
by Joche Ojeda | Jan 22, 2024 | Sqlite
SQLite and Its Journal Modes: Understanding the Differences and Advantages
SQLite, an acclaimed lightweight database engine, is widely used in various applications due to its simplicity, reliability, and open-source nature. One of the critical aspects of SQLite that ensures data integrity and supports various use-cases is its “journal mode.” This mode is a part of SQLite’s transaction mechanism, which is vital for maintaining database consistency. In this article, we’ll explore the different journal modes available in SQLite and their respective advantages.
Understanding Journal Modes in SQLite
Journal modes in SQLite are methods used to handle transactions and rollbacks. They dictate how the database engine logs changes and how it recovers in case of failures or rollbacks. There are several journal modes available in SQLite, each with unique characteristics suited for different scenarios.
1. Delete Mode
Description:
The default mode in SQLite, Delete mode, creates a rollback journal file alongside the database file. This file records a copy of the original unchanged data before any modifications.
Advantages:
- Simplicity: Easy to understand and use, making it ideal for basic applications.
- Reliability: It ensures data integrity by preserving original data until the transaction is committed.
2. Truncate Mode
Description:
Truncate mode operates similarly to Delete mode, but instead of deleting the journal file at the end of a transaction, it truncates it to zero length.
Advantages:
- Faster Commit: Reduces the time to commit transactions, as truncating is generally quicker than deleting.
- Reduced Disk Space Usage: By truncating the file, it avoids leaving large, unused files on the disk.
3. Persist Mode
Description:
In Persist mode, the journal file is not deleted or truncated but is left on the disk with its header marked as inactive.
Advantages:
- Reduced File Operations: This mode minimizes file system operations, which can be beneficial in environments where these operations are expensive.
- Quick Restart: It allows for faster restarts of transactions in busy systems.
4. Memory Mode
Description:
Memory mode stores the rollback journal in volatile memory (RAM) instead of the disk.
Advantages:
- High Performance: It offers the fastest possible transaction times since memory operations are quicker than disk operations.
- Ideal for Temporary Databases: Best suited for databases that don’t require data persistence, like temporary caches.
5. Write-Ahead Logging (WAL) Mode
Description:
WAL mode is a significant departure from the traditional rollback journal. It writes changes to a separate WAL file without changing the original database file until a checkpoint occurs.
Advantages:
- Concurrency: It allows read operations to proceed concurrently with write operations, enhancing performance in multi-user environments.
- Consistency and Durability: Ensures data integrity and durability without locking the entire database.
6. Off Mode
Description:
This mode disables the rollback journal entirely. Transactions are not atomic in this mode.
Advantages:
- Maximum Speed: It can be faster since there’s no overhead of maintaining a journal.
- Use Case Specific: Useful for scenarios where speed is critical and data integrity is not a concern, like intermediate calculations or disposable data.
Conclusion
Choosing the right journal mode in SQLite depends on the specific requirements of the application. While Delete and Truncate modes are suitable for most general purposes, Persist and Memory modes serve niche use-cases. WAL mode stands out for applications requiring high concurrency and performance. Understanding these modes helps developers and database administrators optimize SQLite databases for their particular needs, balancing between data integrity, speed, and resource utilization.
In summary, SQLite’s flexibility in journal modes is a testament to its adaptability, making it a preferred choice for a wide range of applications, from embedded systems to web applications.

by Joche Ojeda | Jan 15, 2024 | ADO.NET, C#, Database, Sqlite
SQLite, known for its simplicity and lightweight architecture, offers unique opportunities for developers to integrate custom functions directly into their applications. Unlike most databases that require learning an SQL dialect for procedural programming, SQLite operates in-process with your application. This design choice allows developers to define functions using their application’s programming language, enhancing the database’s flexibility and functionality.
Scalar Functions
Scalar functions in SQLite are designed to return a single value for each row in a query. Developers can define new scalar functions or override built-in ones using the CreateFunction method. This method supports various data types for parameters and return types, ensuring versatility in function creation. Developers can specify the state argument to pass a consistent value across all function invocations, avoiding the need for closures. Additionally, marking a function as isDeterministic optimizes query compilation by SQLite if the function’s output is predictable based on its input.
Example: Adding a Scalar Function
connection.CreateFunction(
"volume",
(double radius, double height) => Math.PI * Math.Pow(radius, 2) * height);
var command = connection.CreateCommand();
command.CommandText = @"
SELECT name,
volume(radius, height) AS volume
FROM cylinder
ORDER BY volume DESC
";
Operators
SQLite implements several operators as scalar functions. Defining these functions in your application overrides the default behavior of these operators. For example, functions like glob, like, and regexp can be custom-defined to change the behavior of their corresponding operators in SQL queries.
