
by Joche Ojeda | Feb 9, 2026 | A.I
Last week I was in Sochi on a ski trip. Instead of skiing, I got sick.
So I spent a few days locked in a hotel room, doing what I always do when I can’t move much: working. Or at least what looks like work. In reality, it’s my hobby.
YouTube wasn’t working well there, so I downloaded a few episodes in advance. Most of them were about OpenClaw and its creator, Peter Steinberger — also known for building PSPDFKit.
What started as passive watching turned into one of those rare moments of clarity you only get when you’re forced to slow down.
Shipping Code You Don’t Read (In the Right Context)
In one of the interviews, Peter said something that immediately caught my attention: he ships code he doesn’t review.
At first that sounds reckless. But then I realized… I sometimes do the same.
However, context matters.
Most of my daily work is research and development. I build experimental systems, prototypes, and proofs of concept — either for our internal office or for exploring ideas with clients. A lot of what I write is not production software yet. It’s exploratory. It’s about testing possibilities.
In that environment, I don’t always need to read every line of generated code.
If the use case works and the tests pass, that’s often enough.
I work mainly with C#, ASP.NET, Entity Framework, and XAF from DevExpress. I know these ecosystems extremely well. So if something breaks later, I can go in and fix it myself. But most of the time, the goal isn’t to perfect the implementation — it’s to validate the idea.
That’s a crucial distinction.
When writing production code for a customer, quality and review absolutely matter. You must inspect, verify, and ensure maintainability. But when working on experimental R&D, the priority is different: speed of validation and clarity of results.
In research mode, not every line needs to be perfect. It just needs to prove whether the idea works.
Working “Without Hands”
My real goal is to operate as much as possible without hands.
By that I mean minimizing direct human interaction with implementation. I want to express intent clearly enough so agents can execute it.
If I can describe a system precisely — especially in domains I know deeply — then the agent should be able to build, test, and refine it. My role becomes guiding and validating rather than manually constructing everything.
This is where modern development is heading.
The Problem With Vibe Coding
Peter talked about something that resonated deeply: when you’re vibe coding, you produce a lot of AI slop.
You prompt. The AI generates. You run it. It fails. You tweak. You run again. Still wrong. You tweak again.
Eventually, the human gets tired.
Even when you feel close to a solution, it’s not done until it’s actually done. And manually pushing that process forward becomes exhausting.
This is where many AI workflows break down. Not because the AI can’t generate solutions — but because the loop still depends too heavily on human intervention.
Closing the Loop
The key idea is simple and powerful: agentic development works when the agent can test and correct itself.
You must close the loop.
Instead of: human → prompt → AI → human checks → repeat
You want: AI → builds → tests → detects errors → fixes → tests again → repeat
The agent needs tools to evaluate its own output.
When AI can run tests, detect failures, and iterate automatically, something shifts. The process stops being experimental prompting and starts becoming real engineering.
Spec-Driven vs Self-Correcting Systems
Spec-driven development still matters. Some people dismiss it as too close to waterfall, but every methodology has flaws.
The real evolution is combining clear specifications with self-correcting loops.
The human defines:
- The specification
- The expected behavior
- The acceptance criteria
Then the AI executes, tests, and refines until those criteria are satisfied.
The human doesn’t need to babysit every iteration. The human validates the result once the loop is closed.
Engineering vs Parasitic Ideas
There’s a concept from a book about parasitic ideas.
In social sciences, parasitic ideas can spread because they’re hard to disprove. In engineering, bad ideas fail quickly.
If you design a bridge incorrectly, it collapses. Reality provides immediate feedback.
Software — especially AI-generated software — needs the same grounding in reality. Without continuous testing and validation, generated code can drift into something that looks plausible but doesn’t work.
Closing the loop forces ideas to confront reality.
Tests are that reality.
Taking the Human Out of the Repetitive Loop
The goal isn’t removing humans entirely. It’s removing humans from repetitive validation.
The human should:
- Define the specification
- Define what “done” means
- Approve the final result
The AI should:
- Implement
- Test
- Detect issues
- Fix itself
- Repeat until success
When that happens, development becomes scalable in a new way. Not because AI writes code faster — but because AI can finish what it starts.
