
by Joche Ojeda | Mar 13, 2025 | netcore, Uno Platform
For the past two weeks, I’ve been experimenting with the Uno Platform in two ways: creating small prototypes to explore features I’m curious about and downloading example applications from the Uno Gallery. In this article, I’ll explain the first steps you need to take when creating an Uno Platform application, the decisions you’ll face, and what I’ve found useful so far in my journey.
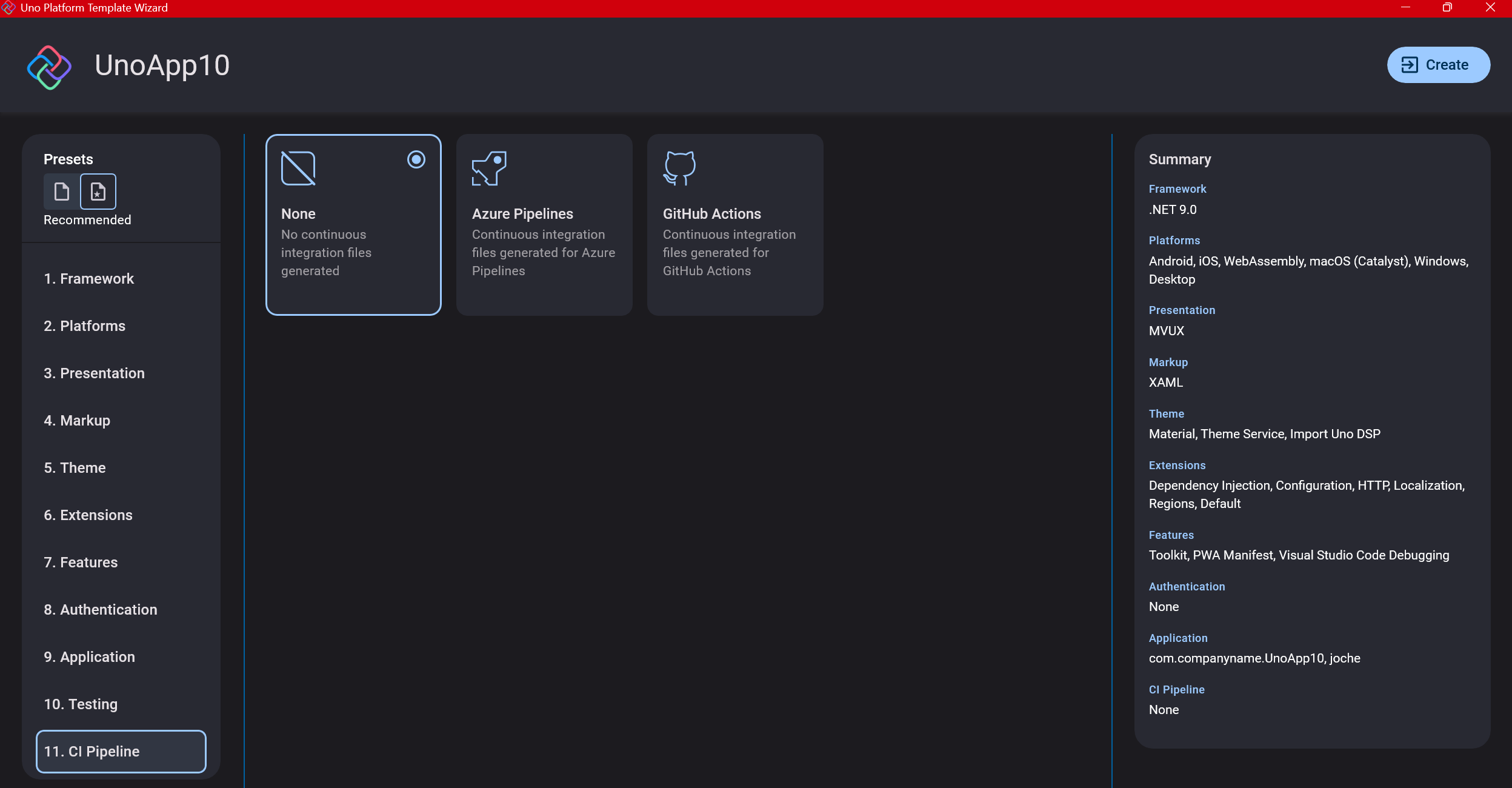
Step 1: Create a New Project
I’m using Visual Studio 2022, though the extensions and templates work well with previous versions too. I have both studio versions installed, and Uno Platform works well in both.
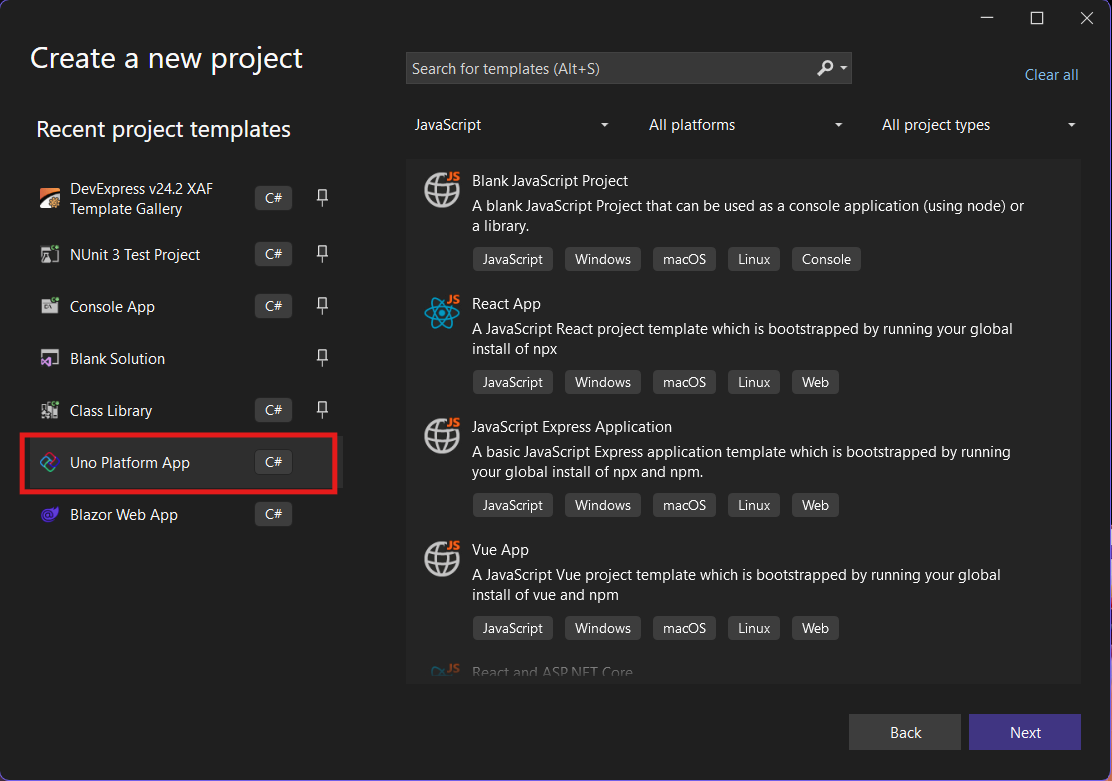
Step 2: Project Setup
After naming your project, it’s important to select “Place solution and project in the same directory” because of the solution layout requirements. You need the directory properties file to move forward. I’ll talk more about the solution structure in a future post, but for now, know that without checking this option, you won’t be able to proceed properly.
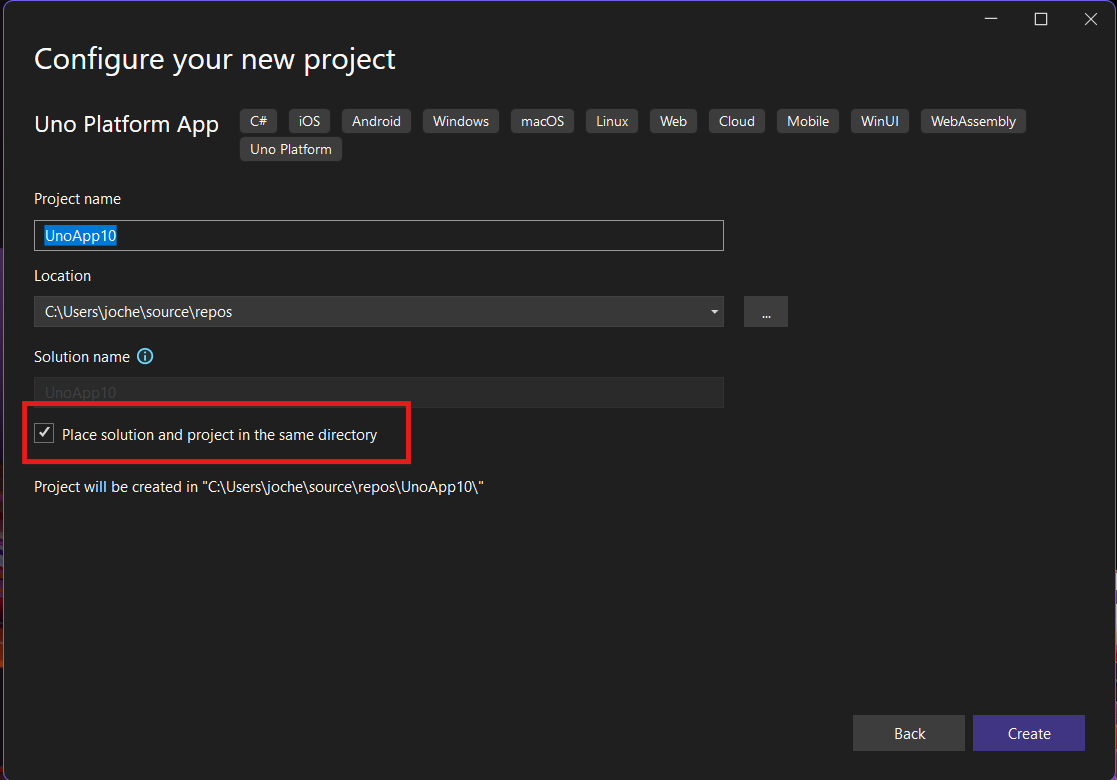
Step 3: The Configuration Wizard
The Uno Platform team has created a comprehensive wizard that guides you through various configuration options. It might seem overwhelming at first, but it’s better to have this guided approach where you can make one decision at a time.
