
by Joche Ojeda | Oct 5, 2025 | Oqtane, ORM
In this article, I’ll show you what to do after you’ve obtained and opened an Oqtane solution. Specifically, we’ll go through two different ways to set up your database for the first time.
- Using the setup wizard — this option appears automatically the first time you run the application.
- Configuring it manually — by directly editing the
appsettings.json file to skip the wizard.
Both methods achieve the same result. The only difference is that, if you configure the database manually, you won’t see the setup wizard during startup.
Step 1: Running the Application for the First Time
Once your solution is open in Visual Studio, set the Server project as the startup project. Then run it just as you would with any ASP.NET Core application.
You’ll notice several run options — I recommend using the HTTPS version instead of IIS Express (I stopped using IIS Express because it doesn’t work well on ARM-based computers).
When you run the application for the first time and your settings file is still empty, you’ll see the Database Setup Wizard. As shown in the image, the wizard allows you to select a database provider and configure it through a form.
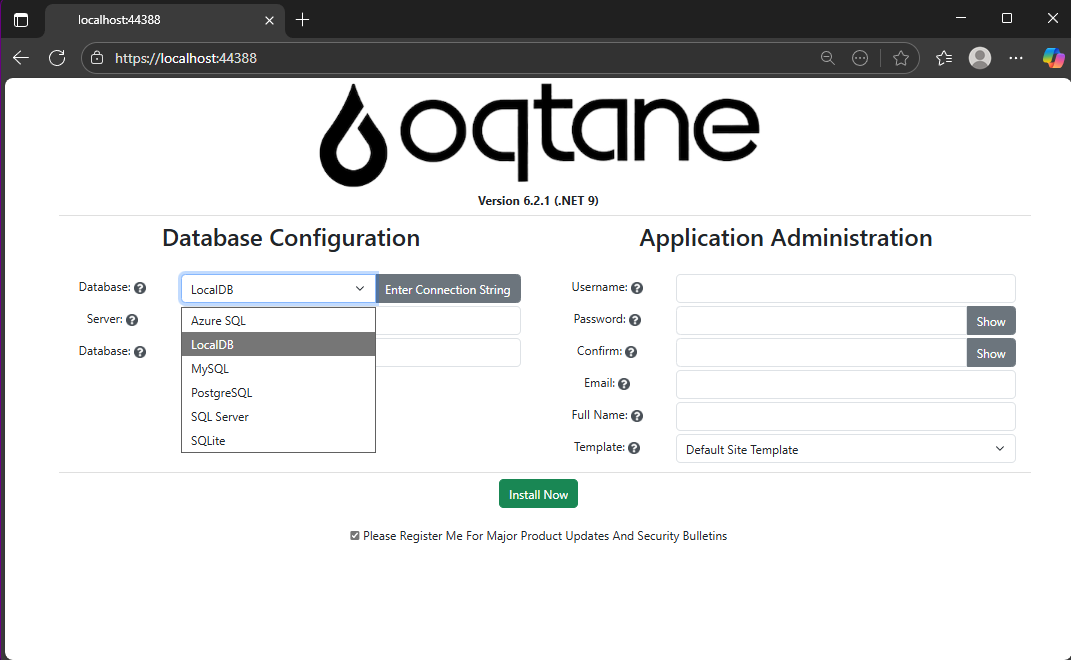
There’s also an option to paste your connection string directly. Make sure it’s a valid Entity Framework Core connection string.
After that, fill in the admin user’s details — username, email, and password — and you’re done. Once this process completes, you’ll have a working Oqtane installation.
Step 2: Setting Up the Database Manually
If you prefer to skip the wizard, you can configure the database manually. To do this, open the appsettings.json file and add the following parameters:
{
"DefaultDBType": "Oqtane.Database.Sqlite.SqliteDatabase, Oqtane.Server",
"ConnectionStrings": {
"DefaultConnection": "Data Source=Oqtane-202510052045.db;"
},
"Installation": {
"DefaultAlias": "https://localhost:44388",
"HostPassword": "MyPasswor25!",
"HostEmail": "joche@myemail.com",
"SiteTemplate": "",
"DefaultTheme": "",
"DefaultContainer": ""
}
}
Here you need to specify:
- The database provider type (e.g., SQLite, SQL Server, PostgreSQL, etc.)
- The connection string
- The admin email and password for the first user — known as the host user (essentially the root or super admin).
