
by Joche Ojeda | Jan 5, 2026 | A.I, Postgres
RAG with PostgreSQL and C#
Happy New Year 2026 — let the year begin
Happy New Year 2026 🎉
Let’s start the year with something honest.
This article exists because something broke.
I wasn’t trying to build a demo.
I was building an activity stream — the kind of thing every social or collaborative system eventually needs.
Posts.
Comments.
Reactions.
Short messages.
Long messages.
Noise.
At some point, the obvious question appeared:
“Can I do RAG over this?”
That question turned into this article.
The Original Problem: RAG over an Activity Stream
An activity stream looks simple until you actually use it as input.
In my case:
- The UI language was English
- The content language was… everything else
Users were writing:
- Spanish
- Russian
- Italian
- English
- Sometimes all of them in the same message
Perfectly normal for humans.
Absolutely brutal for naïve RAG.
I tried the obvious approach:
- embed everything
- store vectors
- retrieve similar content
- augment the prompt
And very quickly, RAG went crazy.
Why It Failed (And Why This Matters)
The failure wasn’t dramatic.
No exceptions.
No errors.
Just… wrong answers.
Confident answers.
Fluent answers.
Wrong answers.
The problem was subtle:
- Same concept, different languages
- Mixed-language sentences
- Short, informal activity messages
- No guarantee of language consistency
In an activity stream:
- You don’t control the language
- You don’t control the structure
- You don’t even control what a “document” is
And RAG assumes you do.
That’s when I stopped and realized:
RAG is not “plug-and-play” once your data becomes messy.
So… What Is RAG Really?
RAG stands for Retrieval-Augmented Generation.
The idea is simple:
Retrieve relevant data first, then let the model reason over it.
Instead of asking the model to remember everything, you let it look things up.
Search first.
Generate second.
Sounds obvious.
Still easy to get wrong.
The Real RAG Pipeline (No Marketing)
A real RAG system looks like this:
- Your data lives in a database
- Text is split into chunks
- Each chunk becomes an embedding
- Embeddings are stored as vectors
- A user asks a question
- The question is embedded
- The closest vectors are retrieved
- Retrieved content is injected into the prompt
- The model answers
Every step can fail silently.
Tokenization & Chunking (The First Trap)
Models don’t read text.
They read tokens.
This matters because:
- prompts have hard limits
- activity streams are noisy
- short messages lose context fast
You usually don’t tokenize manually, but you do choose:
- chunk size
- overlap
- grouping strategy
In activity streams, chunking is already a compromise — and multilingual content makes it worse.
Embeddings in .NET (Microsoft.Extensions.AI)
In .NET, embeddings are generated using Microsoft.Extensions.AI.
The important abstraction is:
IEmbeddingGenerator<TInput, TEmbedding>
This keeps your architecture:
- provider-agnostic
- DI-friendly
- survivable over time
Minimal Setup
dotnet add package Microsoft.Extensions.AI
dotnet add package Microsoft.Extensions.AI.OpenAI
Creating an Embedding Generator
using OpenAI;
using Microsoft.Extensions.AI;
using Microsoft.Extensions.AI.OpenAI;
var client = new OpenAIClient("YOUR_API_KEY");
IEmbeddingGenerator<string, Embedding<float>> embeddings =
client.AsEmbeddingGenerator("text-embedding-3-small");
Generating a Vector
var result = await embeddings.GenerateAsync(
new[] { "Some activity text" });
float[] vector = result.First().Vector.ToArray();
That vector is what drives everything that follows.
⚠️ Embeddings Are Model-Locked (And Language Makes It Worse)
Embeddings are model-locked.
Meaning:
Vectors from different embedding models cannot be compared.
Even if:
- the dimension matches
- the text is identical
- the provider is the same
Each model defines its own universe.
But here’s the kicker I learned the hard way:
Multilingual content amplifies this problem.