Example: Defining the regexp Function
connection.CreateFunction(
"regexp",
(string pattern, string input) => Regex.IsMatch(input, pattern));
var command = connection.CreateCommand();
command.CommandText = @"
SELECT count()
FROM user
WHERE bio REGEXP '\w\. {2,}\w'
";
var count = command.ExecuteScalar();
Aggregate Functions
Aggregate functions return a consolidated value from multiple rows. Using CreateAggregate, developers can define and override these functions. The seed argument sets the initial context state, and the func argument is executed for each row. The resultSelector parameter, if specified, calculates the final result from the context after processing all rows.
Example: Creating an Aggregate Function for Standard Deviation
connection.CreateAggregate(
"stdev",
(Count: 0, Sum: 0.0, SumOfSquares: 0.0),
((int Count, double Sum, double SumOfSquares) context, double value) => {
context.Count++;
context.Sum += value;
context.SumOfSquares += value * value;
return context;
},
context => {
var variance = context.SumOfSquares - context.Sum * context.Sum / context.Count;
return Math.Sqrt(variance / context.Count);
});
var command = connection.CreateCommand
();
command.CommandText = @"
SELECT stdev(gpa)
FROM student
";
var stdDev = command.ExecuteScalar();
Errors
When a user-defined function throws an exception in SQLite, the message is returned to the database engine, which then raises an error. Developers can customize the SQLite error code by throwing a SqliteException with a specific SqliteErrorCode.
Debugging
SQLite directly invokes the implementation of user-defined functions, allowing developers to insert breakpoints and leverage the full .NET debugging experience. This integration facilitates debugging and enhances the development of robust, error-free custom functions.
This article illustrates the power and flexibility of SQLite’s approach to user-defined functions, demonstrating how developers can extend the functionality of SQL with the programming language of their application, thereby streamlining the development process and enhancing database interaction.
Github Repo

by Joche Ojeda | Jul 26, 2023 | Blazor, C#, Sqlite, WebAssembly
In the evolving panorama of contemporary web application development, a technology that has particularly caught attention is Microsoft’s Blazor WebAssembly. This powerful tool allows for a transformative approach to managing and interacting with client-side data, offering innovative capabilities that are shaping the future of web applications.
Understanding Blazor WebAssembly
Blazor WebAssembly is a client-side web framework from Microsoft. It allows developers to build interactive web applications using C# instead of JavaScript. As the name suggests, it uses WebAssembly, a binary instruction format for a stack-based virtual machine, providing developers with the ability to run client-side web applications directly in the browser using .NET.
The Power of SQLite
SQLite, on the other hand, is a software library that provides a relational database management system (RDBMS). It operates directly on disk files without the need for a separate server process, making it ideal for applications that need local storage. It’s compact, requires zero-configuration, and supports most of the SQL standard, making it an excellent choice for client-side data storage and manipulation.
Combining Blazor WebAssembly with SQLite
By combining these two technologies, you can unlock the full potential of client-side data handling. Here’s how:
Self-Contained and Cross-Platform Development
Both Blazor WebAssembly and SQLite are self-contained systems, requiring no external dependencies. They also both provide excellent cross-platform support. This makes your applications highly portable and reduces the complexity of the development environment.
Offline Availability
SQLite enables the storage of data directly in the client’s browser, allowing your Blazor applications to work offline. Changes made offline can be synced with the server database once the application goes back online, providing a seamless user experience.
Superior Performance
Blazor WebAssembly runs directly in the browser, offering near-native performance. SQLite, being a lightweight yet powerful database, reads and writes directly to ordinary disk files, providing high-speed data access. This combination ensures your application runs quickly and smoothly.
Full .NET Support and Shared Codebase
With Blazor, you can use .NET for both client and server-side code, enabling code sharing and eliminating the need to switch between languages. Coupled with SQLite, developers can use Entity Framework Core to interact with the database, maintaining a consistent, .NET-centric development experience.
Where does the magic happens?