Your first decision is which target framework to use. They recommend .NET 9, which I like, but in my test project, I’m working with .NET 8 because I’m primarily focused on WebAssembly output. Uno offers multi-threading in Web Assembly with .NET 8, which is why I chose it, but for new projects, .NET 9 is likely the better choice.
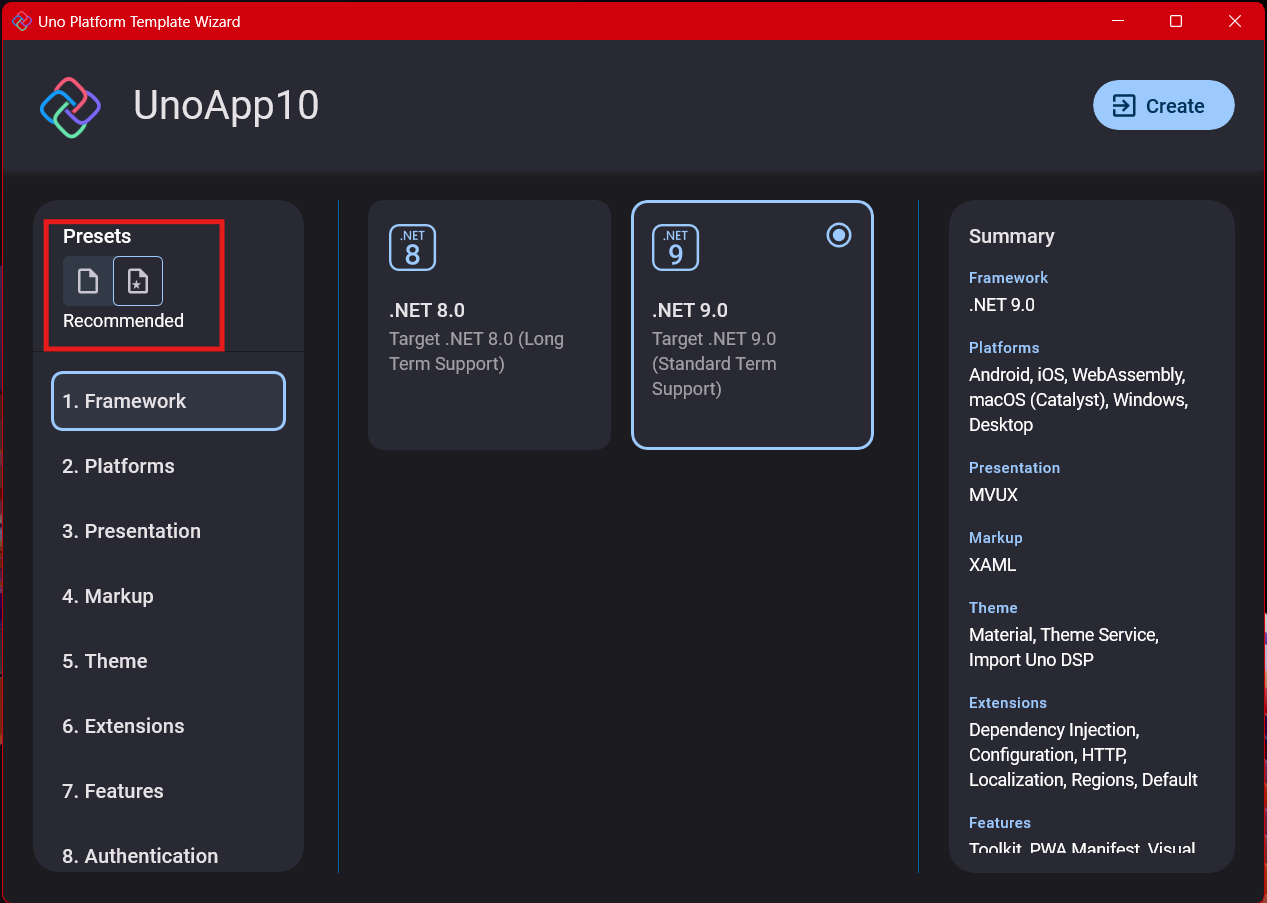
Step 4: Target Platforms
Next, you need to select which platforms you want to target. I always select all of them because the most beautiful aspect of the Uno Platform is true multi-targeting with a single codebase.
In the past (during the Xamarin era), you needed multiple projects with a complex directory structure. With Uno, it’s actually a single unified project, creating a clean solution layout. So while you can select just WebAssembly if that’s your only focus, I think you get the most out of Uno by multi-targeting.
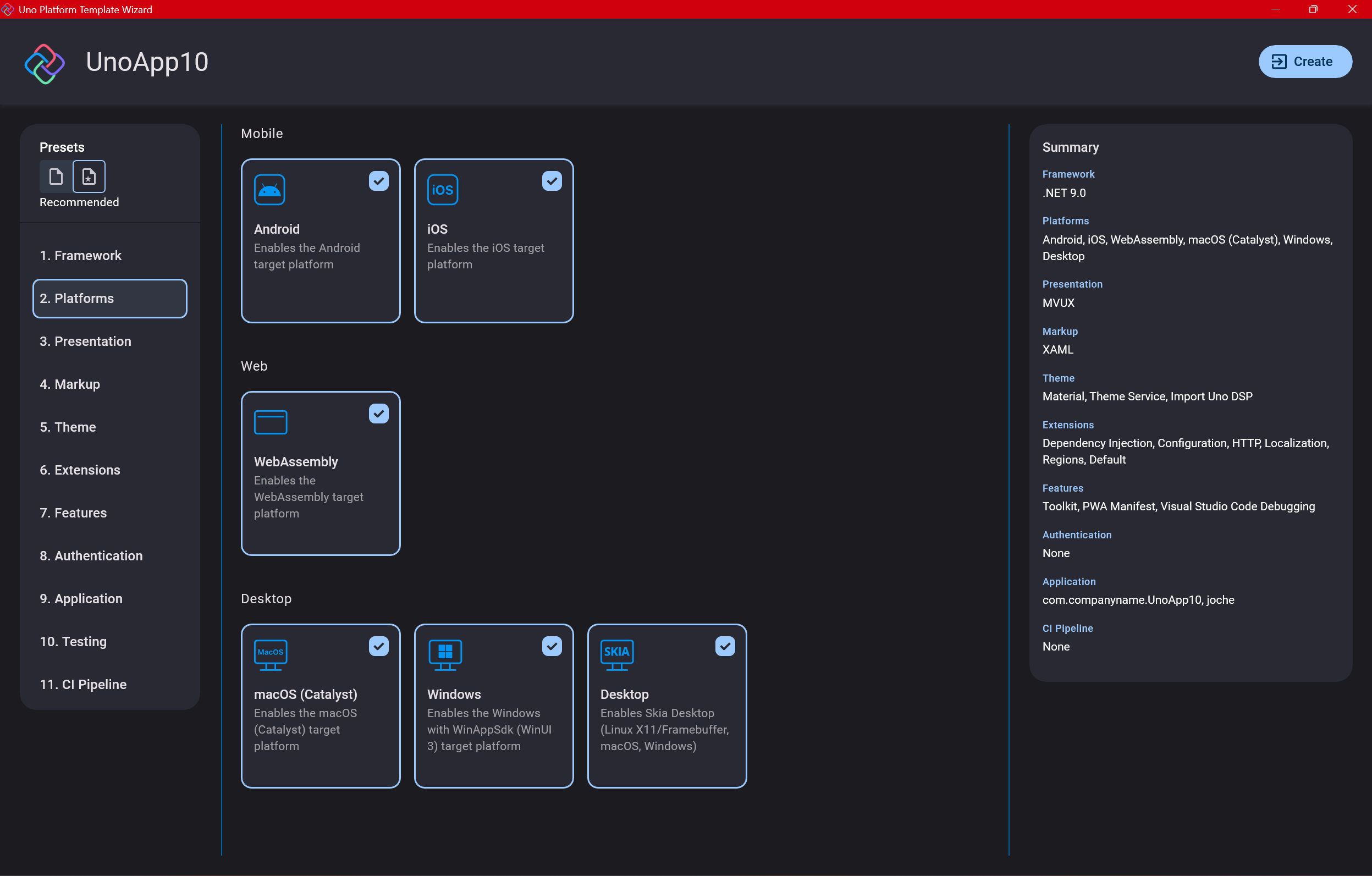
Step 5: Presentation Pattern
The next question is which presentation pattern you want to use. I would suggest MVUX, though I still have some doubts as I haven’t tried MVVM with Uno yet. MVVM is the more common pattern that most programmers understand, while MVUX is the new approach.
One challenge is that when you check the official Uno sample repository, the examples come in every presentation pattern flavor. Sometimes you’ll find a solution for your task in one pattern but not another, so you may need to translate between them. You’ll likely find more examples using MVVM.