Even with multilingual-capable models:
- language mixing shifts vector space
- short messages lose semantic anchors
- similarity becomes noisy
In an activity stream:
- English UI
- Spanish content
- Russian replies
- Emoji everywhere
Vector distance starts to mean “kind of related, maybe”.
That’s not good enough.
PostgreSQL + pgvector (Still the Right Choice)
Despite all that, PostgreSQL with pgvector is still the right foundation.
Enable pgvector
CREATE EXTENSION IF NOT EXISTS vector;
Chunk-Based Table
CREATE TABLE doc_chunks (
id bigserial PRIMARY KEY,
document_id bigint NOT NULL,
chunk_index int NOT NULL,
content text NOT NULL,
embedding vector(1536) NOT NULL,
created_at timestamptz NOT NULL DEFAULT now()
);
Technically correct.
Architecturally incomplete — as I later discovered.
Retrieval: Where Things Quietly Go Wrong
SELECT content
FROM doc_chunks
ORDER BY embedding <=> @query_embedding
LIMIT 5;
This query decides:
- what the model sees
- what it ignores
- how wrong the answer will be
When language is mixed, retrieval looks correct — but isn’t.
Classic example: Moscow
So for a Spanish speaker, “Mosca” looks like it should mean insect (which it does), but it’s also the Italian name for Moscow.
Why RAG Failed in This Scenario
Let’s be honest:
- Similar ≠ relevant
- Multilingual ≠ multilingual-safe
- Short activity messages ≠ documents
- Noise ≠ knowledge
RAG didn’t fail because the model was bad.
It failed because the data had no structure.
Why This Article Exists
This article exists because:
- I tried RAG on a real system
- With real users
- Writing in real languages
- In real combinations
And the naïve RAG approach didn’t survive.
What Comes Next
The next article will not be about:
It will be about structured RAG.
How I fixed this by:
- introducing structure into the activity stream
- separating concerns in the pipeline
- controlling language before retrieval
- reducing semantic noise
- making RAG predictable again
In other words:
How to make RAG work after it breaks.
Final Thought
RAG is not magic.
It’s:
search + structure + discipline
If your data is chaotic, RAG will faithfully reflect that chaos — just with confidence.
Happy New Year 2026 🎆
If you’re reading this:
Happy New Year 2026.
Let’s make this the year we stop trusting demos
and start trusting systems that survived reality.
Let the year begin 🚀
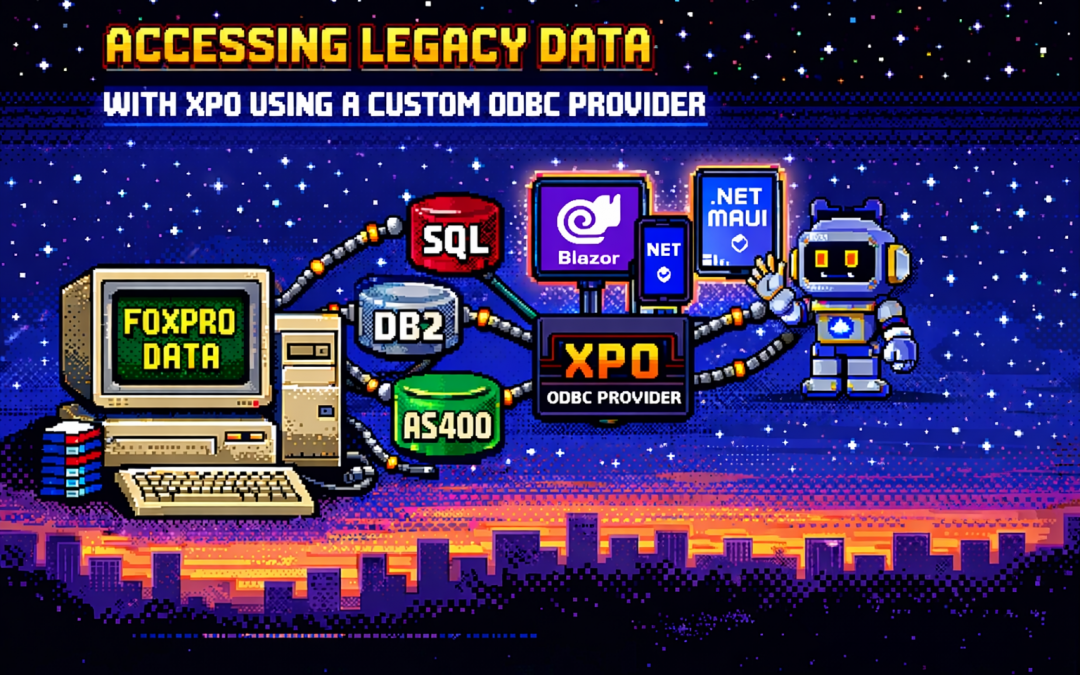
by Joche Ojeda | Dec 23, 2025 | ADO, ADO.NET, XPO
One of the recurring challenges in real-world systems is not building new software — it’s
integrating with software that already exists.