The functionality of SQLite with WebAssembly may vary based on your target framework. If you’re utilizing .NET 6 and Microsoft.Data.SQLite 6, your code will reference SQLitePCLRaw.bundle_e_sqlite3 version 2.0.6. This bundle doesn’t include the native SQLite reference, as demonstrated in the following image
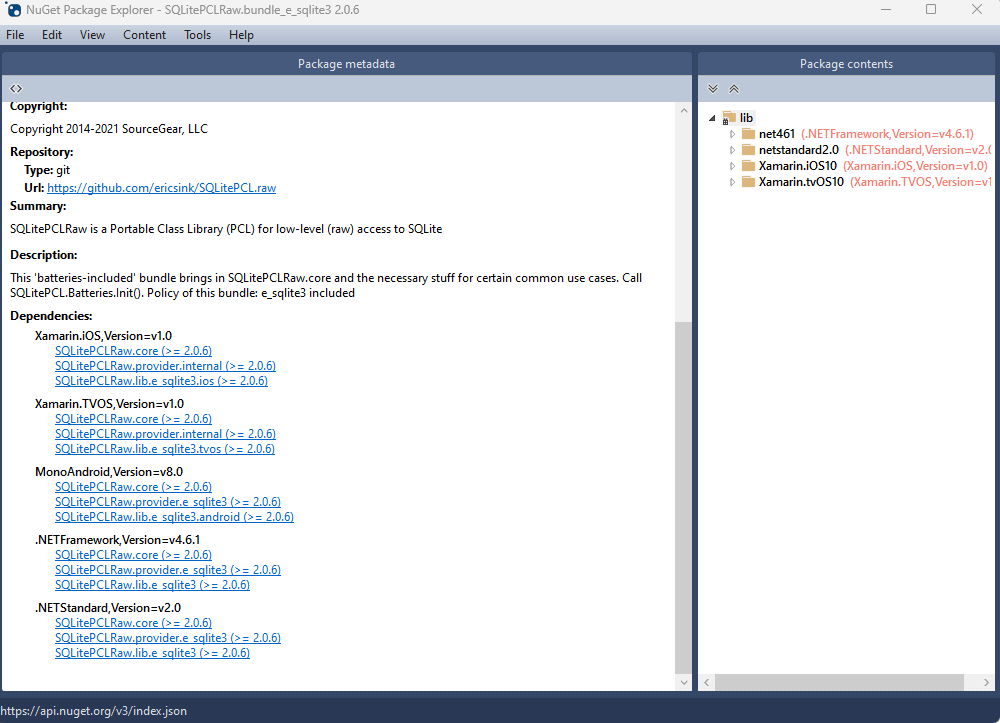
This implies that you’ll need to rely on .NET 6’s native dependencies to include your custom version of lib.e_sqlite3, compiled specifically for WebAssembly. For more detailed information about native dependencies, please refer to the provided links.
https://github.com/egarim/XpoNet6WasmSqlite
https://learn.microsoft.com/en-us/aspnet/core/blazor/webassembly-native-dependencies?view=aspnetcore-6.0
If you’re using .NET 7 or later, your reference from Microsoft.Data.SQLite will depend on SQLitePCLRaw.bundle_e_sqlite3 version 2.1.5. This bundle provides several targets for the native SQLite library (e_sqlite3), as can see in the accompanying image.
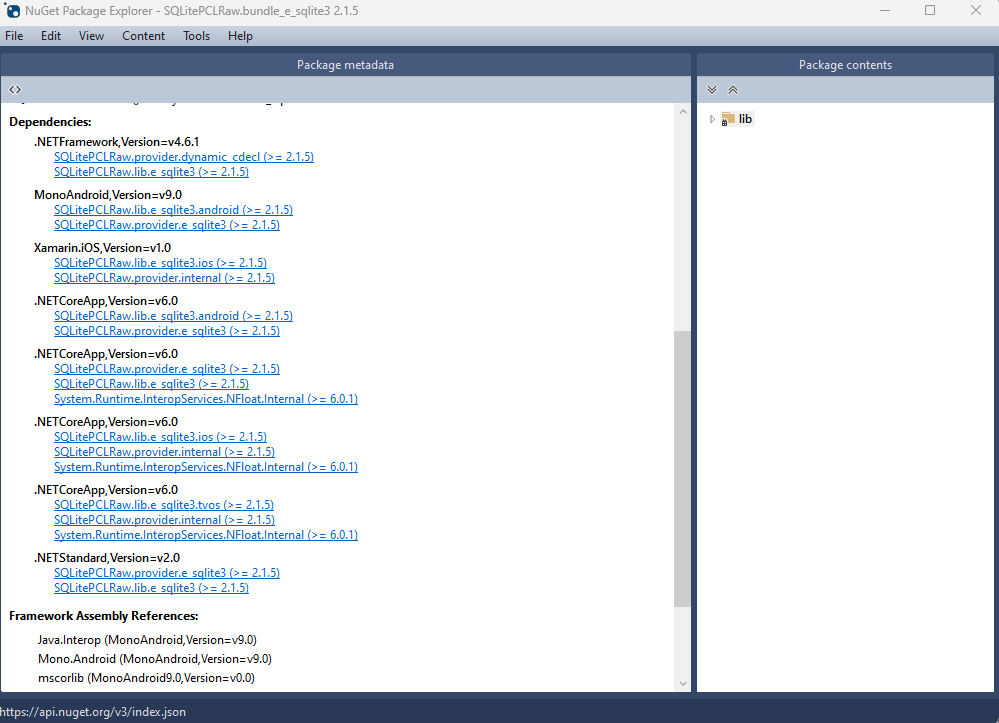
This indicates that we can utilize SQLite on any platform supported by .NET, provided that we supply the native reference for SQLite.