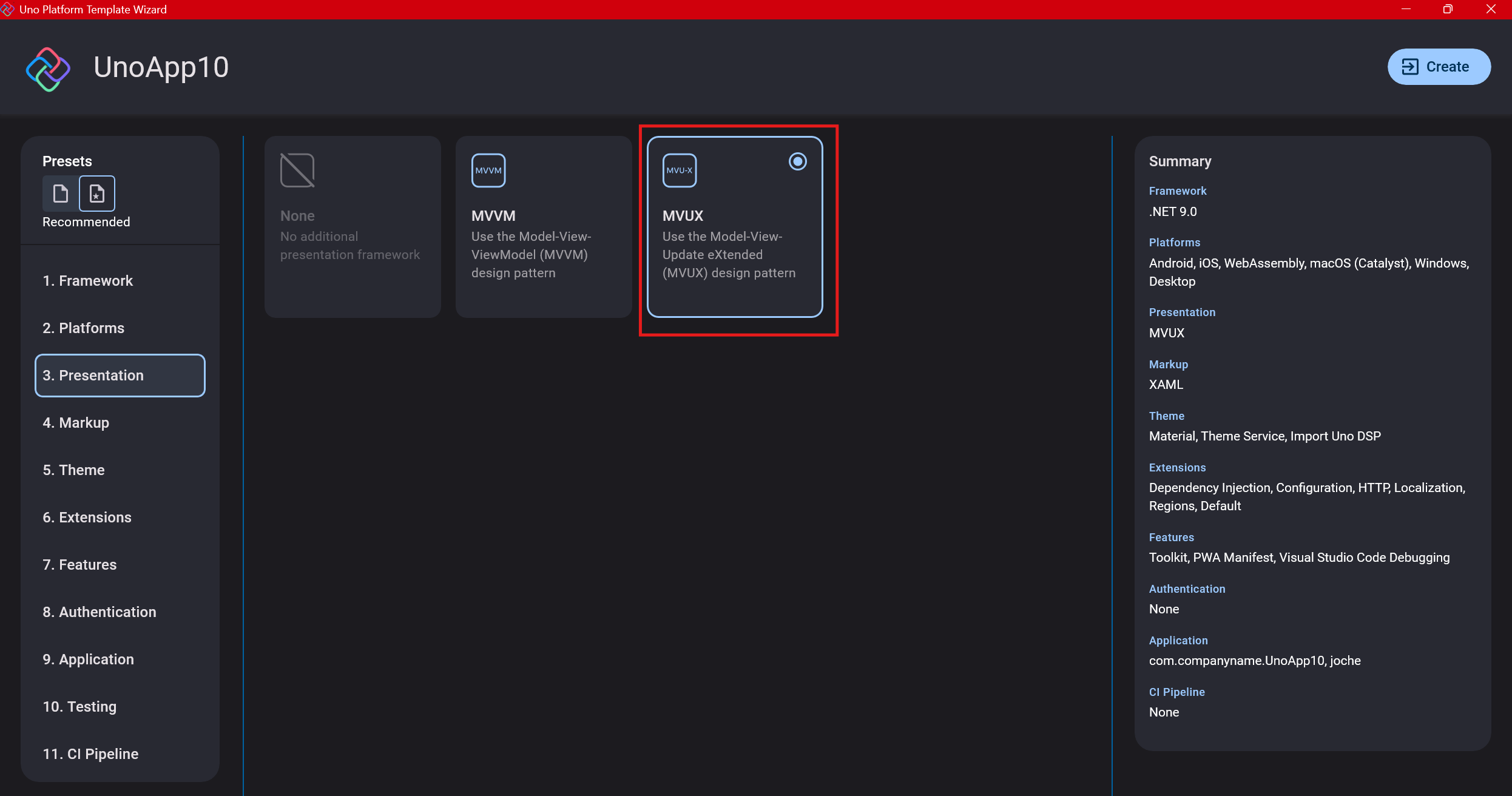
Step 6: Markup Language
For markup, I recommend selecting XAML. In my first project, I tried using C# markup, which worked well until I reached some roadblocks I couldn’t overcome. I didn’t want to get stuck trying to solve one specific layout issue, so I switched. For beginners, I suggest starting with XAML.
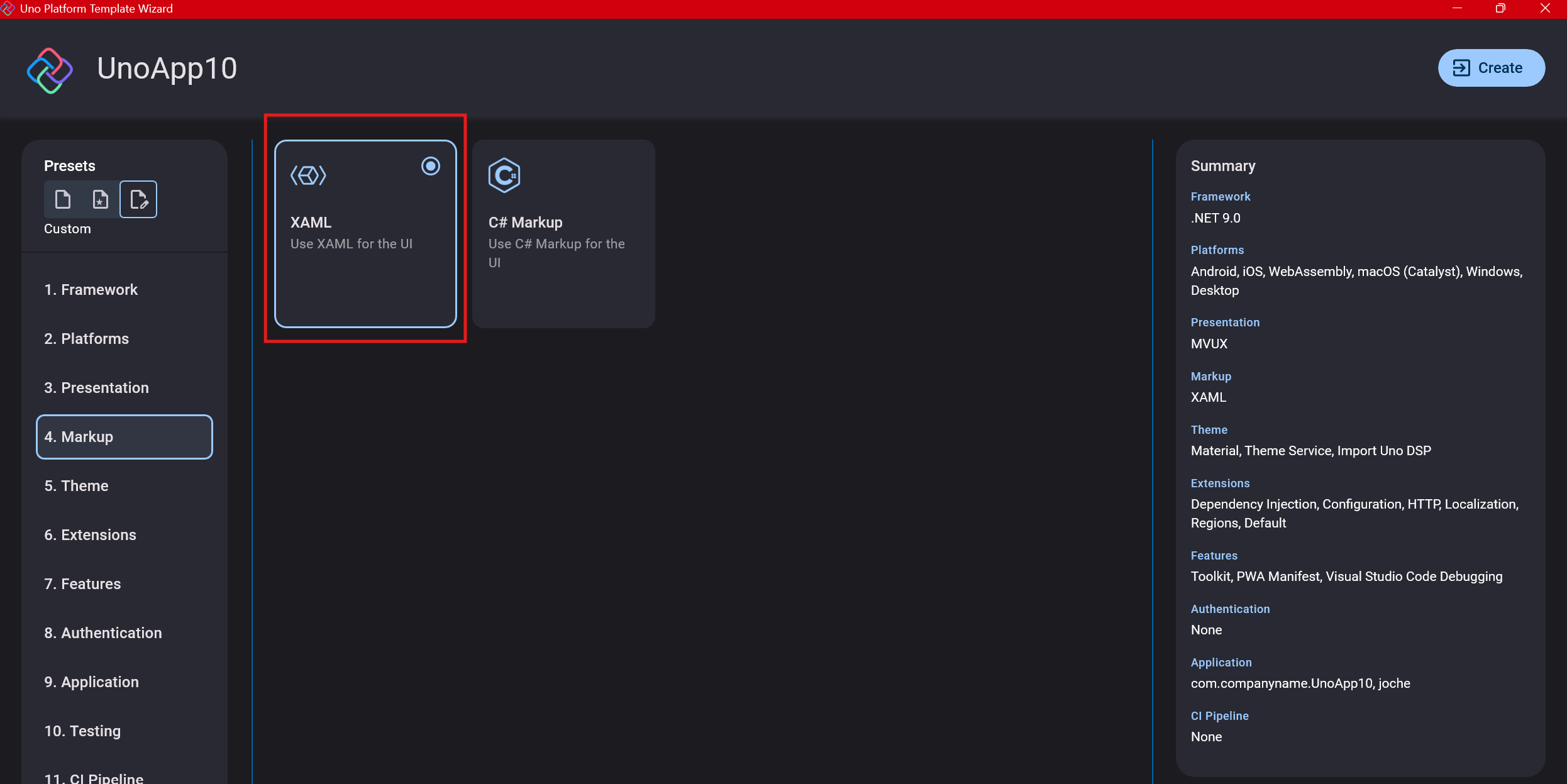
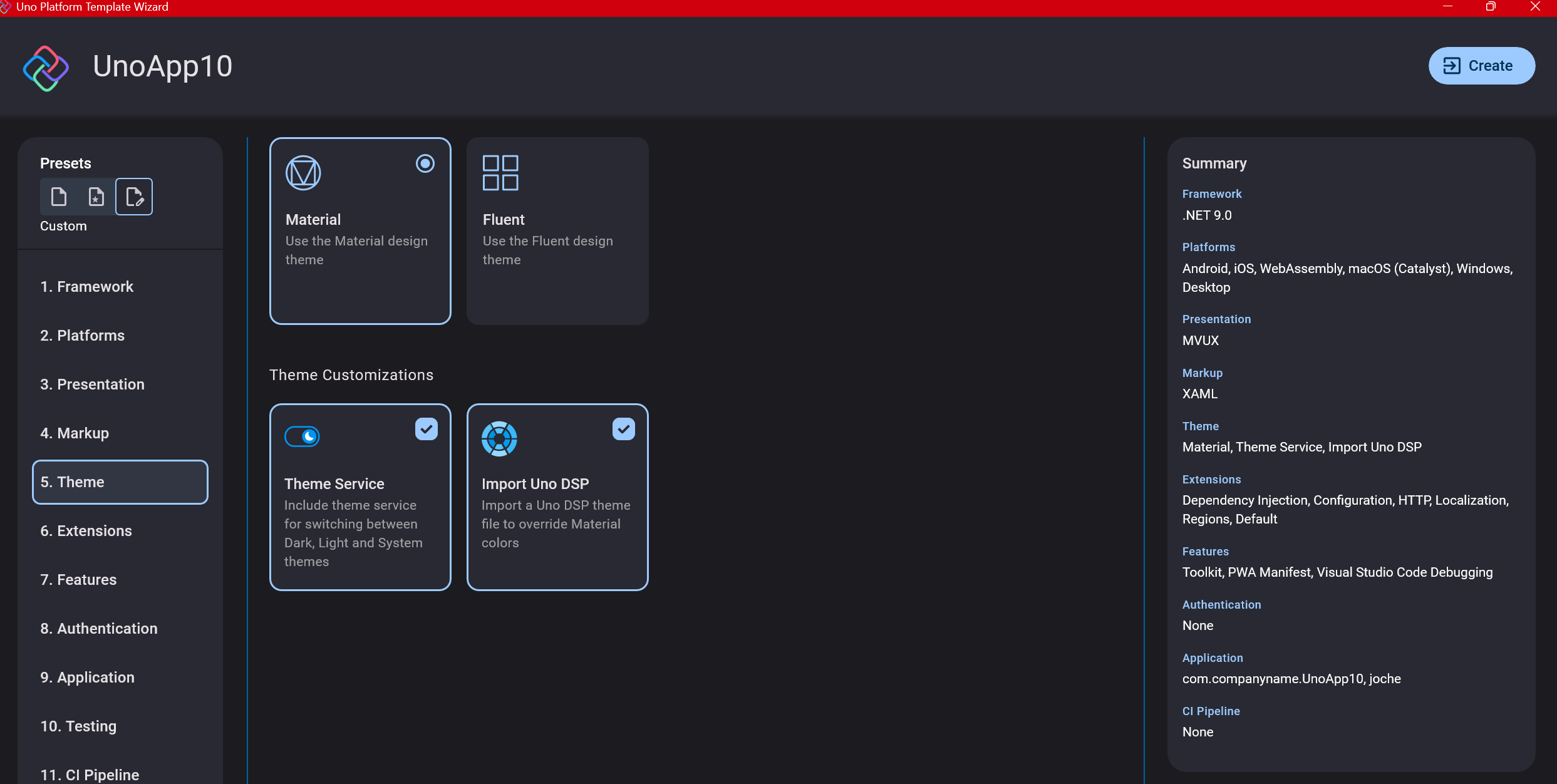
Step 7: Theming
For theming, you’ll need to select a UI theme. I don’t have a strong preference here and typically stick with the defaults: using Material Design, the theme service, and importing Uno DSP.