Legacy systems don’t disappear just because newer technologies are available. They survive because they work,
because they hold critical business data, and because replacing them is often risky, expensive, or simply not allowed.
This article explores a practical approach to accessing legacy data using XPO by leveraging ODBC,
not as a universal abstraction, but as a bridge when no modern provider exists.
The Reality of Legacy Systems
Many organizations still rely on systems built on technologies such as:
- FoxPro tables
- AS400 platforms
- DB2-based systems
- Proprietary or vendor-abandoned databases
In these scenarios, it’s common to find that:
- There is no modern .NET provider
- There is no ORM support
- There is an ODBC driver
That last point is crucial. ODBC often remains available long after official SDKs and providers have disappeared.
It becomes the last viable access path to critical data.
Why ORMs Struggle with Legacy Data
Modern ORMs assume a relatively friendly environment: a supported database engine, a known SQL dialect,
a compatible type system, and an actively maintained provider.
Legacy databases rarely meet those assumptions. As a result, teams are often forced to:
- Drop down to raw SQL
- Build ad-hoc data access layers
- Treat legacy data as a second-class citizen
This becomes especially painful in systems that already rely heavily on DevExpress XPO for persistence,
transactions, and domain modeling.
ODBC Is Not Magic — and That’s the Point
ODBC is often misunderstood.
Using ODBC does not mean:
- One provider works for every database
- SQL becomes standardized
- Type systems become compatible
Each ODBC-accessible database still has:
- Its own SQL dialect
- Its own limitations
- Its own data types
- Its own behavioral quirks
ODBC simply gives you a way in. It is a transport mechanism, not a universal language.
What an XPO ODBC Provider Really Is
When you implement an XPO provider on top of ODBC, you are not building a generic solution for all databases.
You are building a targeted adapter for a specific legacy system that happens to be reachable via ODBC.
This matters because ODBC is used here as a pragmatic trick:
- To connect to something you otherwise couldn’t
- To reuse an existing, stable access path
- To avoid rewriting or destabilizing legacy systems
The database still dictates the SQL dialect, supported features, and type system. Your provider must respect those constraints.
Why XPO Makes This Possible
XPO is not just an ORM — it is a provider-based persistence framework.
All SQL-capable XPO providers are built on top of a shared foundation, most notably:
ConnectionProviderSql
https://docs.devexpress.com/CoreLibraries/DevExpress.Xpo.DB.ConnectionProviderSql
This architecture allows you to reuse XPO’s core benefits:
- Object model
- Sessions and units of work
- Transaction handling
- Integration with domain logic
While customizing what legacy systems require:
- SQL generation
- Command execution
- Schema discovery
- Type mapping
Dialects and Type Systems Still Matter
Even when accessed through ODBC:
- FoxPro is not SQL Server
- DB2 is not PostgreSQL
- AS400 is not Oracle
Each system has its own:
- Date and time semantics
- Numeric precision rules
- String handling behavior
- Constraints and limits
An XPO ODBC provider must explicitly map database types, handle dialect-specific SQL,
and avoid assumptions about “standard SQL.” ODBC opens the door — it does not normalize what’s inside.
