
by Joche Ojeda | Jan 22, 2025 | ADO, ADO.NET, C#, Data Synchronization, EfCore, XPO, XPO Database Replication
Working with the SyncFramework, I’ve noticed a recurring pattern when discussing schema design with customers. One crucial question that often surprises them is about their choice of primary keys: “Are you using auto-incremental integers or unique identifiers (like GUIDs)?”
Approximately 90% of users rely on auto-incremental integer primary keys. While this seems like a straightforward choice, it can create significant challenges for data synchronization. Let’s dive deep into how different database engines handle auto-increment values and why this matters for synchronization scenarios.
Database Implementation Deep Dive
SQL Server
SQL Server uses the IDENTITY property, storing current values in system tables (sys.identity_columns) and caching them in memory for performance. During restarts, it reads the last used value from these system tables. The values are managed as 8-byte numbers internally, with new ranges allocated when the cache is exhausted.
MySQL
MySQL’s InnoDB engine maintains auto-increment counters in memory and persists them to the system tablespace or table’s .frm file. After a restart, it scans the table to find the maximum used value. Each table has its own counter stored in the metadata.
PostgreSQL
PostgreSQL takes a different approach, using separate sequence objects stored in the pg_class catalog. These sequences maintain their own relation files containing crucial metadata like last value, increment, and min/max values. The sequence data is periodically checkpointed to disk for durability.
Oracle
Oracle traditionally uses sequences and triggers, with modern versions (12c+) supporting identity columns. The sequence information is stored in the SEQ$ system table, tracking the last number used, cache size, and increment values.
The Synchronization Challenge
This diversity in implementation creates several challenges for data synchronization:
- Unpredictable Sequence Generation: Even within the same database engine, gaps can occur due to rolled-back transactions or server restarts.
- Infrastructure Dependencies: The mechanisms for generating next values are deeply embedded within each database engine and aren’t easily accessible to frameworks like Entity Framework or XPO.
- Cross-Database Complexity: When synchronizing across different database instances, coordinating auto-increment values becomes even more complex.
The GUID Alternative
Using GUIDs (Globally Unique Identifiers) as primary keys offers a solution to these synchronization challenges. While GUIDs come with their own set of considerations, they provide guaranteed uniqueness across distributed systems without requiring centralized coordination.
Traditional GUID Concerns
- Index fragmentation
- Storage size
- Performance impact
Modern Solutions
These concerns have been addressed through:
- Sequential GUID generation techniques
- Improved indexing in modern databases
- Optimizations in .NET 9
Recommendations
When designing systems that require data synchronization:
- Consider using GUIDs instead of auto-increment integers for primary keys
- Evaluate sequential GUID generation for better performance
- Understand that auto-increment values, while simple, can complicate synchronization scenarios
- Plan for the infrastructure needed to maintain consistent primary key generation across your distributed system
Conclusion
The choice of primary key strategy significantly impacts your system’s ability to handle data synchronization effectively. While auto-increment integers might seem simpler at first, understanding their implementation details across different databases reveals why GUIDs often provide a more robust solution for distributed systems.
Remember: Data synchronization is not a trivial problem, and your primary key strategy plays a crucial role in its success. Take the time to evaluate your requirements and choose the appropriate approach for your specific use case.
Till next time, happy delta encoding.

by Joche Ojeda | Jan 22, 2025 | ADO.NET, C#, Data Synchronization, Database, DevExpress, XPO, XPO Database Replication
SyncFramework for XPO is a specialized implementation of our delta encoding synchronization library, designed specifically for DevExpress XPO users. It enables efficient data synchronization by tracking and transmitting only the changes between data versions, optimizing both bandwidth usage and processing time.
What’s New
- Base target framework updated to .NET 8.0
- Added compatibility with .NET 9.0
- Updated DevExpress XPO dependencies to 24.2.3
- Continued support for delta encoding synchronization
- Various performance improvements and bug fixes
Framework Compatibility
- Primary Target: .NET 8.0
- Additional Support: .NET 9.0
Our XPO implementation continues to serve the DevExpress community.
Key Features
- Seamless integration with DevExpress XPO
- Efficient delta-based synchronization
- Support for multiple database providers
- Cross-platform compatibility
- Easy integration with existing XPO and XAF applications
As always, if you own a license, you can compile the source code yourself from our GitHub repository. The framework maintains its commitment to providing reliable data synchronization for XPO applications.
Happy Delta Encoding! ?
by Joche Ojeda | May 5, 2023 | Application Framework, XAF, XPO, XPO Database Replication
I will explain what XAF is just for the sake of the consistency of this article, XAF is a low code application framework for line of business applications that runs on NET framework (windows forms and web forms) and in dotnet (windows forms, Blazor and Web API)
XAF is laser focus on productivity, DevExpress team has created several modules that encapsulate design patterns and common tasks needed on L.O.B apps.