Conclusion
Blazor WebAssembly and SQLite together offer a compelling option for developers looking to leverage the power of client-side data. Their combination enables the development of web applications with high performance, offline availability, and a unified language platform.
This potent mix empowers developers to rethink what’s possible with web application development, pushing the boundaries of what we can achieve with client-side data storage and manipulation. In a world where user experience is paramount, the coupling of these technologies truly helps in unleashing the full potential of client-side data.

by Joche Ojeda | Jul 10, 2023 | Blazor, Sqlite, WebAssembly
Blazor is a framework for building interactive client-side web UI with .NET, developed by Microsoft. It allows developers to build full-stack web applications using C# instead of JavaScript.
Blazor comes in two different hosting models:
1. Blazor Server: In this model, the application runs on the server from within an ASP.NET Core app. UI updates, event handling, and JavaScript calls are handled over a SignalR connection.
2. Blazor Web Assembly: In this model, the application runs directly in the browser on a Web Assembly-based .NET runtime. Blazor Web Assembly includes a proper .NET runtime implemented in Web Assembly, a standard that defines a binary format for executable programs in web pages.
In both models, you can write your code in C#, compile it, and have it run in the browser. However, the way the code is executed differs significantly.
Blazor Web Assembly has a few key features:
– Runs in the browser: The app’s .NET assemblies and its runtime are downloaded into the browser and run locally. There’s no need for ongoing active server connection like in Blazor Server.
– Runs on Web Assembly: Web Assembly (wasm) is a binary instruction format for a stack-based virtual machine. It’s designed as a portable target for the compilation of high-level languages like C, C++, and Rust, allowing deployment on the web for client and server applications.
– Can be offline capable: Blazor Web Assembly apps can download the necessary resources to the client machine and run offline.
– Full .NET debugging support: Developers can debug their application using the tools they are accustomed to, like Visual Studio and Visual Studio Code.
– Sharing code between server and client: Since Blazor uses .NET for both server-side and client-side, code can easily be shared or moved, which is especially useful for data validation and model classes.
SQLite
As an alternative, Indexed DB, a low-level API for client-side storage of significant amounts of structured data, can be used as a backing store. However, using SQLite in a web browser through Web Assembly and Indexed DB is a rather advanced topic that may require additional libraries to manage the details.
Another way to use SQLite with Web Assembly is on the server side, particularly when using technologies like WASI (Web Assembly System Interface), which aims to extend the capabilities of Web Assembly beyond the browser. With WASI, Web Assembly modules could directly access system resources like the file system, and thus could interact with an SQLite database in a more traditional way.
Web Assembly and Native References
Applications built with Blazor Web Assembly (since net6) can incorporate native dependencies that are designed to function on Web Assembly. The .NET Web Assembly construction tools, which are also utilized for ahead-of-time (AOT) compilation of a Blazor application to Web Assembly and for relinking the runtime to eliminate unnecessary features, allow you to integrate these native dependencies into the .NET Web Assembly runtime statically.
This mean that if you are targeting net 6 in your Blazor Web Assembly application you can include the SQLite native Web Assembly reference and use all the power of a full SQL engine in your SPA application. If you want to learn more about native references here is the link for the official documentation
https://learn.microsoft.com/en-us/aspnet/core/blazor/webassembly-native-dependencies?view=aspnetcore-6.0
Including SQLite native reference in you Blazor Web Assembly project
The first thing that we need to do to use SQLite native reference in a web assembly application is to compile it from the source, you can do that in Linux or WSL
sudo apt-get install cmake default-jre git-core unzip
git clone https://github.com/emscripten-core/emsdk.git
cd emsdk
./emsdk install latest
./emsdk activate latest
source ./emsdk_env.sh
Command to compile SQLite as a web assembly reference
emcc sqlite3.h -shared -o e_sqlite3.o
Now that we have the native reference we need to refence it in the web assembly project
First we need to suppress the warnings we will get by adding native refences, so we need to include this lines in the project
<PropertyGroup>
<!-- The following two are to suppress spurious build warnings from consuming Sqlite. -->
<!--These will become unnecessary when the Sqlite packages contain a dedicated WASM binary. -->
<AllowUnsafeBlocks>true</AllowUnsafeBlocks>
<EmccExtraLDFlags>-s WARN_ON_UNDEFINED_SYMBOLS=0</EmccExtraLDFlags>
</PropertyGroup>
Now we are ready to include the reference
<ItemGroup>
<PackageReference Include="Microsoft.Data.Sqlite" Version="6.0.3" />
<NativeFileReference Include="e_sqlite3.o" />
</ItemGroup>
And voila, now we can use a SQLite database in web assembly
If you want to learn more about native references here are a few links that you might find interesting
Remember in this example we just talked about SQLite native reference but there is a world of native reference to explore, until next time, happy coding ))