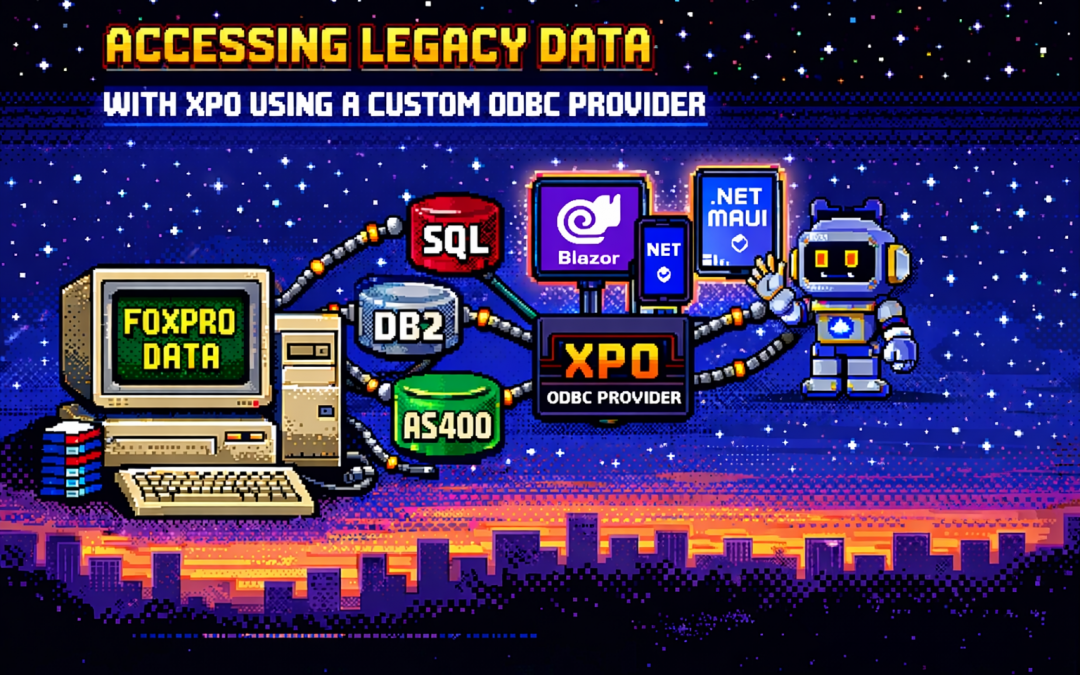
by Joche Ojeda | Dec 23, 2025 | ADO, ADO.NET, XPO
One of the recurring challenges in real-world systems is not building new software — it’s
integrating with software that already exists.
Legacy systems don’t disappear just because newer technologies are available. They survive because they work,
because they hold critical business data, and because replacing them is often risky, expensive, or simply not allowed.
This article explores a practical approach to accessing legacy data using XPO by leveraging ODBC,
not as a universal abstraction, but as a bridge when no modern provider exists.
The Reality of Legacy Systems
Many organizations still rely on systems built on technologies such as:
- FoxPro tables
- AS400 platforms
- DB2-based systems
- Proprietary or vendor-abandoned databases
In these scenarios, it’s common to find that:
- There is no modern .NET provider
- There is no ORM support
- There is an ODBC driver
That last point is crucial. ODBC often remains available long after official SDKs and providers have disappeared.
It becomes the last viable access path to critical data.
Why ORMs Struggle with Legacy Data
Modern ORMs assume a relatively friendly environment: a supported database engine, a known SQL dialect,
a compatible type system, and an actively maintained provider.
Legacy databases rarely meet those assumptions. As a result, teams are often forced to:
- Drop down to raw SQL
- Build ad-hoc data access layers
- Treat legacy data as a second-class citizen
This becomes especially painful in systems that already rely heavily on DevExpress XPO for persistence,
transactions, and domain modeling.
ODBC Is Not Magic — and That’s the Point
ODBC is often misunderstood.