What I Realized in That Hotel Room
Getting sick in Sochi wasn’t part of the plan. But it forced me to slow down long enough to notice something important.
Most friction in modern development isn’t writing code. It’s closing loops.
We generate faster than we validate. We start more than we finish. We rely on humans to constantly re-check work that machines could verify themselves.
In research and experimental work, it’s fine not to inspect every line — as long as the system proves its behavior. In production work, deeper review is essential. Knowing when each approach applies is part of modern engineering maturity.
The future of agentic development isn’t just better models. It’s better loops.
Because in the end, nothing is finished until the loop is closed.
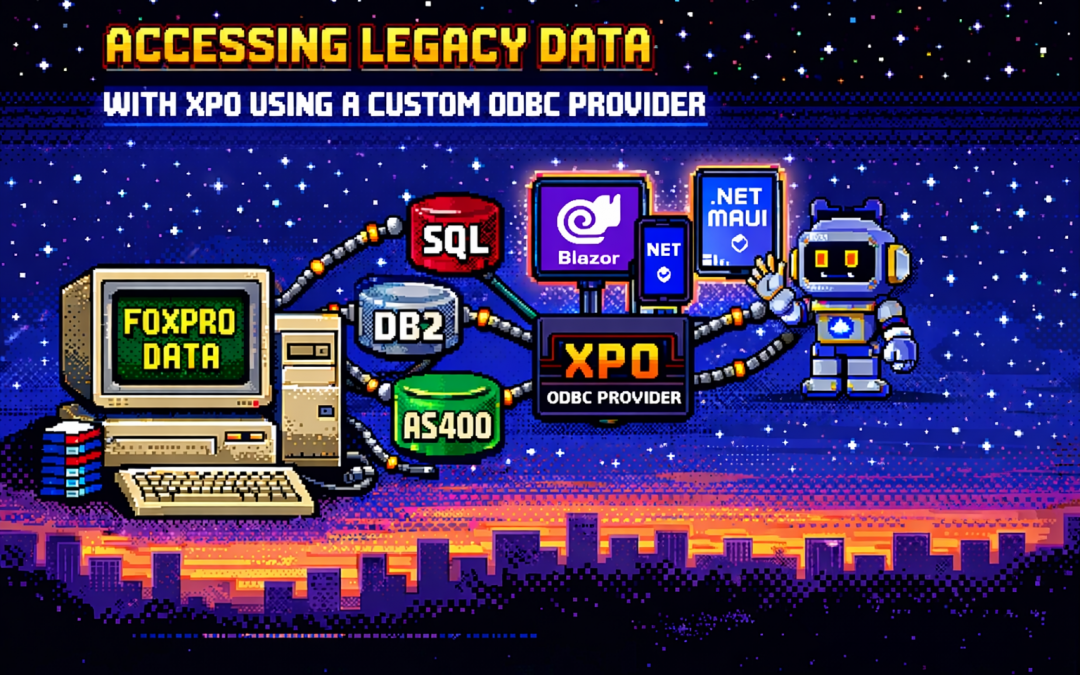
by Joche Ojeda | Dec 23, 2025 | ADO, ADO.NET, XPO
One of the recurring challenges in real-world systems is not building new software — it’s
integrating with software that already exists.
Legacy systems don’t disappear just because newer technologies are available. They survive because they work,
because they hold critical business data, and because replacing them is often risky, expensive, or simply not allowed.
This article explores a practical approach to accessing legacy data using XPO by leveraging ODBC,
not as a universal abstraction, but as a bridge when no modern provider exists.
The Reality of Legacy Systems
Many organizations still rely on systems built on technologies such as:
- FoxPro tables
- AS400 platforms
- DB2-based systems
- Proprietary or vendor-abandoned databases
In these scenarios, it’s common to find that:
- There is no modern .NET provider
- There is no ORM support
- There is an ODBC driver
That last point is crucial. ODBC often remains available long after official SDKs and providers have disappeared.
It becomes the last viable access path to critical data.
Why ORMs Struggle with Legacy Data
Modern ORMs assume a relatively friendly environment: a supported database engine, a known SQL dialect,
a compatible type system, and an actively maintained provider.