This is the method I usually use now since I’ve set up Oqtane so many times recently that I’ve grown tired of the wizard. However, if you’re new to Oqtane, the wizard is a great way to get started.
Wrapping Up
That’s it for this setup guide! By now, you should have a running Oqtane installation configured either through the setup wizard or manually via the configuration file. Both methods give you a solid foundation to start exploring what Oqtane can do.
In the next article, we’ll dive into the Oqtane backend, exploring how the framework handles modules, data, and the underlying architecture that makes it flexible and powerful. Stay tuned — things are about to get interesting!

by Joche Ojeda | Jun 21, 2024 | Database, ORM
Why Compound Keys in Database Tables Are No Longer Valid
Introduction
In the realm of database design, compound keys were once a staple, largely driven by the need to adhere to normalization forms. However, the evolving landscape of technology and data management calls into question the continued relevance of these multi-attribute keys. This article explores the reasons why compound keys may no longer be the best choice and suggests a shift towards simpler, more maintainable alternatives like object identifiers (OIDs).
The Case Against Compound Keys
Complexity in Database Design
- Normalization Overhead: Historically, compound keys were used to satisfy normalization requirements, ensuring minimal redundancy and dependency. While normalization is still important, the rigidity it imposes can lead to overly complex database schemas.
- Business Logic Encapsulation: When compound keys include business logic, they can create dependencies that complicate data integrity and maintenance. Changes in business rules often necessitate schema alterations, which can be cumbersome.
Maintenance Challenges
- Data Integrity Issues: Compound keys can introduce challenges in maintaining data integrity, especially in large and complex databases. Ensuring the uniqueness and consistency of multi-attribute keys can be error-prone.
- Performance Concerns: Queries involving compound keys can become less efficient, as indexing and searching across multiple columns can be more resource-intensive compared to single-column keys.
The Shift Towards Object Identifiers (OIDs)
Simplified Design
- Single Attribute Keys: Using OIDs as primary keys simplifies the schema. Each row can be uniquely identified by a single attribute, making the design more straightforward and easier to understand.
- Decoupling Business Logic: OIDs help in decoupling the business logic from the database schema. Changes in business rules do not necessitate changes in the primary key structure, enhancing flexibility.
Easier Maintenance
- Improved Data Integrity: With a single attribute as the primary key, maintaining data integrity becomes more manageable. The likelihood of key conflicts is reduced, simplifying the validation process.
- Performance Optimization: OIDs allow for more efficient indexing and query performance. Searching and sorting operations are faster and less resource-intensive, improving overall database performance.
Revisiting Normalization
Historical Context
- Storage Constraints: Normalization rules were developed when data storage was expensive and limited. Reducing redundancy and optimizing storage was paramount.
- Modern Storage Solutions: Today, storage is relatively cheap and abundant. The strict adherence to normalization may not be as critical as it once was.
Balancing Act
- De-normalization for Performance: In modern databases, a balance between normalization and de-normalization can be beneficial. De-normalization can improve performance and simplify query design without significantly increasing storage costs.
- Practical Normalization: Applying normalization principles should be driven by practical needs rather than strict adherence to theoretical models. The goal is to achieve a design that is both efficient and maintainable.
ORM Design Preferences
Object-Relational Mappers (ORMs)
- Design with OIDs in Mind: Many ORMs, such as XPO from DevExpress, were originally designed to work with OIDs rather than compound keys. This preference simplifies database interaction and enhances compatibility with object-oriented programming paradigms.
- Support for Compound Keys: Although these ORMs support compound keys, their architecture and default behavior often favor the use of single-column OIDs, highlighting the practical advantages of simpler key structures in modern application development.
Conclusion
The use of compound keys in database tables, driven by the need to fulfill normalization forms, may no longer be the best practice in modern database design. Simplifying schemas with object identifiers can enhance maintainability, improve performance, and decouple business logic from the database structure. As storage becomes less of a constraint, a pragmatic approach to normalization, balancing performance and data integrity, becomes increasingly important. Embracing these changes, along with leveraging ORM tools designed with OIDs in mind, can lead to more robust, flexible, and efficient database systems.

by Joche Ojeda | May 29, 2024 | Database, ORM
In today’s data-driven world, the need for more sophisticated and insightful data models has never been greater. Traditional database models, while powerful, often fall short of delivering the depth and breadth of insights required by modern organizations. Enter the augmented data model, a revolutionary approach that extends beyond the limitations of traditional models by integrating additional data sources, enhanced data features, advanced analytical capabilities, and AI-driven techniques. This blog post explores the key components, applications, and benefits of augmented data models.