Real-World Experience: AS400 and DB2 in Production
This approach is not theoretical. Last year, we implemented a custom XPO provider using ODBC for
AS400 and DB2 systems in Mexico, where:
- No viable modern .NET provider existed
- The systems were deeply embedded in business operations
- ODBC was the only stable integration path
By introducing an XPO provider on top of ODBC, we were able to integrate legacy data into a modern .NET architecture,
preserve domain models and transactional behavior, and avoid rewriting or destabilizing existing systems.
The Hidden Advantage: Modern UI and AI Access
Once legacy data is exposed through XPO, something powerful happens: that data becomes immediately available to modern platforms.
- Blazor applications
- .NET MAUI mobile and desktop apps
- Background services
- Integration APIs
- AI agents and assistants
And you get this without rewriting the database, migrating the data, or changing the legacy system.
XPO becomes the adapter that allows decades-old data to participate in modern UI stacks, automated workflows,
and AI-driven experiences.
Why Not Just Use Raw ODBC?
Raw ODBC gives you rows, columns, and primitive values. XPO gives you domain objects, identity tracking,
relationships, transactions, and a consistent persistence model.
The goal is not to modernize the database. The goal is to modernize access to legacy data
so it can safely participate in modern architectures.
Closing Thought
An XPO ODBC provider is not a silver bullet. It will not magically unify SQL dialects, type systems, or database behavior.
But when used intentionally, it becomes a powerful bridge between systems that cannot be changed
and architectures that still need to evolve.
ODBC is the trick that lets you connect.
XPO is what makes that connection usable — everywhere, from Blazor UIs to AI agents.

by Joche Ojeda | Dec 23, 2025 | ADO, ADO.NET, C#
When I started working with computers, one of the tools that shaped my way of thinking as a developer was FoxPro.
At the time, FoxPro felt like a complete universe: database engine, forms, reports, and business logic all integrated into a single environment.
Looking back, FoxPro was effectively an application framework from the past—long before that term became common.
Accessing FoxPro data usually meant choosing between two paths:
- Direct FoxPro access – fast, tightly integrated, and fully aware of FoxPro’s features
- ODBC – a standardized way to access the data from outside the FoxPro ecosystem
This article focuses on that second option.
What Is ODBC?
ODBC (Open Database Connectivity) is a standardized API for accessing databases.
Instead of applications talking directly to a specific database engine, they talk to an ODBC driver,
which translates generic database calls into database-specific commands.
The promise was simple:
One API, many databases.
And for its time, this was revolutionary.
Supported Operating Systems and Use Cases
ODBC is still relevant today and supported across major platforms:
- Windows – native support, mature tooling
- Linux – via unixODBC and vendor drivers
- macOS – supported through driver managers
Typical use cases include:
- Legacy systems that must remain stable
- Reporting and BI tools
- Data migration and ETL pipelines
- Cross-vendor integrations
- Long-lived enterprise systems
ODBC excels where interoperability matters more than elegance.
The Lowest Common Denominator Problem
Although ODBC is a standard, it does not magically unify databases.
Each database has its own:
- SQL dialect
- Data types
- Functions
- Performance characteristics
ODBC standardizes access, not behavior.
You can absolutely open an ODBC connection and still:
- Call native database functions
- Use vendor-specific SQL
- Rely on engine-specific behavior
This makes ODBC flexible—but not truly database-agnostic.
ODBC vs True Abstraction Layers
This is where ODBC differs from ORMs or persistence frameworks that aim for full abstraction.