The starting point in XAF is to provide a domain model using an ORMs like XPO or Entity framework and then XAF will create an application for you using the target platform of choice.
It’s a common misunderstanding that you need to use and ORM in order to provide a domain model to XAF
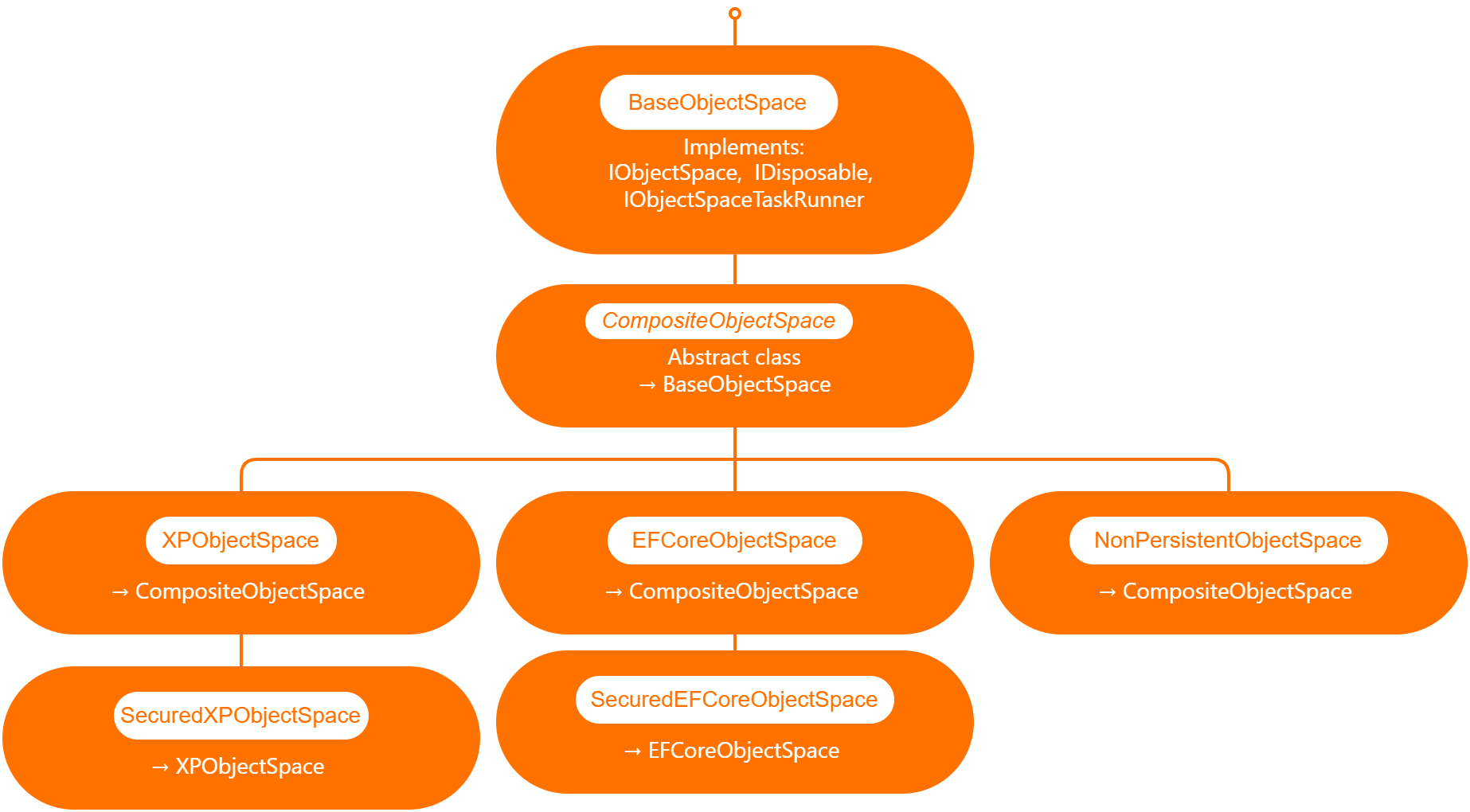
DevExpress team has created ObjectSpace abstraction so XAF can be extended to use different data access technologies ( you can read more about it here https://docs.devexpress.com/eXpressAppFramework/DevExpress.ExpressApp.BaseObjectSpace)
Out of the box XAF provide 3 branches of object spaces as show is the graph below.
