
On my GUID, common problems using GUID identifiers
A GUID (Globally Unique Identifier) is a unique reference number used as an identifier in computer systems. GUIDs are usually 128-bit numbers and are created using specific algorithms that are designed to make each GUID unique.
Characteristics of GUIDs:
- Uniqueness: The primary characteristic of a GUID is its uniqueness. The intent of a GUID is to be able to uniquely identify a resource, entity, or a record in any context, across multiple systems and databases, without overlap.
- Size: A GUID is typically a 128-bit number, which means there are a huge number of possible GUIDs (2 to the power of 128, or about 3.4 × 10^38).
- Format: GUIDs are usually expressed as 32 hexadecimal digits, grouped in a specific way and separated by hyphens, e.g.,
3F2504E0-4F89-11D3-9A0C-0305E82C3301. - No Semantic Meaning: A GUID itself does not carry any information about the data it represents. It is simply a unique identifier.
Why are GUIDs useful?
- Distributed Systems: GUIDs are especially useful in distributed systems for ensuring unique identifiers across different parts of the system without needing to communicate with a central authority.
- No Central Authority Needed: With GUIDs, there’s no need for a central authority to manage the issuance of unique identifiers. Any part of your system can generate a GUID and be fairly certain of its uniqueness.
- Database Operations: GUIDs are also used as unique identifiers in databases. They are useful for primary keys, and they help avoid collisions that might occur during database operations like replication.
- Safer Data Exposure: Because a GUID does not disclose information about the data it represents, it is safer to expose in public-facing operations, such as in URLs for individual data records, compared to an identifier that might be incrementing or otherwise guessable.
However, using GUIDs also has its trade-offs. Their large size compared to a simple integer ID means they take up more storage space and index memory, and are slower to compare. Also, because they are typically generated randomly, they can lead to fragmentation in the database, which can negatively impact performance.
Disadvantages
While GUIDs (Globally Unique Identifiers) have several advantages, such as providing a unique identifier across different systems and domains without the need for a central authority, they do come with their own set of problems and limitations. Here are some common issues associated with using GUIDs:
- Size: A GUID is 128 bits, much larger than an integer or long. This increased size can lead to more memory and storage usage, especially in large systems. They also take longer to compare than integers.
- Non-sequential: GUIDs are typically generated randomly, so they are not sequential. This can lead to fragmentation in databases, where data that is frequently accessed together is stored in scattered locations. This can slow down database performance.
- Readability: GUIDs are not human-friendly, which makes them difficult to debug or troubleshoot. For example, if you’re using GUIDs in URLs, it’s hard for users to manually enter them or understand them.
- Collision Risk: While the risk of generating a duplicate GUID is incredibly small, it is not zero. Especially in systems that generate a very large number of GUIDs, the probability of collision (though still extremely small) is greater than zero. This is known as the “birthday problem” in probability theory.
- No Information Content: GUIDs don’t provide any information about the data they represent. Unlike structured identifiers, you can’t encode any information in a GUID.
- Network Sorting: GUIDs can have different sort orders, depending on whether they’re sorted as strings or as raw byte arrays, and this can lead to confusion and mistakes.
To mitigate some of these problems, some systems use GUIDs in a modified or non-standard way. For example, COMB (combined GUID/timestamp) GUIDs or sequential GUIDs add a sequential element to reduce database fragmentation, but these come with their own trade-offs and complexities.
COMB GUIDS
A COMB (Combined Guid/Timestamp) GUID is a strategy that combines the uniqueness of GUIDs with the sequential nature of timestamps to mitigate some of the issues associated with GUIDs, particularly the database fragmentation issue.
A typical GUID is 128 bits and is usually displayed as 32 hexadecimal characters. When generating a COMB GUID, part of the GUID is replaced with the current timestamp. The portion of the GUID that is replaced and the format of the timestamp can vary depending on the specific implementation, but a common strategy is to replace the least significant bits of the GUID with the current timestamp.
Here’s a broad overview of how it works:
- Generate a regular GUID.
- Get the current timestamp (in a specific format, such as the number of milliseconds since a particular epoch).
- Replace a part of the GUID with the timestamp.
Because the timestamp is always increasing, the resulting COMB GUIDs will also increase over time, meaning that when new rows are inserted into a database, they are likely to be added to the end of the table or index, thus minimizing fragmentation.
However, there are some trade-offs to consider:
- Uniqueness: Because part of the GUID is being replaced with a timestamp, there is a slightly higher chance of collision compared to a regular GUID. However, as long as the non-timestamp portion of the GUID is sufficiently large and random, the chance of collision is still extremely small.
- Size: A COMB GUID is the same size as a regular GUID, so it doesn’t mitigate the issue of GUIDs being larger than simpler identifiers like integers.
- Readability and information content: Like regular GUIDs, COMB GUIDs are not human-friendly and don’t provide information about the data they represent.
- Sorting dependance: In most cases, COMB GUIDs are generated by a custom algorithm that adds a timestamp. This means that you also need an algorithm to extract the timestamp and execute the sorting based on these timestamp values. Additionally, you might need to implement your algorithm twice: once for the client side and once for the database engine
It’s worth noting that different systems and languages may have their own libraries or functions for generating COMB GUIDs. For example, in .NET, the NHibernate ORM has a comb identifier generator that generates COMB GUIDs.
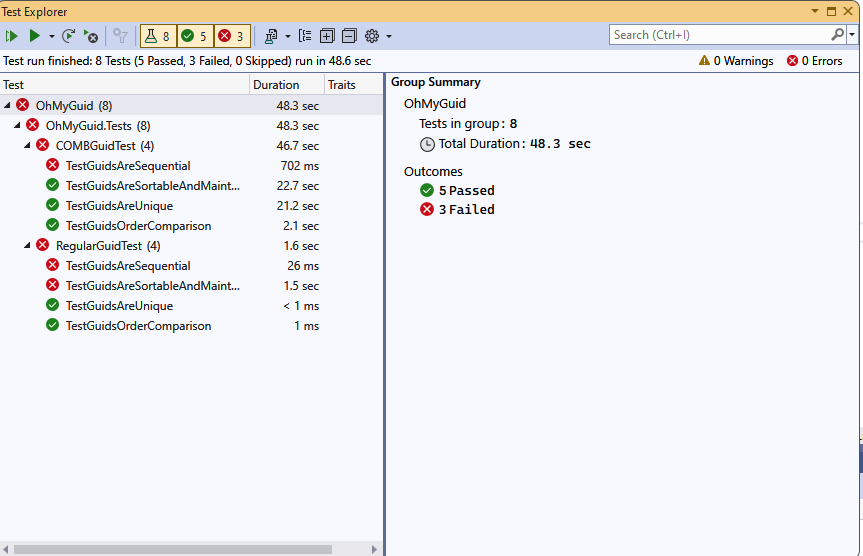
And before I say good bye to this article, here is a test project to probe my point
https://github.com/egarim/OhMyGuid
And here are the test results
Until the next time, happy coding ))