- ODBC: Gives you a common door and does not prevent database-specific usage
- ORM-style frameworks: Try to hide database differences and enforce a common conceptual model
ODBC does not protect you from database specificity—it permits it.
ODBC in .NET: Avoiding Native Database Dependencies
This is an often-overlooked advantage of ODBC, especially in .NET applications.
ADO.NET is interface-driven:
IDbConnectionIDbCommandIDataReader
However, each database requires its own concrete provider:
- SQL Server
- Oracle
- DB2
- Pervasive
- PostgreSQL
- MySQL
Each provider introduces:
- Native binaries
- Vendor SDKs
- Version compatibility issues
- Deployment complexity
Your code may be abstract — your deployment is not.
ODBC as a Binary Abstraction Layer
When using ODBC in .NET, your application depends on one provider only:
System.Data.Odbc
Database-specific dependencies are moved:
- Out of your application
- Into the operating system
- Into driver configuration
This turns ODBC into a dependency firewall.
Minimal .NET Example: ODBC vs Native Provider
Native ADO.NET Provider (Example: SQL Server)
using System.Data.SqlClient;
using var connection =
new SqlConnection("Server=.;Database=AppDb;Trusted_Connection=True;");
connection.Open();
Implications:
- Requires SQL Server client libraries
- Ties the binary to SQL Server
- Changing database = new provider + rebuild
ODBC Provider (Database-Agnostic Binary)
using System.Data.Odbc;
using var connection =
new OdbcConnection("DSN=AppDatabase");
connection.Open();
Implications:
- Same binary works for SQL Server, Oracle, DB2, etc.
- No vendor-specific DLLs in the app
- Database choice is externalized
The SQL inside the connection may still be database-specific — but your application binary is not.
Trade-Offs (And Why They’re Acceptable)
Using ODBC means:
- Fewer vendor-specific optimizations
- Possible performance differences
- Reliance on driver quality
But in exchange, you gain:
- Simpler deployments
- Easier migrations
- Longer application lifespan
- Reduced vendor lock-in
For many enterprise systems, this is a strategic win.
What’s Next – Phase 2: Customer Polish
Phase 1 is about making it work.
Phase 2 is about making it survivable for customers.
In Phase 2, ODBC shines by enabling:
- Zero-code database switching
- Cleaner installers
- Fewer runtime surprises
- Support for customer-controlled environments
- Reduced friction in on-prem deployments
This is where architecture meets reality.
Customers don’t care how elegant your abstractions are — they care that your software runs on their infrastructure without drama.
Project References
Minimal and explicit:
System.Data
System.Data.Odbc
Optional (native providers, when required):
System.Data.SqlClient
Oracle.ManagedDataAccess
IBM.Data.DB2
ODBC allows these to become optional, not mandatory.
Closing Thought
ODBC never promised purity.
It promised compatibility.
Just like FoxPro once gave us everything in one place, ODBC gave us a way out — without burning everything down.
Decades later, that trade-off still matters.

by Joche Ojeda | Oct 16, 2025 | Events, Oqtane
OK, I’m still blocked from GitHub Copilot, so I still have more things to write about.
In this article, the topic that we’re going to see is the event system of Oqtane.For example, usually in most systems you want to hook up something when the application starts.
In XAF from Developer Express, which is my specialty (I mean, that’s the framework I really know well),
you have the DB Updater, which you can use to set up some initial data.
In Oqtane, you have the Module Manager, but there are also other types of events that you might need —
for example, when the user is created or when the user signs in for the first time.
So again, using the method that I explained in my previous article — the “OK, I have a doubt” method —
I basically let the guide of Copilot hike over my installation folder or even the Oqtane source code itself, and try to figure out how to do it.
That’s how I ended up using event subscribers.
In one of my prototypes, what I needed to do was detect when the user is created and then create some records in a different system
using that user’s information. So I’ll show an example of that type of subscriber, and I’ll actually share the
Oqtane Event Handling Guide here, which explains how you can hook up to system events.