Key Components of an Augmented Data Model
1. Integration of Diverse Data Sources
An augmented data model combines structured, semi-structured, and unstructured data from various sources such as databases, data lakes, social media, IoT devices, and external data feeds. This integration enables a holistic view of data across the organization, breaking down silos and fostering a more interconnected understanding of the data landscape.
2. Enhanced Data Features
Beyond raw data, augmented data models include derived attributes, calculated fields, and metadata to enrich the data. Machine learning and artificial intelligence are employed to create predictive and prescriptive data features, transforming raw data into actionable insights.
3. Advanced Analytics
Augmented data models incorporate advanced analytical models, including machine learning, statistical models, and data mining techniques. These models support real-time analytics and streaming data processing, enabling organizations to make faster, data-driven decisions.
4. AI-Driven Embeddings
One of the standout features of augmented data models is the creation of embeddings. These are dense vector representations of data (such as words, images, or user behaviors) that capture their semantic meaning. Embeddings enhance machine learning models, making them more effective at tasks such as recommendation, natural language processing, and image recognition.
5. Data Visualization and Reporting
To make complex data insights accessible, augmented data models facilitate advanced data visualization tools and dashboards. These tools allow users to interact with data dynamically through self-service analytics platforms, turning data into easily digestible visual stories.
6. Improved Data Quality and Governance
Ensuring data quality is paramount in augmented data models. Automated data cleansing, validation, and enrichment processes maintain high standards of data quality. Robust data governance policies manage data lineage, security, and compliance, ensuring that data is trustworthy and reliable.
7. Scalability and Performance
Designed to handle large volumes of data, augmented data models scale horizontally across distributed systems. They are optimized for high performance in data processing and querying, ensuring that insights are delivered swiftly and efficiently.
Applications and Benefits
Enhanced Decision Making
With deeper insights and predictive capabilities, augmented data models significantly improve decision-making processes. Organizations can move from reactive to proactive strategies, leveraging data to anticipate trends and identify opportunities.
Operational Efficiency
By streamlining data processing and integration, augmented data models reduce manual efforts and errors. This leads to more efficient operations and a greater focus on strategic initiatives.
Customer Insights
Augmented data models enable a 360-degree view of customers by integrating various touchpoints and interactions. This comprehensive view allows for more personalized and effective customer engagement strategies.
Innovation
Supporting advanced analytics and machine learning initiatives, augmented data models foster innovation within the organization. They provide the tools and insights needed to develop new products, services, and business models.
Real-World Examples
Customer 360 Platforms
By combining CRM data, social media interactions, and transactional data, augmented data models create a comprehensive view of customer behavior. This holistic approach enables personalized marketing and improved customer service.
IoT Analytics
Integrating sensor data, machine logs, and external environmental data, augmented data models optimize operations in manufacturing or smart cities. They enable real-time monitoring and predictive maintenance, reducing downtime and increasing efficiency.
Fraud Detection Systems
Using transactional data, user behavior analytics, and external threat intelligence, augmented data models detect and prevent fraudulent activities. Advanced machine learning models identify patterns and anomalies indicative of fraud, providing a proactive defense mechanism.
AI-Powered Recommendations
Embeddings created from user interactions, product descriptions, and historical purchase data power personalized recommendations in e-commerce. These AI-driven insights enhance customer experience and drive sales.
Conclusion
Augmented data models represent a significant advancement in the way organizations handle and analyze data. By leveraging modern technologies and methodologies, including the creation of embeddings for AI, these models provide a more comprehensive and actionable view of the data. The result is enhanced decision-making, improved operational efficiency, deeper customer insights, and a platform for innovation. As organizations continue to navigate the complexities of the data landscape, augmented data models will undoubtedly play a pivotal role in shaping the future of data analytics.

by Joche Ojeda | May 26, 2023 | ADO, ADO.NET, ORM
ORM is a technique for converting data between incompatible type systems using object-oriented programming languages. In the context of database management, an ORM provides a way to interact with a database using objects and methods, rather than writing raw SQL queries. This allows for a higher level of abstraction, reducing the amount of repetitive and error-prone code that needs to be written, and making it easier to maintain the application.
ORM and RDBMS
Object-Relational Mapping (ORM) tools and RDBMS have different approaches to querying data.