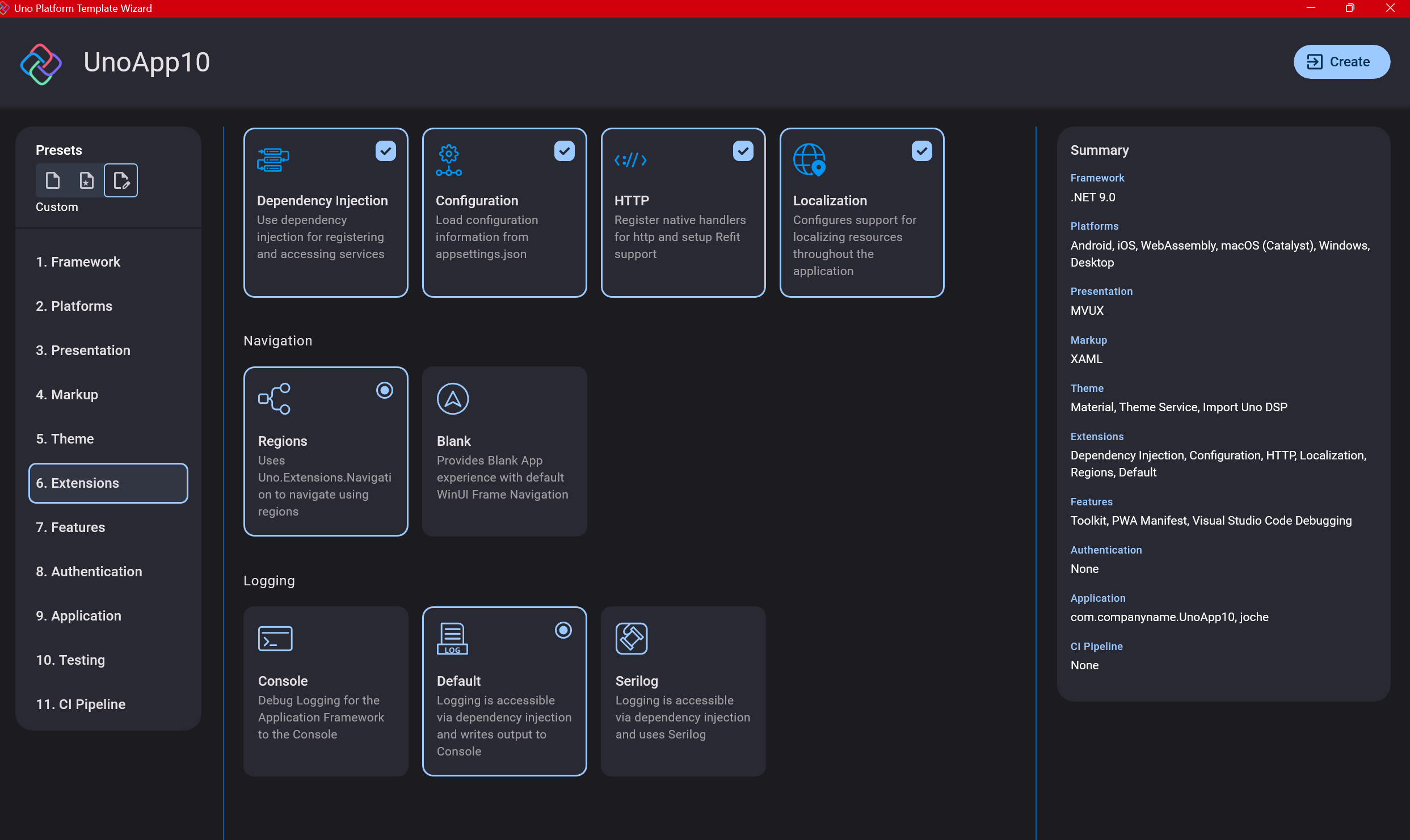
Step 8: Extensions
When selecting extensions to include, I recommend choosing almost all of them as they’re useful for modern application development. The only thing you might want to customize is the logging type (Console, Debug, or Serilog), depending on your previous experience. Generally, most applications will benefit from all the extensions offered.
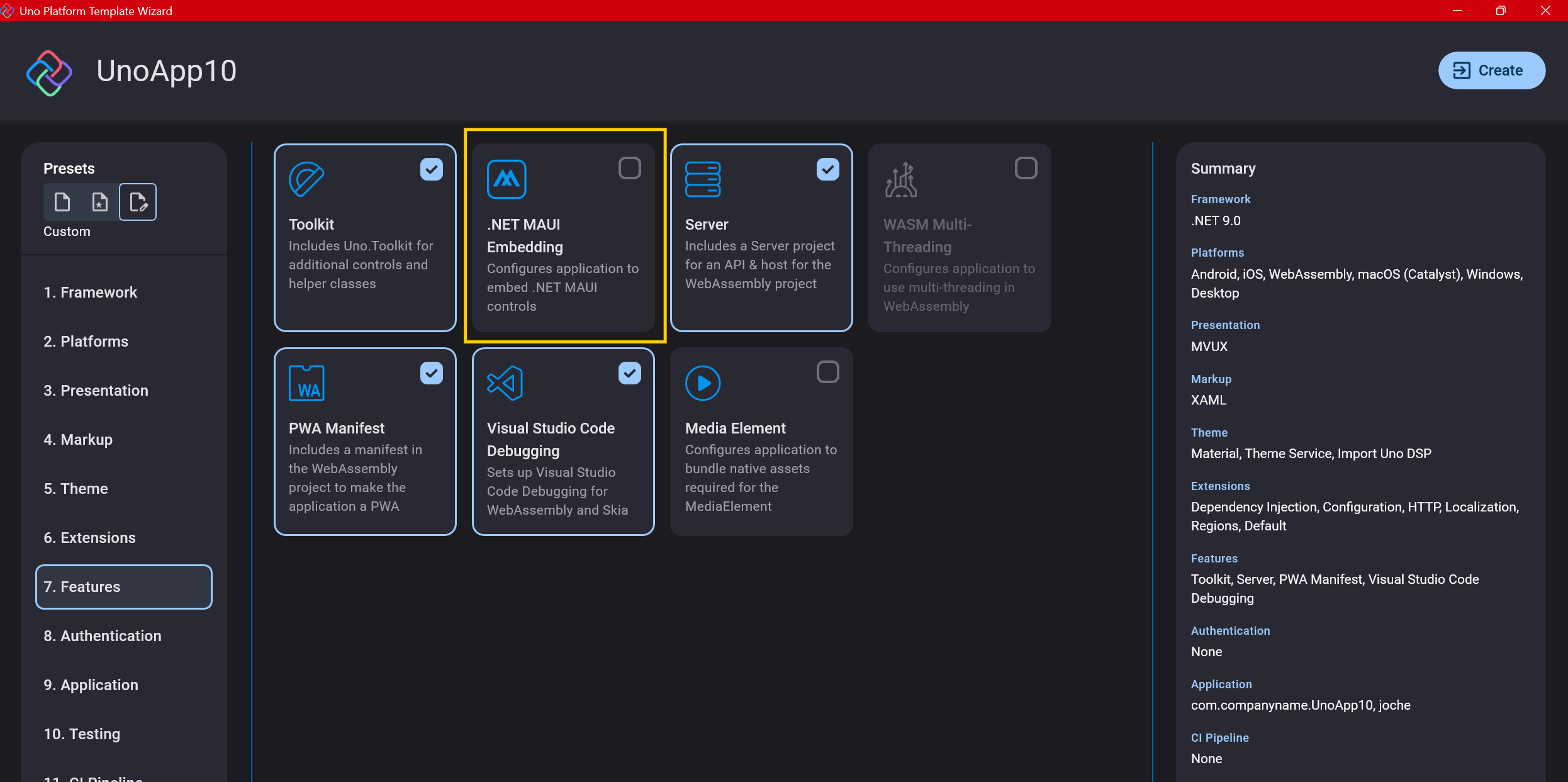
Step 9: Features
Next, you’ll select which features to include in your application. For my tests, I include everything except the MAUI embedding and the media element. Most features can be useful, and I’ll show in a future post how to set them up when discussing the solution structure.