Legacy databases rarely meet those assumptions. As a result, teams are often forced to:
- Drop down to raw SQL
- Build ad-hoc data access layers
- Treat legacy data as a second-class citizen
This becomes especially painful in systems that already rely heavily on DevExpress XPO for persistence,
transactions, and domain modeling.
ODBC Is Not Magic — and That’s the Point
ODBC is often misunderstood.
Using ODBC does not mean:
- One provider works for every database
- SQL becomes standardized
- Type systems become compatible
Each ODBC-accessible database still has:
- Its own SQL dialect
- Its own limitations
- Its own data types
- Its own behavioral quirks
ODBC simply gives you a way in. It is a transport mechanism, not a universal language.
What an XPO ODBC Provider Really Is
When you implement an XPO provider on top of ODBC, you are not building a generic solution for all databases.
You are building a targeted adapter for a specific legacy system that happens to be reachable via ODBC.
This matters because ODBC is used here as a pragmatic trick:
- To connect to something you otherwise couldn’t
- To reuse an existing, stable access path
- To avoid rewriting or destabilizing legacy systems
The database still dictates the SQL dialect, supported features, and type system. Your provider must respect those constraints.
Why XPO Makes This Possible
XPO is not just an ORM — it is a provider-based persistence framework.
All SQL-capable XPO providers are built on top of a shared foundation, most notably:
ConnectionProviderSql
https://docs.devexpress.com/CoreLibraries/DevExpress.Xpo.DB.ConnectionProviderSql
This architecture allows you to reuse XPO’s core benefits:
- Object model
- Sessions and units of work
- Transaction handling
- Integration with domain logic
While customizing what legacy systems require:
- SQL generation
- Command execution
- Schema discovery
- Type mapping
Dialects and Type Systems Still Matter
Even when accessed through ODBC:
- FoxPro is not SQL Server
- DB2 is not PostgreSQL
- AS400 is not Oracle
Each system has its own:
- Date and time semantics
- Numeric precision rules
- String handling behavior
- Constraints and limits
An XPO ODBC provider must explicitly map database types, handle dialect-specific SQL,
and avoid assumptions about “standard SQL.” ODBC opens the door — it does not normalize what’s inside.
Real-World Experience: AS400 and DB2 in Production
This approach is not theoretical. Last year, we implemented a custom XPO provider using ODBC for
AS400 and DB2 systems in Mexico, where:
- No viable modern .NET provider existed
- The systems were deeply embedded in business operations
- ODBC was the only stable integration path
By introducing an XPO provider on top of ODBC, we were able to integrate legacy data into a modern .NET architecture,
preserve domain models and transactional behavior, and avoid rewriting or destabilizing existing systems.
The Hidden Advantage: Modern UI and AI Access
Once legacy data is exposed through XPO, something powerful happens: that data becomes immediately available to modern platforms.
- Blazor applications
- .NET MAUI mobile and desktop apps
- Background services
- Integration APIs
- AI agents and assistants
And you get this without rewriting the database, migrating the data, or changing the legacy system.
XPO becomes the adapter that allows decades-old data to participate in modern UI stacks, automated workflows,
and AI-driven experiences.
Why Not Just Use Raw ODBC?
Raw ODBC gives you rows, columns, and primitive values. XPO gives you domain objects, identity tracking,
relationships, transactions, and a consistent persistence model.
The goal is not to modernize the database. The goal is to modernize access to legacy data
so it can safely participate in modern architectures.
Closing Thought
An XPO ODBC provider is not a silver bullet. It will not magically unify SQL dialects, type systems, or database behavior.
But when used intentionally, it becomes a powerful bridge between systems that cannot be changed
and architectures that still need to evolve.
ODBC is the trick that lets you connect.
XPO is what makes that connection usable — everywhere, from Blazor UIs to AI agents.

by Joche Ojeda | Sep 4, 2024 | A.I, Semantic Kernel, XPO
In today’s AI-driven world, the ability to quickly and efficiently store, retrieve, and manage data is crucial for developing sophisticated applications. One tool that helps facilitate this is the Semantic Kernel, a lightweight, open-source development kit designed for integrating AI models into C#, Python, or Java applications. It enables rapid enterprise-grade solutions by serving as an effective middleware.