RDBMS uses SQL which is a low-level, language-agnostic query language that is used to communicate with relational databases. When using SQL, developers write raw SQL statements that are executed directly against the database. The results of the query are then returned in the form of a table or set of tables, which must be manually mapped to objects in code.
On the other hand, an ORM tool abstracts the underlying SQL code, allowing developers to query data using an object-oriented syntax that is similar to the programming language used in the application.
The ORM tool automatically generates the necessary SQL statements and executes them against the database, and then maps the resulting data to objects in code.
One of the main advantages of using an ORM tool is that it eliminates the need for manual data mapping, making it easier for developers to write data-access code and reducing the chances of errors. Additionally, because ORM tools use a higher-level syntax, they can also be more intuitive and easier to use than raw SQL.
However, ORM tools can also introduce performance overhead and complexity, as they must manage the mapping between the database and objects in code. In some cases, raw SQL may still be necessary to achieve the desired performance or to perform complex data manipulation that is not supported by the ORM tool.
As a simple example we will use the database table “customer”. It has four columns:
- id: A unique identifier for each customer, usually an auto-incrementing integer.
- name: The name of the customer, represented as a string.
- email: The email address of the customer, represented as a string.
- address: The address of the customer, represented as a string.
Each row in the table represents a single customer, and each column represents a piece of information about that customer. The table is used to store the data for the customer objects created in the code. The ORM maps the table to a class, allowing you to interact with the data using objects and methods.
Here is an example of how an ORM can map a database table named “customer” to a class representation in C#:
class Customer
{
public int Id { get; set; }
public string Name { get; set; }
public string Email { get; set; }
public string Address { get; set; }
}
// The ORM maps the customer table in the database to the Customer class.
// The columns of the table become properties of the class, and each row in the table becomes an instance of the class.
In this example, the ORM abstracts away the underlying database and provides a high-level, object-oriented interface for working with the data.
The main advantage of using an ORM (Object-Relational Mapping) instead of using the direct results from the database in C# is increased abstraction and convenience. This provides several benefits:
- Improved readability and maintainability: Code written using an ORM is easier to understand and maintain, as it uses a higher-level, object-oriented interface, rather than raw SQL.
- Reduced code duplication: With an ORM, you can encapsulate database-related logic in reusable classes and methods, reducing the amount of repetitive code that needs to be written.
- Increased safety: An ORM can help prevent SQL injection attacks by automatically escaping user input, ensuring that data is safely inserted into the database.
- Increased flexibility: An ORM provides a layer of abstraction between the application code and the database, allowing you to switch between different database systems without changing the application code.
Direct database access
var connection = new SqlConnection("connection string");
connection. Open();
var command = new SqlCommand("SELECT * FROM customers", connection);
var reader = command.ExecuteReader();
List < Customer > customers = new List < Customer > ();
while (reader. Read()) {
var customer = new Customer {
Id = reader.GetInt32(0),
Name = reader.GetString(1),
Email = reader.GetString(2),
Address = reader.GetString(3)
};
customers. Add(customer);
}
reader.Close();
connection. Close();
ORM access
var customers = ORM.Query<Customer>().ToList();
As you can see, using an ORM simplifies the code and makes it more readable, while also providing additional safety and flexibility benefits.
Different types of O.R.M
Micro O.R.M
A micro ORM is a type of Object-Relational Mapping (ORM) library that is designed to be lightweight and simple, offering a minimalistic and easy-to-use interface for interacting with a relational database.
Micro ORMs are typically faster and require less configuration and setup than full-featured ORMs, but also have fewer features and less advanced capabilities.
Micro ORMs provide a higher-level, object-oriented interface for working with databases, allowing you to interact with the data using classes, properties, and methods, rather than writing raw SQL queries as well but they typically offer a smaller, more focused set of features than full-featured ORMs, including support for basic CRUD (Create, Read, Update, Delete) operations, and often provide basic querying and data mapping capabilities.
Micro ORMs are often used in small projects or in environments where performance is critical. They are also commonly used in microservices and other architectures that prioritize simplicity, scalability, and ease of deployment.
Full-fledged Object-Relational Mapping (ORM)
A full-fledged Object-Relational Mapping (ORM) is a software library that provides a convenient and efficient way of working with relational databases.
A full-fledged ORM typically has the following characteristics:
- Object Mapping: The ORM maps database tables to object-oriented classes, allowing developers to interact with the database using objects instead of tables.