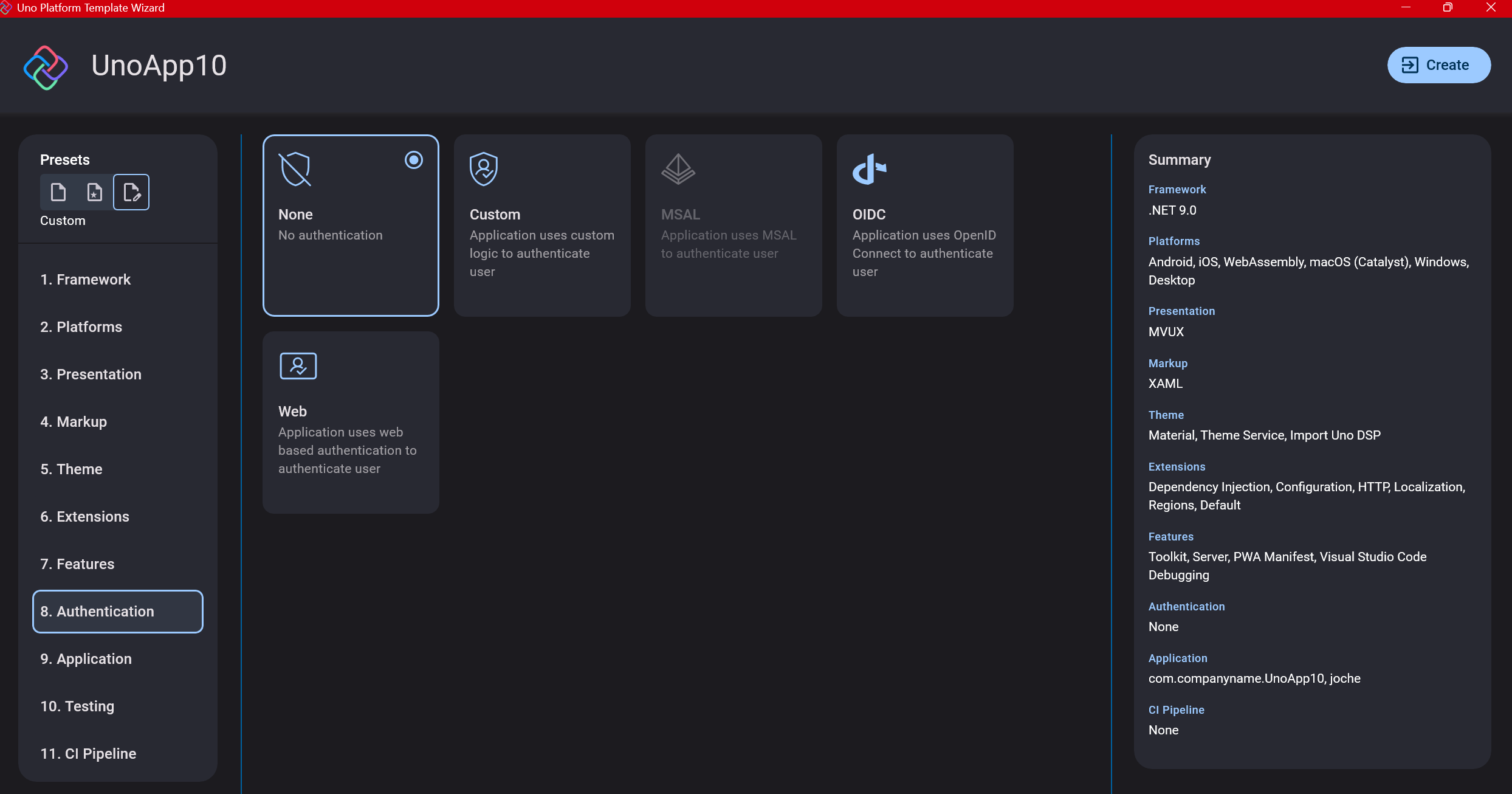
Step 10: Authentication
You can select “None” for authentication if you’re building test projects, but I chose “Custom” because I wanted to see how it works. In my case, I’m authenticating against DevExpress XAF REST API, but I’m also interested in connecting my test project to Azure B2C.
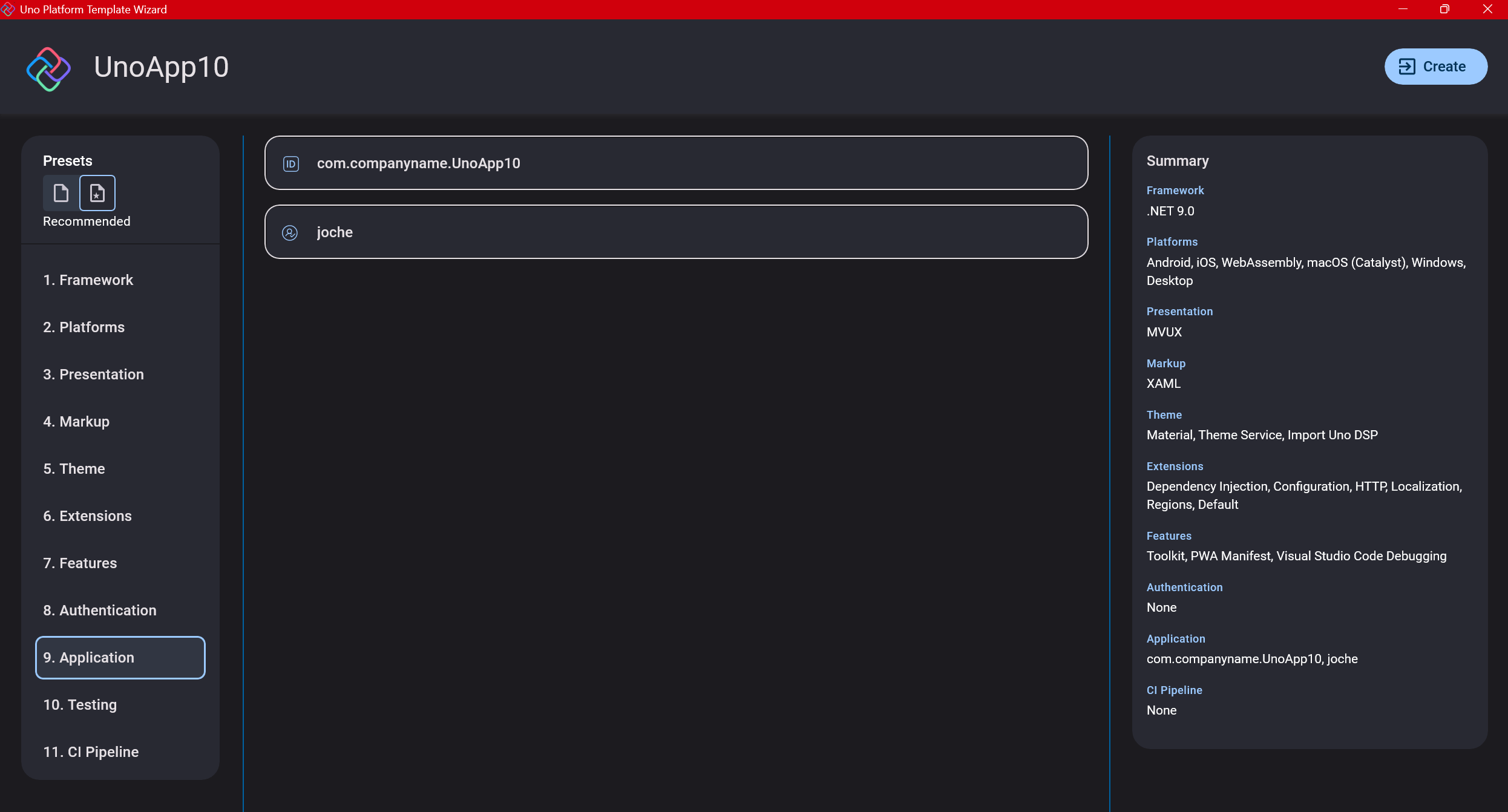
Step 11: Application ID
Next, you’ll need to provide an application ID. While I haven’t fully explored the purpose of this ID yet, I believe it’s needed when publishing applications to app stores like Google Play and the Apple App Store.