One of the key concepts in Semantic Kernel is memory—a collection of records, each containing a timestamp, metadata, embeddings, and a key. These memory records can be stored in various ways, depending on how you implement the interfaces. This flexibility allows you to define the storage mechanism, which means you can choose any database solution that suits your needs.
In this blog post, we’ll walk through how to use the IMemoryStore interface in Semantic Kernel and implement a custom memory store using DevExpress XPO, an ORM (Object-Relational Mapping) tool that can interact with over 14 database engines with a single codebase.
Why Use DevExpress XPO ORM?
DevExpress XPO is a powerful, free-to-use ORM created by DevExpress that abstracts the complexities of database interactions. It supports a wide range of database engines such as SQL Server, MySQL, SQLite, Oracle, and many others, allowing you to write database-independent code. This is particularly helpful when dealing with a distributed or multi-environment system where different databases might be used.
By using XPO, we can seamlessly create, update, and manage memory records in various databases, making our application more flexible and scalable.
Implementing a Custom Memory Store with DevExpress XPO
To integrate XPO with Semantic Kernel’s memory management, we’ll implement a custom memory store by defining a database entry class and a database interaction class. Then, we’ll complete the process by implementing the IMemoryStore interface.
Step 1: Define a Database Entry Class
Our first step is to create a class that represents the memory record. In this case, we’ll define an XpoDatabaseEntry class that maps to a database table where memory records are stored.
public class XpoDatabaseEntry : XPLiteObject {
private string _oid;
private string _collection;
private string _timestamp;
private string _embeddingString;
private string _metadataString;
private string _key;
[Key(false)]
public string Oid { get; set; }
public string Key { get; set; }
public string MetadataString { get; set; }
public string EmbeddingString { get; set; }
public string Timestamp { get; set; }
public string Collection { get; set; }
protected override void OnSaving() {
if (this.Session.IsNewObject(this)) {
this.Oid = Guid.NewGuid().ToString();
}
base.OnSaving();
}
}
This class extends XPLiteObject from the XPO library, which provides methods to manage the record lifecycle within the database.
Step 2: Create a Database Interaction Class
Next, we’ll define an XpoDatabase class to abstract the interaction with the data store. This class provides methods for creating tables, inserting, updating, and querying records.
internal sealed class XpoDatabase {
public Task CreateTableAsync(IDataLayer conn) {
using (Session session = new(conn)) {
session.UpdateSchema(new[] { typeof(XpoDatabaseEntry).Assembly });
session.CreateObjectTypeRecords(new[] { typeof(XpoDatabaseEntry).Assembly });
}
return Task.CompletedTask;
}
// Other database operations such as CreateCollectionAsync, InsertOrIgnoreAsync, etc.
}
This class acts as a bridge between Semantic Kernel and the database, allowing us to manage memory entries without having to write complex SQL queries.
Step 3: Implement the IMemoryStore Interface
Finally, we implement the IMemoryStore interface, which is responsible for defining how the memory store behaves. This includes methods like UpsertAsync, GetAsync, and DeleteCollectionAsync.
public class XpoMemoryStore : IMemoryStore, IDisposable {
public static async Task ConnectAsync(string connectionString) {
var memoryStore = new XpoMemoryStore(connectionString);
await memoryStore._dbConnector.CreateTableAsync(memoryStore._dataLayer).ConfigureAwait(false);
return memoryStore;
}
public async Task CreateCollectionAsync(string collectionName) {
await this._dbConnector.CreateCollectionAsync(this._dataLayer, collectionName).ConfigureAwait(false);
}
// Other methods for interacting with memory records
}
The XpoMemoryStore class takes advantage of XPO’s ORM features, making it easy to create collections, store and retrieve memory records, and perform batch operations. Since Semantic Kernel doesn’t care where memory records are stored as long as the interfaces are correctly implemented, you can now store your memory records in any of the databases supported by XPO.
Advantages of Using XPO with Semantic Kernel
- Database Independence: You can switch between multiple databases without changing your codebase.
- Scalability: XPO’s ability to manage complex relationships and large datasets makes it ideal for enterprise-grade solutions.
- ORM Abstraction: With XPO, you avoid writing SQL queries and focus on high-level operations like creating and updating objects.