I’m sure there are more events available, but this is what I’ve found so far and what I’ve tested.
I guess I’ll make a video about all these articles at some point, but right now, I’m kind of vibing with other systems.
Whenever I get blocked, I write something about my research with Oqtane.
Oqtane Event Handling Guide
Comprehensive guide to capturing and responding to system events in Oqtane
This guide explains how to handle events in Oqtane, particularly focusing on user authentication events (login, logout, creation)
and other system events. Learn to build modules that respond to framework events and create custom event-driven functionality.
Version: 1.0.0
Last Updated: October 3, 2025
Oqtane Version: 6.0+
Framework: .NET 9.0
1. Overview of Oqtane Event System
Oqtane uses a centralized event system based on the SyncManager that broadcasts events throughout the application when entities change.
This enables loose coupling between components and allows modules to respond to framework events without tight integration.
Key Components
- SyncManager — Central event hub that broadcasts entity changes
- SyncEvent — Event data containing entity information and action type
- IEventSubscriber — Interface for objects that want to receive events
- EventDistributorHostedService — Background service that distributes events to subscribers
Entity Changes → SyncManager → EventDistributorHostedService → IEventSubscriber Implementations
↓
SyncEvent Created → Distributed to All Event Subscribers
2. Event Types and Actions
SyncEvent Model
public class SyncEvent : EventArgs
{
public int TenantId { get; set; }
public int SiteId { get; set; }
public string EntityName { get; set; }
public int EntityId { get; set; }
public string Action { get; set; }
public DateTime ModifiedOn { get; set; }
}
Available Actions
public class SyncEventActions
{
public const string Refresh = "Refresh";
public const string Reload = "Reload";
public const string Create = "Create";
public const string Update = "Update";
public const string Delete = "Delete";
}
Common Entity Names
public class EntityNames
{
public const string User = "User";
public const string Site = "Site";
public const string Page = "Page";
public const string Module = "Module";
public const string File = "File";
public const string Folder = "Folder";
public const string Notification = "Notification";
}
3. Creating Event Subscribers
To handle events, implement IEventSubscriber and filter for the entities and actions you care about.
Subscribers are automatically discovered by Oqtane and injected with dependencies.
public class UserActivityEventSubscriber : IEventSubscriber
{
private readonly ILogger<UserActivityEventSubscriber> _logger;
public UserActivityEventSubscriber(ILogger<UserActivityEventSubscriber> logger)
{
_logger = logger;
}
public void EntityChanged(SyncEvent syncEvent)
{
if (syncEvent.EntityName != EntityNames.User)
return;
switch (syncEvent.Action)
{
case SyncEventActions.Create:
_logger.LogInformation("User created: {UserId}", syncEvent.EntityId);
break;
case "Login":
_logger.LogInformation("User logged in: {UserId}", syncEvent.EntityId);
break;
}
}
}
4. User Authentication Events
Login, logout, and registration trigger SyncEvent notifications that you can capture to send notifications,
track user activity, or integrate with external systems.
public class LoginActivityTracker : IEventSubscriber
{
private readonly ILogger<LoginActivityTracker> _logger;
public LoginActivityTracker(ILogger<LoginActivityTracker> logger)
{
_logger = logger;
}
public void EntityChanged(SyncEvent syncEvent)
{
if (syncEvent.EntityName == EntityNames.User && syncEvent.Action == "Login")
{
_logger.LogInformation("User {UserId} logged in at {Time}", syncEvent.EntityId, syncEvent.ModifiedOn);
}
}
}
5. System Entity Events
Besides user events, you can track changes in entities like Pages, Files, and Modules.