XPObjectSpace: this is the object space that allows you to use XPO as a data access technology.
EfCoreObjectSpace: this is the object space that allows you to use Microsoft Entity Framework as a data access technology.
NonPersistenObjectSpace: this object space is interesting as it provides the domain model needed for XAF to generate the views and interact with the data is not attached to an ORM technology so it’s up to us to provide the data, also this type of object space can be used in combination with XPObjectSpace and EfCoreObjectSpace
When querying external data sources, you also need to solve the problem of filtering and sorting data in order to provide a full solution, for that reason DevExpress team provide us with the DynamicCollection class, that is a proxy collection that allows you to filter and sort an original collection without changing it.
Now that we know the parts involved in presenting data in a XAF application, we can define the required flow.
[DefaultClassOptions]
[DefaultProperty(nameof(Article.Title))]
[DevExpress.ExpressApp.ConditionalAppearance.Appearance("", Enabled = false, TargetItems = "*")]
[DevExpress.ExpressApp.DC.DomainComponent]
public class Article : NonPersistentObjectBase {
internal Article() { }
public override void Setup(XafApplication application) {
base.Setup(application);
// Manage various aspects of the application UI and behavior at the module level.
application.SetupComplete += Application_SetupComplete;
}
- Wire the application object space created event.
private void Application_SetupComplete(object sender, EventArgs e) {
Application.ObjectSpaceCreated += Application_ObjectSpaceCreated;
}
private void Application_ObjectSpaceCreated(object sender, ObjectSpaceCreatedEventArgs e) {
var npos = e.ObjectSpace as NonPersistentObjectSpace;
if (npos != null) {
new ArticleAdapter(npos);
new ContactAdapter(npos);
}
}
public ArticleAdapter(NonPersistentObjectSpace npos) {
this.objectSpace = npos;
objectSpace.ObjectsGetting += ObjectSpace_ObjectsGetting;
}
private void ObjectSpace_ObjectsGetting(object sender, ObjectsGettingEventArgs e) {
if(e.ObjectType == typeof(Article)) {
var collection = new DynamicCollection(objectSpace, e.ObjectType, e.Criteria, e.Sorting, e.InTransaction);
collection.FetchObjects += DynamicCollection_FetchObjects;
e.Objects = collection;
}
}
private void DynamicCollection_FetchObjects(object sender, FetchObjectsEventArgs e) {
if(e.ObjectType == typeof(Article)) {
e.Objects = articles;
e.ShapeData = true;
}
}
Full source code here
In conclusion the ObjectSpace abstraction ensures that different data access technologies can be employed, while the DynamicCollection class allows for seamless filtering and sorting of data from external sources. By following the outlined steps, developers can create robust, adaptable, and efficient applications with XAF, ultimately saving time and effort while maximizing application performance.
by Joche Ojeda | Oct 7, 2018 | XPO, XPO Database Replication
After 15 years of working with XPO, I have seen many tickets asking if XPO is capable of doing data replication and all the time DevExpress team answer those tickets saying that replication its out of the scope of XPO and that it’s actually true.
So, to start talking about database replication lets try to define what “replication” means. Here is the definition of replication according to Wikipedia
“A computational task is typically replicated in space, i.e. executed on separate devices, or it could be replicated in time, if it is executed repeatedly on a single device. Replication in space or in time is often linked to scheduling algorithms”
The keywords on the above statement are task, space and time, so to replicate a database operation we need to know the following information
- What was the task?
- Who performed the task?
- When was the task performed?
- Who needs to know about the task what was performed?
Now let’s think what are the steps that any traditional database does, in order to replicate the data between instances
- It shares a copy of the database schema to the other instances/locations/devices
- It logs the DML statements that happened to a main instance/location/device
- It broadcast the statements on this log to the other instances/locations/devices
- it processes the statements on the target instance/locations/devices
Now the question is, can we do the same with XPO?
thanks to the great architecture develop by the XPO Team, the answer is a big YES!!!
so, let’s compare how you can match traditional database replication with XPO
|
Traditional database replication |
XPO database replication |
| 1 |
Share a copy of the database schema. |
In XPO we can re-create a database schema using the method UpdateSchema from the Session class. |
| 2 |
Logs the DML statements. |
In XPO we can keep track of the BaseStatement at the DataLayer level. |
| 3 |
Broadcast the statements
|
We can transport the log of statements using any of the dot net network technologies like WCF, remoting or Web API. |
| 4 |
Process the statements on the target instance, device or location
|
To process any kind of BaseStatement we can use the XPO DataLayer on the target instance, device or location |
So, it looks like DotNet and XPO provide us of all the necessary infrastructure to do a database replication so why not give it a try right?