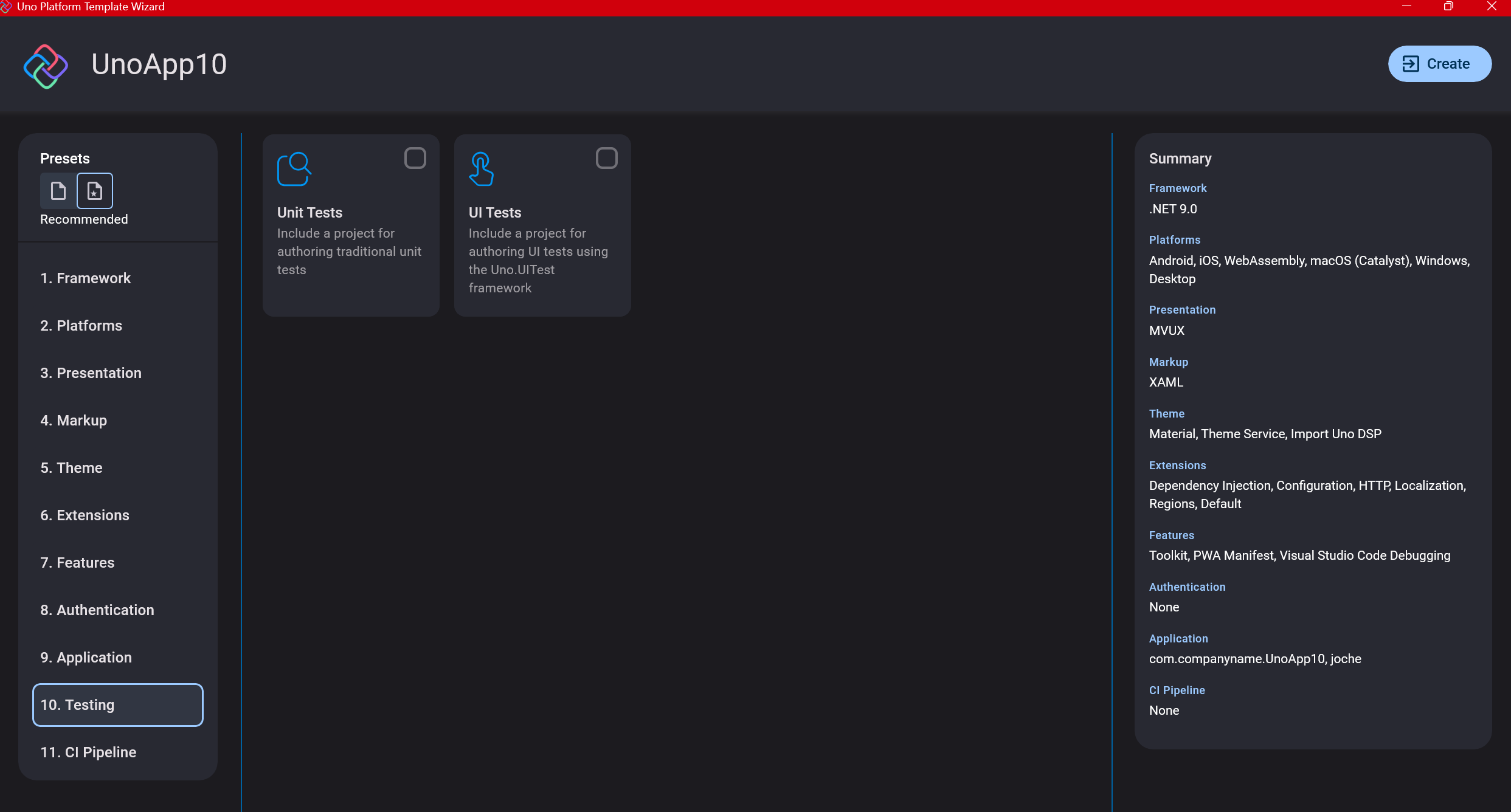
Step 12: Testing
I’m a big fan of testing, particularly integration tests. While unit tests are essential when developing components, for business applications, integration tests that verify the flow are often sufficient.
Uno also offers UI testing capabilities, which I haven’t tried yet but am looking forward to exploring. In platform UI development, there aren’t many choices for UI testing, so having something built-in is fantastic.
Testing might seem like a waste of time initially, but once you have tests in place, you’ll save time in the future. With each iteration or new release, you can run all your tests to ensure everything works correctly. The time invested in creating tests upfront pays off during maintenance and updates.
Step 13: CI Pipelines
The final step is about CI pipelines. If you’re building a test application, you don’t need to select anything. For production applications, you can choose Azure Pipelines or GitHub Actions based on your preferences. In my case, I’m not involved with CI pipeline configuration at my workplace, so I have limited experience in this area.
Conclusion
If you’ve made it this far, congratulations! You should now have a shiny new Uno Platform application in your IDE.
This post only covers the initial setup choices when creating a new Uno application. Your development path will differ based on the selections you’ve made, which can significantly impact how you write your code. Choose wisely and experiment with different combinations to see what works best for your needs.
During my learning journey with the Uno Platform, I’ve tried various settings—some worked well, others didn’t, but most will function if you understand what you’re doing. I’m still learning and taking a hands-on approach, relying on trial and error, occasional documentation checks, and GitHub Copilot assistance.
Thanks for reading and see you in the next post!
About Us
YouTube
https://www.youtube.com/c/JocheOjedaXAFXAMARINC
Our sites
Let’s discuss your XAF
https://www.udemy.com/course/microsoft-ai-extensions/
Our free A.I courses on Udemy
by Joche Ojeda | Mar 12, 2025 | dotnet, http, netcore, netframework, network, WebServers
Last week, I was diving into Uno Platform to understand its UI paradigms. What particularly caught my attention is Uno’s ability to render a webapp using WebAssembly (WASM). Having worked with WASM apps before, I’m all too familiar with the challenges of connecting to data sources and handling persistence within these applications.
My Previous WASM Struggles
About a year ago, I faced a significant challenge: connecting a desktop WebAssembly app to an old WCF webservice. Despite having the CORS settings correctly configured (or so I thought), I simply couldn’t establish a connection from the WASM app to the server. I spent days troubleshooting both the WCF service and another ASMX service, but both attempts failed. Eventually, I had to resort to webserver proxies to achieve my goal.
This experience left me somewhat traumatized by the mere mention of “connecting WASM with an API.” However, the time came to face this challenge again during my weekend experiments.
A Pleasant Surprise with Uno Platform
This weekend, I wanted to connect a XAF REST API to an Uno Platform client. To my surprise, it turned out to be incredibly straightforward. I successfully performed this procedure twice: once with a XAF REST API and once with the API included in the Uno app template. The ease of this integration was a refreshing change from my previous struggles.
Understanding CORS and Why It Matters for WASM Apps
To understand why my previous attempts failed and my recent ones succeeded, it’s important to grasp what CORS is and why it’s crucial for WebAssembly applications.
What is CORS?
CORS (Cross-Origin Resource Sharing) is a security feature implemented by web browsers that restricts web pages from making requests to a domain different from the one that served the original web page. It’s an HTTP-header based mechanism that allows a server to indicate which origins (domains, schemes, or ports) other than its own are permitted to load resources.
The Same-Origin Policy
Browsers enforce a security restriction called the “same-origin policy” which prevents a website from one origin from requesting resources from another origin. An origin consists of:
- Protocol (HTTP, HTTPS)
- Domain name
- Port number
For example, if your website is hosted at https://myapp.com, it cannot make AJAX requests to https://myapi.com without the server explicitly allowing it through CORS.
Why CORS is Required for Blazor WebAssembly
Blazor WebAssembly (which uses similar principles to Uno Platform’s WASM implementation) is fundamentally different from Blazor Server in how it operates:
- Separate Deployment: Blazor WebAssembly apps are fully downloaded to the client’s browser and run entirely in the browser using WebAssembly. They’re typically hosted on a different server or domain than your API.
- Client-Side Execution: Since all code runs in the browser, when your Blazor WebAssembly app makes HTTP requests to your API, they’re treated as cross-origin requests if the API is hosted on a different domain, port, or protocol.
- Browser Security: Modern browsers block these cross-origin requests by default unless the server (your API) explicitly permits them via CORS headers.
Implementing CORS in Startup.cs
The solution to these CORS issues lies in properly configuring your server. In your Startup.cs file, you can configure CORS as follows:
public void ConfigureServices(IServiceCollection services) {
services.AddCors(options => {
options.AddPolicy("AllowBlazorApp",
builder => {
builder.WithOrigins("https://localhost:5000") // Replace with your Blazor app's URL
.AllowAnyHeader()
.AllowAnyMethod();
});
});
// Other service configurations...
}
public void Configure(IApplicationBuilder app, IWebHostEnvironment env) {
// Other middleware configurations...
app.UseCors("AllowBlazorApp");
// Other middleware configurations...
}
Conclusion
My journey with connecting WebAssembly applications to APIs has had its ups and downs. What once seemed like an insurmountable challenge has now become much more manageable, especially with platforms like Uno that simplify the process. Understanding CORS and implementing it correctly is crucial for successful WASM-to-API communication.
If you’re working with WebAssembly applications and facing similar challenges, I hope my experience helps you avoid some of the pitfalls I encountered along the way.
About Us
YouTube
https://www.youtube.com/c/JocheOjedaXAFXAMARINC
Our sites
Let’s discuss your XAF
https://www.udemy.com/course/microsoft-ai-extensions/
Our free A.I courses on Udemy

by Joche Ojeda | Mar 11, 2025 | network
DNS and Virtual Hosting: A Personal Journey
In this article, I’m going to talk about a topic I’ve been working on lately because I’m creating a course on how to host ASP.NET Core applications on Linux. This is a trick that I learned a really long time ago.