public class PageAuditTracker : IEventSubscriber
{
private readonly ILogger<PageAuditTracker> _logger;
public PageAuditTracker(ILogger<PageAuditTracker> logger)
{
_logger = logger;
}
public void EntityChanged(SyncEvent syncEvent)
{
if (syncEvent.EntityName == EntityNames.Page && syncEvent.Action == SyncEventActions.Create)
{
_logger.LogInformation("Page created: {PageId}", syncEvent.EntityId);
}
}
}
6. Custom Module Events
You can create custom events in your own modules using ISyncManager.
public class BlogManager
{
private readonly ISyncManager _syncManager;
public BlogManager(ISyncManager syncManager)
{
_syncManager = syncManager;
}
public void PublishBlog(int blogId)
{
_syncManager.AddSyncEvent(
new Alias { TenantId = 1, SiteId = 1 },
"Blog",
blogId,
"Published"
);
}
}
7. Best Practices
- Filter early — Always check the entity and action before processing.
- Handle exceptions — Never throw unhandled exceptions inside
EntityChanged.
- Log properly — Use structured logging with context placeholders.
- Keep it simple — Extract complex logic to testable services.
public void EntityChanged(SyncEvent syncEvent)
{
try
{
if (syncEvent.EntityName == EntityNames.User && syncEvent.Action == "Login")
{
_logger.LogInformation("User {UserId} logged in", syncEvent.EntityId);
}
}
catch (Exception ex)
{
_logger.LogError(ex, "Error processing event {Action}", syncEvent.Action);
}
}
8. Summary
Oqtane’s event system provides a clean, decoupled way to respond to system changes.
It’s perfect for audit logs, notifications, custom workflows, and integrations.
- Automatic discovery of subscribers
- Centralized event distribution
- Supports custom and system events
- Integrates naturally with dependency injection

by Joche Ojeda | Oct 16, 2025 | Oqtane
OK, I’ve been wanting to write this article for a few days now, but I’ve been vibing a lot — writing tons of prototypes and working on my Oqtane research. This morning I got blocked by GitHub Copilot because I hit the rate limit, so I can’t use it for a few hours. I figured that’s a sign to take a break and write some articles instead.
Actually, I’m not really “writing” — I’m using the Windows dictation feature (Windows key + H). So right now, I’m just having coffee and talking to my computer. I’m still in El Salvador with my family, and it’s like 5:00 AM here. My mom probably thinks I’ve gone crazy because I’ve been talking to my computer a lot lately. Even when I’m coding, I use dictation instead of typing, because sometimes it’s just easier to express yourself when you talk. When you type, you tend to shorten things, but when you talk, you can go on forever, right?
Anyway, this article is about Oqtane, specifically something that’s been super useful for me — how to set up a silent installation. Usually, when you download the Oqtane source or use the templates to create a new project or solution, and then run the server project, you’ll see the setup wizard first. That’s where you configure the database, email, host password, default theme, and all that.
Since I’ve been doing tons of prototypes, I’ve seen that setup screen thousands of times per day. So I downloaded the Oqtane source and started digging through it — using Copilot to generate guides whenever I got stuck. Honestly, the best way to learn is always by looking at the source code. I learned that the hard way years ago with XAF from DevExpress — there was no documentation back then, so I had to figure everything out manually and even assemble the projects myself because they weren’t in one solution. With Oqtane, it’s way simpler: everything’s in one place, just a few main projects.
Now, when I run into a problem, I just open the source code and tell Copilot, “OK, this is what I want to do. Help me figure it out.” Sometimes it goes completely wrong (as all AI tools do), but sometimes it nails it and produces a really good guide.
So the guide below was generated with Copilot, and it’s been super useful. I’ve been using it a lot lately, and I think it’ll save you a ton of time if you’re doing automated deployment with Oqtane.
I don’t want to take more of your time, so here it goes — I hope it helps you as much as it helped me.
Oqtane Installation Configuration Guide
This guide explains the configuration options available in the appsettings.json file under the Installation section for automated installation and default site settings.
