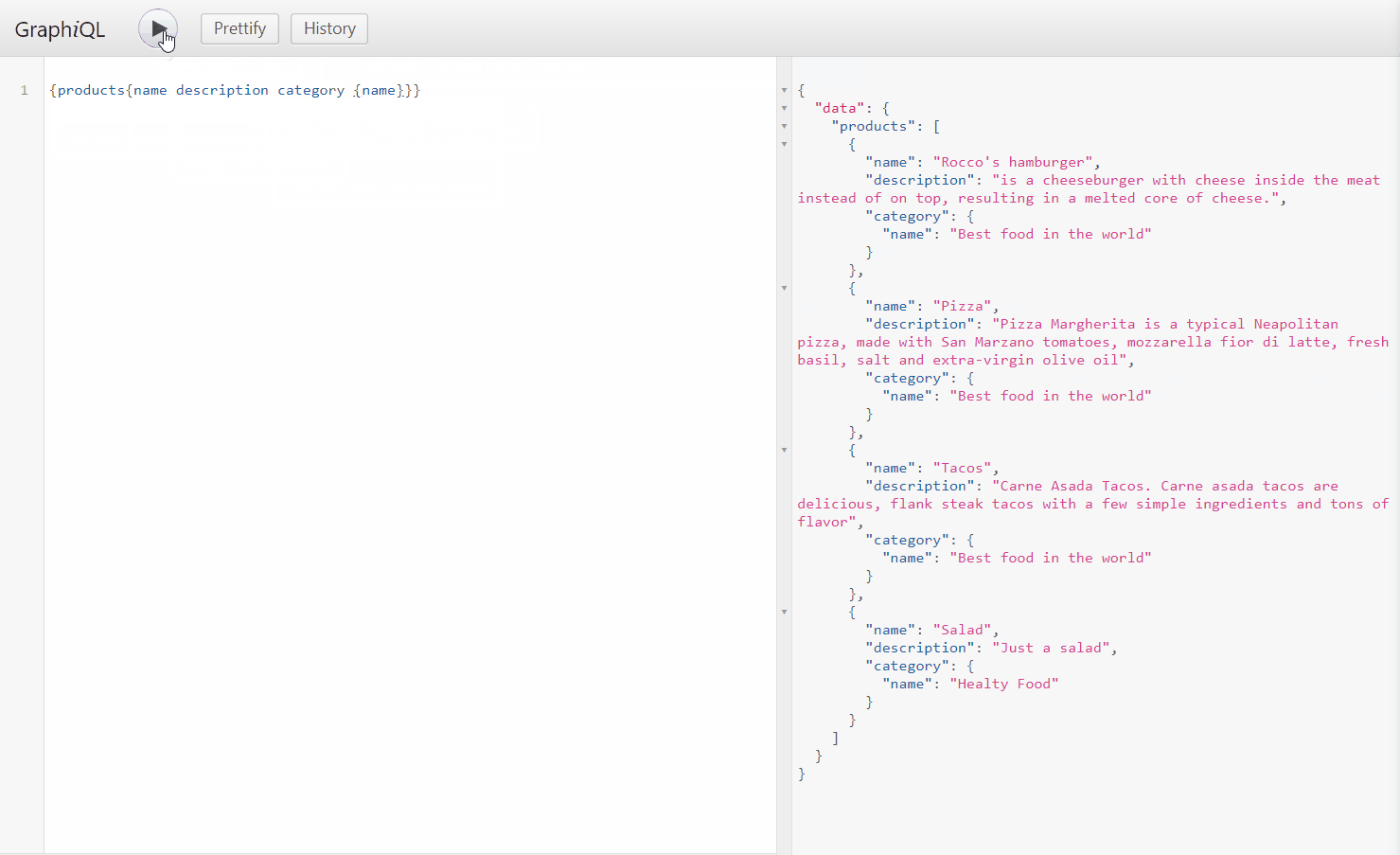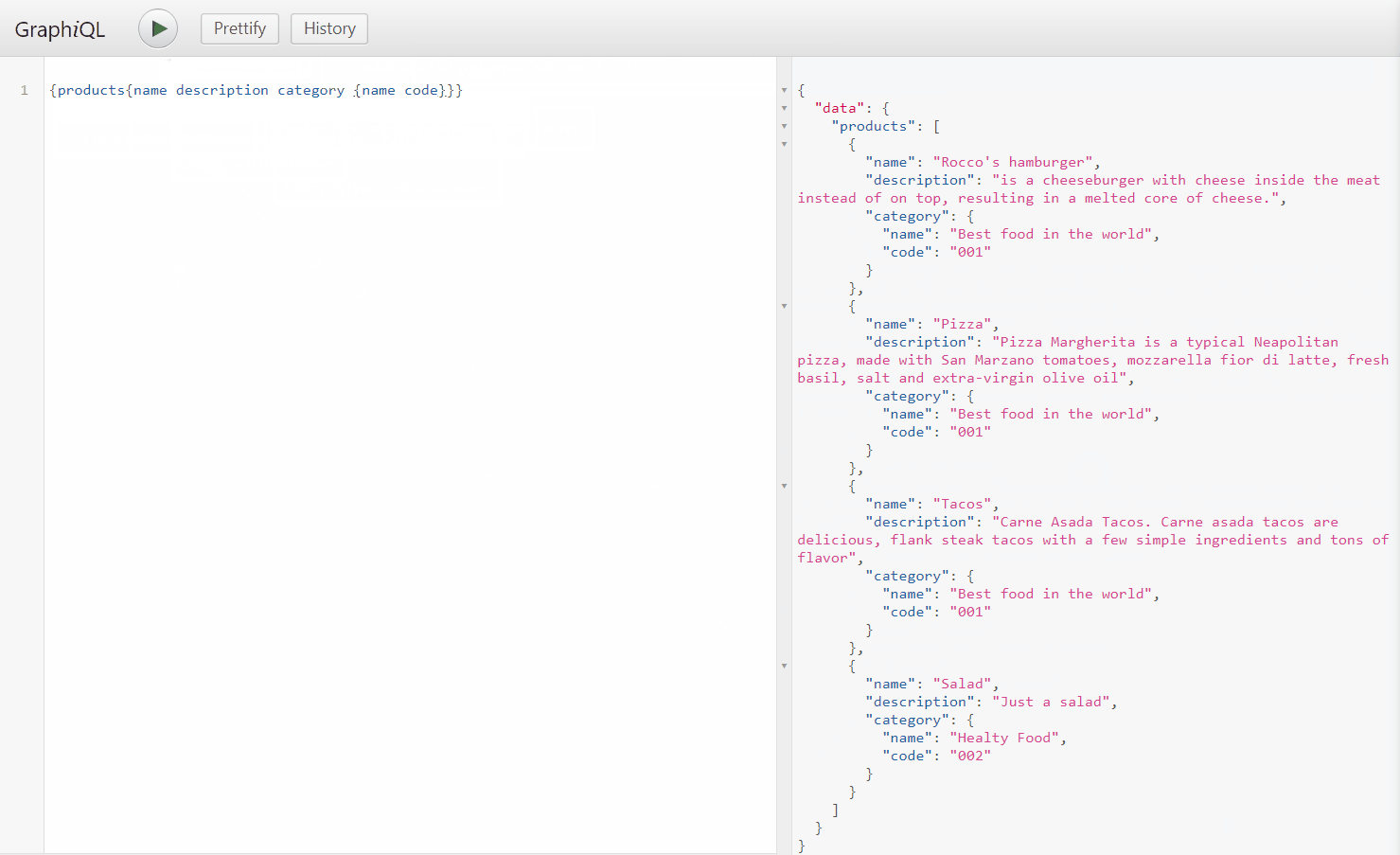
or you can query of XPO ORM
As you can see there is autocomplete on the query editor also we are able to query objects and nested objects on a field-based manner
This article is the first article on a series of how to expose any XPO ORM using GraphQL, in the next post we will learn about mutations