by Joche Ojeda | Dec 23, 2025 | ADO, ADO.NET, XPO
One of the recurring challenges in real-world systems is not building new software — it’s
integrating with software that already exists.
Legacy systems don’t disappear just because newer technologies are available. They survive because they work,
because they hold critical business data, and because replacing them is often risky, expensive, or simply not allowed.
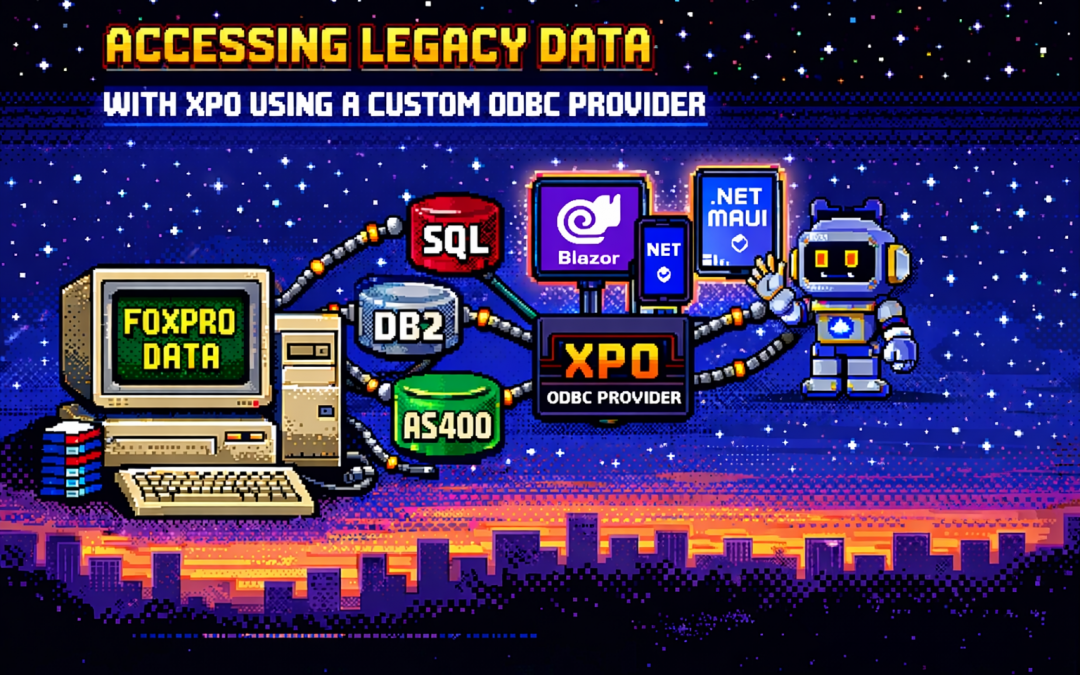
This article explores a practical approach to accessing legacy data using XPO by leveraging ODBC,
not as a universal abstraction, but as a bridge when no modern provider exists.
The Reality of Legacy Systems
Many organizations still rely on systems built on technologies such as:
- FoxPro tables
- AS400 platforms
- DB2-based systems
- Proprietary or vendor-abandoned databases
In these scenarios, it’s common to find that:
- There is no modern .NET provider
- There is no ORM support
- There is an ODBC driver
That last point is crucial. ODBC often remains available long after official SDKs and providers have disappeared.
It becomes the last viable access path to critical data.
Why ORMs Struggle with Legacy Data
Modern ORMs assume a relatively friendly environment: a supported database engine, a known SQL dialect,
a compatible type system, and an actively maintained provider.
Legacy databases rarely meet those assumptions. As a result, teams are often forced to:
- Drop down to raw SQL
- Build ad-hoc data access layers
- Treat legacy data as a second-class citizen
This becomes especially painful in systems that already rely heavily on DevExpress XPO for persistence,
transactions, and domain modeling.
ODBC Is Not Magic — and That’s the Point
ODBC is often misunderstood.
Using ODBC does not mean:
- One provider works for every database
- SQL becomes standardized
- Type systems become compatible
Each ODBC-accessible database still has:
- Its own SQL dialect
- Its own limitations
- Its own data types
- Its own behavioral quirks
ODBC simply gives you a way in. It is a transport mechanism, not a universal language.