- Query Generation: The ORM generates SQL statements based on the object-oriented query syntax, reducing the need for developers to write and manage raw SQL.
- Data Validation: The ORM provides built-in data validation and type checking, reducing the risk of incorrect data being written to the database.
- Caching: The ORM may provide caching of data to improve performance, reducing the number of databases round trips.
- Transactions: The ORM supports transactions, making it easier to ensure that database operations are atomic and consistent.
- Database Independence: The ORM is typically designed to be database agnostic, allowing developers to switch between different database platforms without changing the application code.
- Lazy Loading: The ORM supports lazy loading, which can improve performance by loading related objects only when they are needed.
- Performance: A comprehensive ORM is crafted to deliver satisfactory performance, and we can customize each aspect of the ORM to enhance its performance. However, it is important to note that a solid understanding of how the ORM operates is necessary to make these customizations effective.
One of the disadvantages of using an Object-Relational Mapping (ORM) tool is that you may not be able to create specialized, fine-tuned queries with the same level of precision as you can with raw SQL. This is because ORMs typically abstract the underlying database and expose a higher-level, more object-oriented API for querying data.
For example, it may not be possible to use specific SQL constructs, such as subqueries or window functions, in your ORM queries. Additionally, some ORMs may not provide a way to optimize query performance, such as by specifying index hints or controlling the execution plan.
As a result, developers who need to write specialized or fine-tuned queries may find it easier and more efficient to write raw SQL statements. However, this comes at the cost of having to manually manage the mapping between the database and the application, which is one of the main benefits of using an ORM in the first place.
ORM and Querying data
Before the existence of LINQ, Object-Relational Mapping (ORM) tools used a proprietary query language to query data. This meant that each ORM had to invent its own criteria or query language, and developers had to learn the specific syntax of each ORM in order to write queries.
For example, in XPO, developers used the Criteria API to write queries. The Criteria API allowed developers to write queries in a type-safe and intuitive manner, but the syntax was specific to XPO and not easily transferable to other ORMs.
Similarly, in NHibernate, developers used the Hibernate Query Language (HQL) to write queries. Like the Criteria API in XPO, HQL was a proprietary query language specific to NHibernate, and developers had to learn the syntax in order to write queries.
This lack of a standardized query language was one of the main limitations of ORMs before the introduction of LINQ. LINQ provided a common, language-agnostic query language that could be used with a variety of data sources, including relational databases. This made it easier for developers to write data-access code, as they only had to learn one query language, regardless of the ORM or data source being used.
The introduction of LINQ, a new era for O.R.M in dot net
Language Integrated Query (LINQ) is a Microsoft .NET Framework component that was introduced in .NET Framework 3.5. It is a set of language and library features that enables developers to write querying and manipulation operations over data in a more intuitive and readable way.
LINQ was created to address the need for a more unified and flexible approach to querying and manipulating data in .NET applications. Prior to LINQ, developers had to write separate code to access and manipulate data in different data sources, such as databases, XML documents, and in-memory collections. This resulted in a fragmented and difficult-to-maintain codebase, with different syntax and approaches for different data sources.
With LINQ, developers can now write a single querying language that works with a wide range of data sources, including databases, XML, in-memory collections, and more.
In addition, LINQ also provides a number of other benefits, such as improved performance, better type safety, and integrated support for data processing operations, such as filtering, grouping, and aggregating.
using (var context = new DbContext())
{
var selectedCustomers = context.Customers
.Where(c => c.Address.Contains("San Salvador"))
.Select(c => new
{
c.Id,
c.Name,
c.Email,
c.Address
})
.ToList();
foreach(var customer in selectedCustomers)
foreach(var customer in selectedCustomers)
{
Console.WriteLine($"Id: {customer.Id}, Name: {customer.Name}, Email: {customer.Email}, Address: {customer. Address}");
}
}
And that’s all for this post, until next time ))
We are excited to announce that we are currently in the process of writing a comprehensive book about DevExpress XPO. As we work on this project, we believe it is essential to involve our readers and gather their valuable feedback. Therefore, we have decided to share articles from the book as we complete them, giving you an opportunity to provide input and suggestions that we can consider for inclusion in the final release. Keep in mind that the content presented is subject to change. We greatly appreciate your participation in this collaborative effort.
Related Articles
ADO The origin of data access in .NET
Relational database systems: the holy grail of data