Overview
The Installation section in appsettings.json controls the automated installation process and default settings for new sites in Oqtane. These settings are particularly useful for:
- Automated installations – Deploy Oqtane without manual configuration
- Development environments – Quickly spin up new instances
- Multi-tenant deployments – Standardize new site creation
- CI/CD pipelines – Automate deployment processes
Configuration Structure
{
"Installation": {
"DefaultAlias": "",
"HostPassword": "",
"HostEmail": "",
"SiteTemplate": "",
"DefaultTheme": "",
"DefaultContainer": ""
}
}
| Key |
Purpose |
Required |
DefaultAlias |
Initial site URL(s) |
✅ |
HostPassword |
Super admin password |
✅ |
HostEmail |
Super admin email |
✅ |
SiteTemplate |
Initial site structure |
Optional |
DefaultTheme |
Site appearance |
Optional |
DefaultContainer |
Module wrapper style |
Optional |
SiteTemplate
A Site Template defines the initial structure and content of a new site, including pages, modules, folders, and navigation.
"SiteTemplate": "Oqtane.Infrastructure.SiteTemplates.DefaultSiteTemplate, Oqtane.Server"
Default options:
- DefaultSiteTemplate – Home, Privacy, example content
- EmptySiteTemplate – Minimal, clean slate
- AdminSiteTemplate – Internal use
If empty, Oqtane uses the default template automatically.
DefaultTheme
A Theme controls the visual appearance and layout of your site (page structure, navigation, header/footer, and styling).
"DefaultTheme": "Oqtane.Themes.OqtaneTheme.Default, Oqtane.Client"
Built-in themes:
- Oqtane Theme (default) – clean and responsive
- Blazor Theme – Blazor-branded styling
- Bootswatch variants – Cerulean, Cosmo, Darkly, Flatly, Lux, etc.
- Corporate Theme – business layout
If left blank, it defaults to the Oqtane Theme.
DefaultContainer
A Container is the wrapper around each module, controlling how titles, buttons, and borders look.
"DefaultContainer": "Oqtane.Themes.OqtaneTheme.Container, Oqtane.Client"
Common containers:
- OqtaneTheme.Container – standard and responsive
- AdminContainer – management modules
- Theme-specific containers – match the chosen theme
Defaults automatically if left empty.
Example Configurations
Minimal Configuration
{
"Installation": {
"DefaultAlias": "localhost",
"HostPassword": "YourSecurePassword123!",
"HostEmail": "admin@example.com"
}
}
Custom Theme and Container
{
"Installation": {
"DefaultAlias": "localhost",
"HostPassword": "YourSecurePassword123!",
"HostEmail": "admin@example.com",
"SiteTemplate": "Oqtane.Infrastructure.SiteTemplates.DefaultSiteTemplate, Oqtane.Server",
"DefaultTheme": "Oqtane.Theme.Bootswatch.Flatly.Default, Oqtane.Theme.Bootswatch.Oqtane",
"DefaultContainer": "Oqtane.Theme.Bootswatch.Flatly.Container, Oqtane.Theme.Bootswatch.Oqtane"
}
}
Troubleshooting
- Settings ignored during installation: Ensure all required fields are filled (
DefaultAlias, HostPassword, HostEmail).
- Theme not found: Check assembly reference and type name.
- Container displays incorrectly: Use a container matching your theme.
- Site template creates no pages: Ensure your template returns valid page definitions.
Logs can be found in Logs/oqtane-log-YYYYMMDD.txt.
Best Practices
- Match your theme and container.
- Leave defaults empty unless customization is needed.
- Test in development first.
- Document any custom templates or themes.
- Use environment-specific appsettings (e.g.
appsettings.Development.json).
Summary
The Installation configuration in appsettings.json lets you fully automate your Oqtane setup.
- SiteTemplate: defines structure
- DefaultTheme: defines appearance
- DefaultContainer: defines module layout
Empty values use defaults, and you can override them for automation, branding, or custom scenarios.