What an XPO ODBC Provider Really Is
When you implement an XPO provider on top of ODBC, you are not building a generic solution for all databases.
You are building a targeted adapter for a specific legacy system that happens to be reachable via ODBC.
This matters because ODBC is used here as a pragmatic trick:
- To connect to something you otherwise couldn’t
- To reuse an existing, stable access path
- To avoid rewriting or destabilizing legacy systems
The database still dictates the SQL dialect, supported features, and type system. Your provider must respect those constraints.
Why XPO Makes This Possible
XPO is not just an ORM — it is a provider-based persistence framework.
All SQL-capable XPO providers are built on top of a shared foundation, most notably:
ConnectionProviderSql
https://docs.devexpress.com/CoreLibraries/DevExpress.Xpo.DB.ConnectionProviderSql
This architecture allows you to reuse XPO’s core benefits:
- Object model
- Sessions and units of work
- Transaction handling
- Integration with domain logic
While customizing what legacy systems require:
- SQL generation
- Command execution
- Schema discovery
- Type mapping
Dialects and Type Systems Still Matter
Even when accessed through ODBC:
- FoxPro is not SQL Server
- DB2 is not PostgreSQL
- AS400 is not Oracle
Each system has its own:
- Date and time semantics
- Numeric precision rules
- String handling behavior
- Constraints and limits
An XPO ODBC provider must explicitly map database types, handle dialect-specific SQL,
and avoid assumptions about “standard SQL.” ODBC opens the door — it does not normalize what’s inside.
Real-World Experience: AS400 and DB2 in Production
This approach is not theoretical. Last year, we implemented a custom XPO provider using ODBC for
AS400 and DB2 systems in Mexico, where:
- No viable modern .NET provider existed
- The systems were deeply embedded in business operations
- ODBC was the only stable integration path
By introducing an XPO provider on top of ODBC, we were able to integrate legacy data into a modern .NET architecture,
preserve domain models and transactional behavior, and avoid rewriting or destabilizing existing systems.
The Hidden Advantage: Modern UI and AI Access
Once legacy data is exposed through XPO, something powerful happens: that data becomes immediately available to modern platforms.
- Blazor applications
- .NET MAUI mobile and desktop apps
- Background services
- Integration APIs
- AI agents and assistants
And you get this without rewriting the database, migrating the data, or changing the legacy system.
XPO becomes the adapter that allows decades-old data to participate in modern UI stacks, automated workflows,
and AI-driven experiences.
Why Not Just Use Raw ODBC?
Raw ODBC gives you rows, columns, and primitive values. XPO gives you domain objects, identity tracking,
relationships, transactions, and a consistent persistence model.
The goal is not to modernize the database. The goal is to modernize access to legacy data
so it can safely participate in modern architectures.
Closing Thought
An XPO ODBC provider is not a silver bullet. It will not magically unify SQL dialects, type systems, or database behavior.
But when used intentionally, it becomes a powerful bridge between systems that cannot be changed
and architectures that still need to evolve.
ODBC is the trick that lets you connect.
XPO is what makes that connection usable — everywhere, from Blazor UIs to AI agents.

by Joche Ojeda | Jan 22, 2025 | ADO, ADO.NET, C#, Data Synchronization, EfCore, XPO, XPO Database Replication
Working with the SyncFramework, I’ve noticed a recurring pattern when discussing schema design with customers. One crucial question that often surprises them is about their choice of primary keys: “Are you using auto-incremental integers or unique identifiers (like GUIDs)?”
Approximately 90% of users rely on auto-incremental integer primary keys. While this seems like a straightforward choice, it can create significant challenges for data synchronization. Let’s dive deep into how different database engines handle auto-increment values and why this matters for synchronization scenarios.
Database Implementation Deep Dive
SQL Server
SQL Server uses the IDENTITY property, storing current values in system tables (sys.identity_columns) and caching them in memory for performance. During restarts, it reads the last used value from these system tables. The values are managed as 8-byte numbers internally, with new ranges allocated when the cache is exhausted.
MySQL
MySQL’s InnoDB engine maintains auto-increment counters in memory and persists them to the system tablespace or table’s .frm file. After a restart, it scans the table to find the maximum used value. Each table has its own counter stored in the metadata.