I was talking with one of my students, Lance, who asked me when I learned all this hosting and server stuff. It’s actually a nice story.
My Early Server Adventures
When I was around 16 years old, I got a book on networking and figured out how to find free public IPs on my Internet provider’s network. A few years later, when I was 19, I got a book on Windows 2000 Server and managed to get a copy of that Windows version.
I had a great combination of resources:
- Public IPs that I was “borrowing” from my Internet provider
- A copy of Windows Server
- An extra machine (at that time, we only had one computer at home, unlike now where I have about 5 computers)
I formatted the extra computer using Windows Server 2000 and set up DNS using a program called Simple DNS. I also set up the IIS web server. Finally, for the first time in my life, I could host a domain from a computer at home.
In El Salvador, .sv domains were free at that time—you just needed to fill out a form and you could get them for free for many years. Now they’re quite expensive, around $50, compared to normal domains.
The Magic of Virtual Hosting
What I learned was that you can host multiple websites or web applications sharing the same IP without having to change ports by using a hostname or domain name instead.
Here’s how DNS works: When you have an internet connection, it has several parts—the IP address, the public mask, the gateway, and the DNS servers. The DNS servers essentially house a simple file where they have translations: this domain (like HotCoder.com) translates to this IP address. They make IP addresses human-readable.
Once requests go to the server side, the server checks which domain name is being requested and then picks from all the websites being hosted on that server and responds accordingly.
Creating DNS records was tricky the first time. I spent a lot of time reading about it. The internet wasn’t like it is now—we didn’t have AI to help us. I had to figure it out with books, and growing up in El Salvador, we didn’t always have the newest or most accurate books available.
The Hosts File: A Local DNS
In the most basic setup, you need a record which says “this domain goes to this IP,” and then maybe a CNAME record that does something similar. That’s what DNS servers do—they maintain these translation tables.
Each computer also has its own translation table, which is a text file. In Windows, it’s called the “hosts” file. If you’ve used computers for development, you probably know that there’s an IP address reserved for localhost: 127.0.0.1. When you type “localhost” in the browser, it translates to that IP address.
This translation doesn’t require an external network request. Instead, your computer checks the hosts file, where you can set up the same domain-to-IP translations locally. This is how you can test domains without actually buying them. You can say “google.com will be forwarded to this IP address” which can be on your own computer.
A Real-World Application
I used this principle just this morning. I have an old MSI computer from 2018—still a solid machine with an i7 processor and 64GB of RAM. I reformatted it last week and set up the Hyper-V server. Inside Hyper-V, I set up an Ubuntu machine to emulate hosting, and installed a virtual hosting manager called Webmin.
I know I could do everything via command line, but why write a lot of text when you can use a user interface?
Recently, we’ve been having problems with our servers. My business partner Javier (who’s like a brother to me) mentioned that we have many test servers without clear documentation of what’s inside each one. We decided to format some of them to make them clean test servers again.
One of our servers that was failing happens to host my blog—the very one you’re reading right now! Yesterday, Javier messaged me early in the morning (7 AM for me in Europe, around 9 PM for him in America) to tell me my blog was down. There seemed to be a problem with the server that I couldn’t immediately identify.
We decided to move to a bigger server. I created a backup of the virtual server (something I’ll discuss in a different post) and moved it to the Hyper-V virtual machine on my MSI computer. I didn’t want to redirect my real IP address and DNS servers to my home computer—that would be messy and prevent access to my blog temporarily.
Instead, I modified the hosts file on my computer to point to the private internal IP of that virtual server. This allowed me to test everything locally before making any public DNS changes.
Understanding DNS: A Practical Example
Let me explain how DNS actually works with a simple example using the domain jocheojeda.com and an IP address of 203.0.113.42.
How DNS Resolution Works with ISP DNS Servers
When you type jocheojeda.com in your browser, here’s what happens:
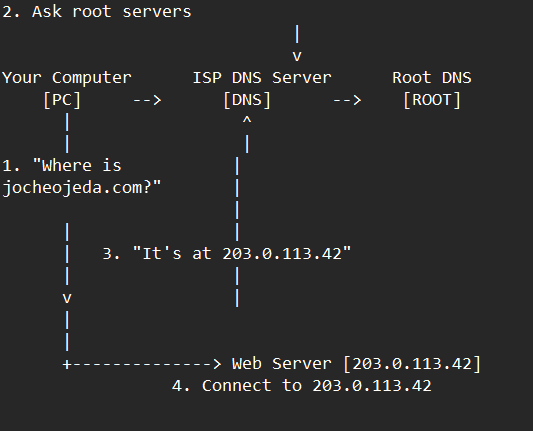
- Your browser asks your operating system to resolve
jocheojeda.com
- Your OS checks its local DNS cache, doesn’t find it, and then asks your ISP’s DNS server
- If the ISP’s DNS server doesn’t know, it asks the root DNS servers, which direct it to the appropriate Top-Level Domain (TLD) servers for
.com
- The TLD servers direct the ISP DNS to the authoritative DNS servers for
jocheojeda.com
- The authoritative DNS server responds with the A record:
jocheojeda.com -> 203.0.113.42
- Your ISP DNS server caches this information and passes it back to your computer
- Your browser can now connect directly to the web server at
203.0.113.42
DNS Records Explained
A Record (Address Record)
An A record maps a domain name directly to an IPv4 address:
jocheojeda.com. IN A 203.0.113.42
This tells DNS servers that when someone asks for jocheojeda.com, they should be directed to the server at 203.0.113.42.
CNAME Record (Canonical Name)
A CNAME record maps one domain name to another domain name:
www.jocheojeda.com. IN CNAME jocheojeda.com.
blog.jocheojeda.com. IN CNAME jocheojeda.com.
This means that www.jocheojeda.com and blog.jocheojeda.com are aliases for jocheojeda.com. When someone visits either of these subdomains, DNS will first resolve them to jocheojeda.com, and then resolve that to 203.0.113.42.
Using the Windows Hosts File
Now, let’s see what happens when you use the hosts file instead:
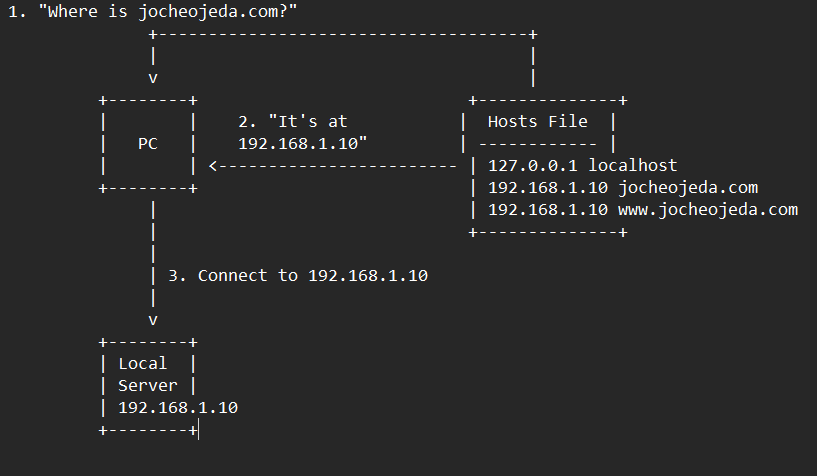
When using the hosts file:
- Your browser asks your operating system to resolve
jocheojeda.com
- Your OS checks the hosts file first, before any external DNS servers
- It finds an entry:
192.168.1.10 jocheojeda.com
- The OS immediately returns the IP
192.168.1.10 to your browser
- Your browser connects to
192.168.1.10 instead of the actual public IP
- The external DNS servers are never consulted
The Windows hosts file is located at C:\Windows\System32\drivers\etc\hosts. A typical entry might look like:
# For local development
192.168.1.10 jocheojeda.com
192.168.1.10 www.jocheojeda.com
192.168.1.10 api.jocheojeda.com
This is incredibly useful for:
- Testing websites locally before going live
- Testing different server configurations without changing public DNS
- Redirecting domains during development or troubleshooting
- Blocking certain websites by pointing them to 127.0.0.1
Why This Matters for Development
By modifying your hosts file, you can work on multiple websites locally, all running on the same machine but accessible via different domain names. This perfectly mimics how virtual hosting works on real servers, but without needing to change any public DNS records.
This technique saved me when my blog server was failing. I could test everything locally using my actual domain name in the browser, making sure everything was working correctly before changing any public DNS settings.
Conclusion
Understanding DNS and how to manipulate it locally via the hosts file is a powerful skill for any developer or system administrator. It allows you to test complex multi-domain setups without affecting your live environment, and can be a lifesaver when troubleshooting server issues.
In future posts, I’ll dive deeper into server virtualization and how to efficiently manage multiple web applications on a single server.
About Us
YouTube
https://www.youtube.com/c/JocheOjedaXAFXAMARINC
Our sites
Let’s discuss your XAF
https://www.udemy.com/course/microsoft-ai-extensions/
Our free A.I courses on Udemy

by Joche Ojeda | Mar 11, 2025 | http, MAUI, Xamarin
When developing cross-platform mobile applications with .NET MAUI (or previously Xamarin), you may encounter situations where your app works perfectly with public APIs but fails when connecting to internal network services. These issues often stem from HTTP client implementation differences, certificate validation, and TLS compatibility. This article explores how to identify, troubleshoot, and resolve these common networking challenges.