Conclusion
In this blog post, we’ve demonstrated how to integrate DevExpress XPO ORM with the Semantic Kernel using the IMemoryStore interface. This approach allows you to store AI-driven memory records in a wide variety of databases while maintaining a flexible, scalable architecture.
In future posts, we’ll explore specific use cases and how you can leverage this memory store in real-world applications. For the complete implementation, you can check out my GitHub fork.
Stay tuned for more insights and examples!

by Joche Ojeda | Sep 4, 2024 | A.I, Semantic Kernel
In our continued exploration of Semantic Kernel, we shift focus towards its memory capabilities, specifically diving into the Microsoft.SemanticKernel.Memory Namespace. Here, we’ll discuss the critical components that allow for efficient memory management and how you can integrate your own custom memory stores for AI applications. One of the standout implementations within this namespace is the VolatileMemoryStore, but equally important is understanding how any class that implements IMemoryStore can serve as a backend for SemanticTextMemory.
What Is “Memory” in Semantic Kernel?
Before we dive into the technical details, let’s clarify what we mean by “memory” within the Semantic Kernel framework. When we refer to “memory,” we are not talking about RAM or the typical computer memory used to store data for a short period of time. In the context of Semantic Kernel, memory refers to a record or a unit of information, much like a piece of information you might recall from personal experience. This could be an entry stored in a memory store, which later can be retrieved, searched, or modified.
The Microsoft.SemanticKernel.Memory Namespace
This namespace contains several important classes that serve as the foundation for memory management in the kernel. These include but are not limited to:
- MemoryRecord: The primary schema for memory storage.
- MemoryRecordMetadata: Handles metadata associated with a memory entry.
- SemanticTextMemory: Implements methods to save, retrieve, and search for text-based information in a memory store.
- VolatileMemoryStore: A simple, in-memory implementation of a memory store, useful for short-term storage during runtime.
- IMemoryStore: The interface that defines how a memory store should behave. Any class that implements this interface can act as a memory backend for SemanticTextMemory.
VolatileMemoryStore: A Simple Example
The VolatileMemoryStore is an example of a non-persistent memory store. It operates in-memory and is well-suited for temporary storage needs that do not require long-term persistence. The class implements IMemoryStore, which means that it provides all the essential methods for storing and retrieving records in the memory.
Some of its key methods include:
- CreateCollectionAsync: Used to create a collection of records.
- DeleteCollectionAsync: Deletes a collection from the memory.
- UpsertAsync: Inserts or updates a memory record.
- GetAsync: Retrieves a memory record by ID.
- GetNearestMatchesAsync: Finds memory records that are semantically closest to the input.
Given that the VolatileMemoryStore does not offer persistence, it is primarily suited for short-lived applications. However, because it implements IMemoryStore, it can be replaced with a more persistent memory backend if required.
IMemoryStore: The Key to Custom Memory Implementations
The power of the Semantic Kernel lies in its flexibility. As long as a class implements the IMemoryStore interface, it can be used as a memory backend for the kernel’s memory management. This means that you are not limited to using the VolatileMemoryStore. Instead, you can develop your own custom memory stores by following the pattern established by this class.
For instance, if you need to store memory records in a database, or in a distributed cloud storage solution, you can implement the IMemoryStore interface and define how records should be inserted, retrieved, and managed within your custom store. Once implemented, this custom memory store can be used by the SemanticTextMemory class to manage text-based memories.
SemanticTextMemory: Bringing It All Together
At the core of managing memory in the Semantic Kernel is the SemanticTextMemory class. This class interacts with your memory store to save, retrieve, and search for text-based memory records. Whether you’re using the VolatileMemoryStore or a custom implementation of IMemoryStore, the SemanticTextMemory class serves as the interface that facilitates text-based memory operations.
Key methods include:
- SaveInformationAsync: Saves information into the memory store, maintaining a copy of the original data.
- SearchAsync: Allows for searching the memory based on specific criteria, such as finding semantically similar records.
- GetCollectionsAsync: Retrieves available collections of memories from the memory store.