PostgreSQL
PostgreSQL takes a different approach, using separate sequence objects stored in the pg_class catalog. These sequences maintain their own relation files containing crucial metadata like last value, increment, and min/max values. The sequence data is periodically checkpointed to disk for durability.
Oracle
Oracle traditionally uses sequences and triggers, with modern versions (12c+) supporting identity columns. The sequence information is stored in the SEQ$ system table, tracking the last number used, cache size, and increment values.
The Synchronization Challenge
This diversity in implementation creates several challenges for data synchronization:
- Unpredictable Sequence Generation: Even within the same database engine, gaps can occur due to rolled-back transactions or server restarts.
- Infrastructure Dependencies: The mechanisms for generating next values are deeply embedded within each database engine and aren’t easily accessible to frameworks like Entity Framework or XPO.
- Cross-Database Complexity: When synchronizing across different database instances, coordinating auto-increment values becomes even more complex.
The GUID Alternative
Using GUIDs (Globally Unique Identifiers) as primary keys offers a solution to these synchronization challenges. While GUIDs come with their own set of considerations, they provide guaranteed uniqueness across distributed systems without requiring centralized coordination.
Traditional GUID Concerns
- Index fragmentation
- Storage size
- Performance impact
Modern Solutions
These concerns have been addressed through:
- Sequential GUID generation techniques
- Improved indexing in modern databases
- Optimizations in .NET 9
Recommendations
When designing systems that require data synchronization:
- Consider using GUIDs instead of auto-increment integers for primary keys
- Evaluate sequential GUID generation for better performance
- Understand that auto-increment values, while simple, can complicate synchronization scenarios
- Plan for the infrastructure needed to maintain consistent primary key generation across your distributed system
Conclusion
The choice of primary key strategy significantly impacts your system’s ability to handle data synchronization effectively. While auto-increment integers might seem simpler at first, understanding their implementation details across different databases reveals why GUIDs often provide a more robust solution for distributed systems.
Remember: Data synchronization is not a trivial problem, and your primary key strategy plays a crucial role in its success. Take the time to evaluate your requirements and choose the appropriate approach for your specific use case.
Till next time, happy delta encoding.

by Joche Ojeda | Jan 22, 2025 | ADO.NET, C#, Data Synchronization, Database, DevExpress, XPO, XPO Database Replication
SyncFramework for XPO is a specialized implementation of our delta encoding synchronization library, designed specifically for DevExpress XPO users. It enables efficient data synchronization by tracking and transmitting only the changes between data versions, optimizing both bandwidth usage and processing time.
What’s New
- Base target framework updated to .NET 8.0
- Added compatibility with .NET 9.0
- Updated DevExpress XPO dependencies to 24.2.3
- Continued support for delta encoding synchronization
- Various performance improvements and bug fixes
Framework Compatibility
- Primary Target: .NET 8.0
- Additional Support: .NET 9.0
Our XPO implementation continues to serve the DevExpress community.
Key Features
- Seamless integration with DevExpress XPO
- Efficient delta-based synchronization
- Support for multiple database providers
- Cross-platform compatibility
- Easy integration with existing XPO and XAF applications
As always, if you own a license, you can compile the source code yourself from our GitHub repository. The framework maintains its commitment to providing reliable data synchronization for XPO applications.
Happy Delta Encoding! ?
by Joche Ojeda | Jan 21, 2025 | ADO.NET, C#, Data Synchronization, EfCore
SyncFramework Update: Now Supporting .NET 9!
SyncFramework is a C# library that simplifies data synchronization using delta encoding technology. Instead of transferring entire datasets, it efficiently synchronizes by tracking and transmitting only the changes between data versions, significantly reducing bandwidth and processing overhead.