Understanding HTTP Client Options in MAUI/Xamarin
In the MAUI/.NET ecosystem, developers have access to two primary HTTP client implementations:
1. Managed HttpClient (Microsoft’s implementation)
- Cross-platform implementation built into .NET
- Consistent behavior across different operating systems
- May handle SSL/TLS differently than platform-native implementations
- Uses the .NET certificate validation system
2. Native HttpClient (Android’s implementation)
- Leverages the platform’s native networking stack
- Typically offers better performance on the specific platform
- Uses the device’s system certificate trust store
- Follows platform-specific security policies and restrictions
Switching Between Native and Managed HttpClient
In MAUI Applications
MAUI provides a flexible handler registration system that lets you explicitly choose which implementation to use:
// In your MauiProgram.cs
public static MauiApp CreateMauiApp()
{
var builder = MauiApp.CreateBuilder();
builder
.UseMauiApp<App>()
.ConfigureMauiHandlers(handlers =>
{
// Use the managed implementation (Microsoft's .NET HttpClient)
handlers.AddHandler(typeof(HttpClient), typeof(ManagedHttpMessageHandler));
// OR use the native implementation (platform-specific)
// handlers.AddHandler(typeof(HttpClient), typeof(PlatformHttpMessageHandler));
});
return builder.Build();
}
In Xamarin.Forms Legacy Applications
For Xamarin.Forms applications, set this in your platform-specific initialization code:
// In MainActivity.cs (Android) or AppDelegate.cs (iOS)
HttpClientHandler.UseNativePlatformHandler = false; // Use managed handler
// OR
HttpClientHandler.UseNativePlatformHandler = true; // Use native handler
Creating Specific Client Instances
You can also explicitly create HttpClient instances with specific handlers when needed:
// Use the managed handler
var managedHandler = new HttpClientHandler();
var managedClient = new HttpClient(managedHandler);
// Use the native handler (with DependencyService in Xamarin)
var nativeHandler = DependencyService.Get<INativeHttpClientHandler>();
var nativeClient = new HttpClient(nativeHandler);
Using HttpClientFactory (Recommended for MAUI)
For better control, testability, and lifecycle management, consider using HttpClientFactory:
// In your MauiProgram.cs
builder.Services.AddHttpClient("ManagedClient", client => {
client.BaseAddress = new Uri("https://your.api.url/");
})
.ConfigurePrimaryHttpMessageHandler(() => new SocketsHttpHandler());
// Then inject and use it in your services
public class MyApiService
{
private readonly HttpClient _client;
public MyApiService(IHttpClientFactory clientFactory)
{
_client = clientFactory.CreateClient("ManagedClient");
}
}
Common Issues and Troubleshooting
1. Self-Signed Certificates
Internal APIs often use self-signed certificates that aren’t trusted by default. Here’s how to handle them:
// Option 1: Create a custom handler that bypasses certificate validation
// (ONLY for development/testing environments)
var handler = new HttpClientHandler
{
ServerCertificateCustomValidationCallback = (message, cert, chain, errors) => true
};
var client = new HttpClient(handler);
For production environments, instead of bypassing validation:
- Add your self-signed certificate to the Android trust store
- Configure your app to trust specific certificates
- Generate proper certificates from a trusted Certificate Authority
2. TLS Version Mismatches
Different Android versions support different TLS versions by default:
- Android 4.1-4.4: TLS 1.0 by default
- Android 5.0+: TLS 1.0, 1.1, 1.2
- Android 10+: TLS 1.3 support
If your server requires a specific TLS version:
// Force specific TLS versions
System.Net.ServicePointManager.SecurityProtocol = SecurityProtocolType.Tls12 | SecurityProtocolType.Tls13;
3. Network Configuration
Ensure your app has the proper permissions in the AndroidManifest.xml:
<uses-permission android:name="android.permission.INTERNET" />
<uses-permission android:name="android.permission.ACCESS_NETWORK_STATE" />
For Android 9+ (API level 28+), configure network security:
<!-- Create a network_security_config.xml file in Resources/xml -->
<?xml version="1.0" encoding="utf-8"?>
<network-security-config>
<domain-config cleartextTrafficPermitted="true">
<domain includeSubdomains="true">your.internal.domain</domain>
</domain-config>
</network-security-config>
Then reference it in your AndroidManifest.xml:
<application android:networkSecurityConfig="@xml/network_security_config">
Practical Troubleshooting Steps
- Test with both HTTP client implementationsSwitch between native and managed implementations to isolate whether the issue is specific to one implementation
- Test the API endpoint outside your appUse tools like Postman or curl on the same network
- Enable logging for network calls
// Add this before making requests
HttpClient.DefaultRequestHeaders.TryAddWithoutValidation("User-Agent", "YourApp/1.0");
- Capture and inspect network trafficUse Charles Proxy or Fiddler to inspect the actual requests/responses
- Check certificate information
# On your development machine
openssl s_client -connect your.internal.server:443 -showcerts
- Verify which implementation you’re using
var client = new HttpClient();
var handlerType = client.GetType().GetField("_handler",
System.Reflection.BindingFlags.Instance |
System.Reflection.BindingFlags.NonPublic)?.GetValue(client);
Console.WriteLine($"Using handler: {handlerType?.GetType().FullName}");
- Debug specific errors
- For Java.IO.IOException: “Trust anchor for certification path not found” – this means your app doesn’t trust the certificate
- For HttpRequestException with “The SSL connection could not be established” – likely a TLS version mismatch
Conclusion
When your MAUI Android app connects successfully to public APIs but fails with internal network services, the issue often lies with HTTP client implementation differences, certificate validation, or TLS compatibility. By systematically switching between native and managed HTTP clients and applying the troubleshooting techniques outlined above, you can identify and resolve these networking challenges.
Remember that each implementation has its advantages – the native implementation typically offers better performance and follows platform-specific security policies, while the managed implementation provides more consistent cross-platform behavior. Choose the one that best fits your specific requirements and security considerations.
About Us
YouTube
https://www.youtube.com/c/JocheOjedaXAFXAMARINC
Our sites
Let’s discuss your XAF
https://www.udemy.com/course/microsoft-ai-extensions/
Our free A.I courses on Udemy

by Joche Ojeda | Mar 7, 2025 | Uncategorized, Uno Platform
This year I decided to learn something new, specifically something UI-related. Usually, I only do back-end type of code. Most of my code has no UI representation, and as you might know, that’s why I love XAF from Developer Express so much—because I don’t have to write a UI. I only have to define the business model and the actions, and then I’m good to go.
But this time, I wanted to challenge myself, so I said, “OK, let’s learn something that is UI-related.” I’ve been using .NET for about 18 years already, so I wanted to branch out while still leveraging my existing knowledge.
I was trying to decide which technology to go with, so I checked with the people in my office (XARI). We have the .NET team, which is like 99% of the people, and then we have one React person and a couple of other developers using different frameworks. They suggested Flutter, and I thought, “Well, maybe.”
I checked the setup and tried to do it on my new Surface computer, but it just didn’t work. Even though Flutter looks fine, moving from .NET (which I’ve been writing since day one in 2002) to Dart is a big challenge. I mean, writing code in any case is a challenge, but I realized that Flutter was so far away from my current infrastructure and setup that I would likely learn it and then forget it because I wouldn’t use it regularly.
Then I thought about checking React, but it was kind of the same idea. I could go deep into this for like one month, and then I would totally forget it because I wouldn’t update the tooling, and so on.
So I decided to take another look at Uno Platform. We’ve used Uno Platform in the office before, and I love this multi-platform development approach. The only problem I had at that time was that the tooling wasn’t quite there yet. Sometimes it would compile, sometimes you’d get a lot of errors, and the static analysis would throw a lot of errors too. It was kind of hard—you’d spend a lot of time setting up your environment, and compilation was kind of slow.
But when I decided to take a look again recently, I remembered that about a year ago they released new project templates and platform extensions that help with the setup of your environment. So I tried it, and it worked well! I have two clean setups right now: my new Surface computer that I reset maybe three weeks ago, and my old MSI computer with 64 gigabytes of RAM. These gave me good places to test.
I decided to go to the Uno Platform page and follow the “Getting Started” guide. The first thing you need to do is use some commands to install a tool that checks your setup to see if you have all the necessary workloads. That was super simple. Then you have to add the extension to Visual Studio—I’m using Visual Studio in this case just to add the project templates. You can do this in Rider or Visual Studio Code as well, but the traditional Visual Studio is my tool of preference.
Uno Platform – Visual Studio Marketplace
Setup your environment with uno check
After completing all the setup, you get a menu with a lot of choices, but they give you a set of recommended options that follow best practices. That’s really nice because you don’t have to think too much about it. After that, I created a few projects. The first time I compiled them, it took a little bit, but then it was just like magic—they compiled extremely fast!
You have all these choices to run your app on: WebAssembly, Windows UI, Android, and iOS, and it works perfectly. I fell in love again, especially because the tooling is actually really solid right now. You don’t have to struggle to make it work.
Since then, I’ve been checking the examples and trying to write some code, and so far, so good. I guess my new choice for a UI framework will be Uno because it builds on my current knowledge of .NET and C#. I can take advantage of the tools I already have, and I don’t have to switch languages. I just need to learn a new paradigm.
I will write a series of articles about all my adventures with Uno Platform. I’ll share links about getting started, and after this, I’ll create some sample applications addressing the challenges that app developers face: how to implement navigation, how to register services, how to work with the Model-View-ViewModel pattern, and so on.
I would like to document every challenge I encounter, and I hope that you can join me in these Uno adventures!
About Us
YouTube
https://www.youtube.com/c/JocheOjedaXAFXAMARINC
Our sites
Let’s discuss your XAF
https://calendly.com/bitframeworks/bitframeworks-free-xaf-support-hour/
Our free A.I courses on Udemy