Why Flexible Memory Stores Matter
The flexibility provided by the IMemoryStore interface is critical because it allows developers to integrate the Semantic Kernel into a wide variety of systems, from small-scale in-memory applications to enterprise-grade solutions that require persistent storage across distributed environments. Whether you’re building an AI agent that needs to “remember” user inputs between sessions or a bot that needs to recall relevant details during an interaction, the memory system in the Semantic Kernel is built to scale with your needs.
Final Thoughts
In the world of AI, memory is a crucial component that makes AI agents more intelligent and capable of handling complex interactions. With the Microsoft.SemanticKernel.Memory Namespace, developers have a flexible, scalable solution for memory management. Whether you’re working with the in-memory VolatileMemoryStore or designing your custom memory backend, the IMemoryStore interface ensures seamless integration with the Semantic Kernel’s memory system.
By understanding the relationship between IMemoryStore, VolatileMemoryStore, and SemanticTextMemory, you can harness the full potential of the Semantic Kernel to create more sophisticated AI-driven applications.
Memory Types in Semantic Kernel

by Joche Ojeda | Apr 28, 2024 | A.I
Introduction to Semantic Kernel
Hey there, fellow curious minds! Let’s talk about something exciting today—Semantic Kernel. But don’t worry, we’ll keep it as approachable as your favorite coffee shop chat.
What Exactly Is Semantic Kernel?
Imagine you’re in a magical workshop, surrounded by tools. Well, Semantic Kernel is like that workshop, but for developers. It’s an open-source Software Development Kit (SDK) that lets you create AI agents. These agents aren’t secret spies; they’re little programs that can answer questions, perform tasks, and generally make your digital life easier.
Here’s the lowdown:
- Open-Source: Think of it as a community project. People from all walks of tech life contribute to it, making it better and more powerful.
- Software Development Kit (SDK): Fancy term, right? But all it means is that it’s a set of tools for building software. Imagine it as your AI Lego set.
- Agents: Nope, not James Bond. These are like your personal AI sidekicks. They’re here to assist you, not save the world (although that would be cool).
A Quick History Lesson
About a year ago, Semantic Kernel stepped onto the stage. Since then, it’s been striding confidently, like a seasoned performer. Here are some backstage highlights:
- GitHub Stardom: On March 17th, 2023, it made its grand entrance on GitHub. And guess what? It got more than 17,000 stars! (Around 18.2. right now) That’s like being the coolest kid in the coding playground.
- Downloads Galore: The C# kernel (don’t worry, we’ll explain what that is) had 1000000+ NuGet downloads. It’s like everyone wanted a piece of the action.
- VS Code Extension: Over 25,000 downloads! Imagine it as a magical wand for your code editor.
And hey, the .Net kernel even threw a party—it reached a 1.0 release! The Python and Java kernels are close behind with their 1.0 Release Candidates. It’s like they’re all graduating from AI university.
Why Should You Care?
Now, here’s the fun part. Why should you, someone with a lifetime of wisdom and curiosity, care about this?
- Microsoft Magic: Semantic Kernel loves hanging out with Microsoft products. It’s like they’re best buddies. So, when you use it, you get to tap into the power of Microsoft’s tech universe. Fancy, right? Learn more
- No Code Rewrite Drama: Imagine you have a favorite recipe (let’s say it’s your grandma’s chocolate chip cookies). Now, imagine you want to share it with everyone. Semantic Kernel lets you do that without rewriting the whole recipe. You just add a sprinkle of AI magic! Check it out
- LangChain vs. Semantic Kernel: These two are like rival chefs. Both want to cook up AI goodness. But while LangChain (built around Python and JavaScript) comes with a full spice rack of tools, Semantic Kernel is more like a secret ingredient. It’s lightweight and includes not just Python but also C#. Plus, it’s like the Assistant API—no need to fuss over memory and context windows. Just cook and serve!
So, my fabulous friend, whether you’re a seasoned developer or just dipping your toes into the AI pool, Semantic Kernel has your back. It’s like having a friendly AI mentor who whispers, “You got this!” And with its growing community and constant updates, Semantic Kernel is leading the way in AI development.
Remember, you don’t need a PhD in computer science to explore this—it’s all about curiosity, creativity, and a dash of Semantic Kernel magic. ?✨
Ready to dive in? Check out the Semantic Kernel GitHub repository for the latest updates