What’s New
- All packages now target .NET 9
- BIT.Data.Sync packages updated to support the latest framework
- Entity Framework Core packages upgraded to EF Core 9
- Various minor fixes and improvements
Available Implementations
- SyncFramework for XPO: For DevExpress XPO users
- SyncFramework for Entity Framework Core: For EF Core users
Package Statistics
Our packages have been serving the community well, with steady adoption:
- BIT.Data.Sync: 2,142 downloads
- BIT.Data.Sync.AspNetCore: 1,064 downloads
- BIT.Data.Sync.AspNetCore.Xpo: 521 downloads
- BIT.Data.Sync.EfCore: 1,691 downloads
- BIT.Data.Sync.EfCore.Npgsql: 1,120 downloads
- BIT.Data.Sync.EfCore.Pomelo.MySql: 1,172 downloads
- BIT.Data.Sync.EfCore.Sqlite: 887 downloads
- BIT.Data.Sync.EfCore.SqlServer: 982 downloads
Resources
NuGet Packages
Source Code
As always, you can compile the source code yourself from our GitHub repository. The framework continues to provide reliable data synchronization across different platforms and databases.
Happy Delta Encoding! ?

by Joche Ojeda | Jan 15, 2025 | C#, dotnet, Emit, MetaProgramming, Reflection
Every programmer encounters that one technology that draws them into the darker arts of software development. For some, it’s metaprogramming; for others, it’s assembly hacking. For me, it was the mysterious world of runtime code generation through Emit in the early 2000s, during my adventures with XPO and the enigmatic Sage Accpac ERP.
The Quest Begins: A Tale of Documentation and Dark Arts
Back in the early 2000s, when the first version of XPO was released, I found myself working alongside my cousin Carlitos in our startup. Fresh from his stint as an ERP consultant in the United States, Carlitos brought with him deep knowledge of Sage Accpac, setting us on a path to provide integration services for this complex system.
Our daily bread and butter were custom reports – starting with Crystal Reports before graduating to DevExpress’s XtraReports and XtraPivotGrid. But we faced an interesting challenge: Accpac’s database was intentionally designed to resist reverse engineering, with flat tables devoid of constraints or relationships. All we had was their HTML documentation, a labyrinth of interconnected pages holding the secrets of their entity relationships.
Genesis: When Documentation Meets Dark Magic
This challenge birthed Project Genesis, my ambitious attempt to create an XPO class generator that could parse Accpac’s documentation. The first hurdle was parsing HTML – a quest that led me to CodePlex (yes, I’m dating myself here) and the discovery of HTMLAgilityPack, a remarkable tool that still serves developers today.
But the real dark magic emerged when I faced the challenge of generating classes dynamically. Buried in our library’s .NET books, I discovered the arcane art of Emit – a powerful technique for runtime assembly and class generation that would forever change my perspective on what’s possible in .NET.
Diving into the Abyss: Understanding Emit
At its core, Emit is like having a magical forge where you can craft code at runtime. Imagine being able to write code that writes more code – not just as text to be compiled later, but as actual, executable IL instructions that the CLR can run immediately.
AssemblyName assemblyName = new AssemblyName("DynamicAssembly");
AssemblyBuilder assemblyBuilder = AssemblyBuilder.DefineDynamicAssembly(
assemblyName,
AssemblyBuilderAccess.Run
);
This seemingly simple code opens a portal to one of .NET’s most powerful capabilities: dynamic assembly generation. It’s the beginning of a spell that allows you to craft types and methods from pure thought (and some carefully crafted IL instructions).
The Power and the Peril
Like all dark magic, Emit comes with its own dangers and responsibilities. When you’re generating IL directly, you’re dancing with the very fabric of .NET execution. One wrong move – one misplaced instruction – and your carefully crafted spell can backfire spectacularly.
The first rule of Emit Club is: don’t use Emit unless you absolutely have to. The second rule is: if you do use it, document everything meticulously. Your future self (and your team) will thank you.
Modern Alternatives and Evolution
Today, the .NET ecosystem offers alternatives like Source Generators that provide similar power with less risk. But understanding Emit remains valuable – it’s like knowing the fundamental laws of magic while using higher-level spells for daily work.
In my case, Project Genesis evolved beyond its original scope, teaching me crucial lessons about runtime code generation, performance optimization, and the delicate balance between power and maintainability.
Conclusion: The Magic Lives On
Twenty years later, Emit remains one of .NET’s most powerful and mysterious features. While modern development practices might steer us toward safer alternatives, understanding these fundamental building blocks of runtime code generation gives us deeper insight into the framework’s capabilities.
For those brave enough to venture into this realm, remember: with great power comes great responsibility – and the need for comprehensive unit tests. The dark magic of Emit might be seductive, but like all powerful tools, it demands respect and careful handling.