Using ODBC does not mean:
- One provider works for every database
- SQL becomes standardized
- Type systems become compatible
Each ODBC-accessible database still has:
- Its own SQL dialect
- Its own limitations
- Its own data types
- Its own behavioral quirks
ODBC simply gives you a way in. It is a transport mechanism, not a universal language.
What an XPO ODBC Provider Really Is
When you implement an XPO provider on top of ODBC, you are not building a generic solution for all databases.
You are building a targeted adapter for a specific legacy system that happens to be reachable via ODBC.
This matters because ODBC is used here as a pragmatic trick:
- To connect to something you otherwise couldn’t
- To reuse an existing, stable access path
- To avoid rewriting or destabilizing legacy systems
The database still dictates the SQL dialect, supported features, and type system. Your provider must respect those constraints.
Why XPO Makes This Possible
XPO is not just an ORM — it is a provider-based persistence framework.
All SQL-capable XPO providers are built on top of a shared foundation, most notably:
ConnectionProviderSql
https://docs.devexpress.com/CoreLibraries/DevExpress.Xpo.DB.ConnectionProviderSql
This architecture allows you to reuse XPO’s core benefits:
- Object model
- Sessions and units of work
- Transaction handling
- Integration with domain logic
While customizing what legacy systems require:
- SQL generation
- Command execution
- Schema discovery
- Type mapping
Dialects and Type Systems Still Matter
Even when accessed through ODBC:
- FoxPro is not SQL Server
- DB2 is not PostgreSQL
- AS400 is not Oracle
Each system has its own:
- Date and time semantics
- Numeric precision rules
- String handling behavior
- Constraints and limits
An XPO ODBC provider must explicitly map database types, handle dialect-specific SQL,
and avoid assumptions about “standard SQL.” ODBC opens the door — it does not normalize what’s inside.
Real-World Experience: AS400 and DB2 in Production
This approach is not theoretical. Last year, we implemented a custom XPO provider using ODBC for
AS400 and DB2 systems in Mexico, where:
- No viable modern .NET provider existed
- The systems were deeply embedded in business operations
- ODBC was the only stable integration path
By introducing an XPO provider on top of ODBC, we were able to integrate legacy data into a modern .NET architecture,
preserve domain models and transactional behavior, and avoid rewriting or destabilizing existing systems.
The Hidden Advantage: Modern UI and AI Access
Once legacy data is exposed through XPO, something powerful happens: that data becomes immediately available to modern platforms.
- Blazor applications
- .NET MAUI mobile and desktop apps
- Background services
- Integration APIs
- AI agents and assistants
And you get this without rewriting the database, migrating the data, or changing the legacy system.
XPO becomes the adapter that allows decades-old data to participate in modern UI stacks, automated workflows,
and AI-driven experiences.
Why Not Just Use Raw ODBC?
Raw ODBC gives you rows, columns, and primitive values. XPO gives you domain objects, identity tracking,
relationships, transactions, and a consistent persistence model.
The goal is not to modernize the database. The goal is to modernize access to legacy data
so it can safely participate in modern architectures.
Closing Thought
An XPO ODBC provider is not a silver bullet. It will not magically unify SQL dialects, type systems, or database behavior.
But when used intentionally, it becomes a powerful bridge between systems that cannot be changed
and architectures that still need to evolve.
ODBC is the trick that lets you connect.
XPO is what makes that connection usable — everywhere, from Blazor UIs to AI agents.

by Joche Ojeda | Dec 23, 2025 | ADO, ADO.NET, C#
When I started working with computers, one of the tools that shaped my way of thinking as a developer was FoxPro.
At the time, FoxPro felt like a complete universe: database engine, forms, reports, and business logic all integrated into a single environment.
Looking back, FoxPro was effectively an application framework from the past—long before that term became common.
Accessing FoxPro data usually meant choosing between two paths:
- Direct FoxPro access – fast, tightly integrated, and fully aware of FoxPro’s features
- ODBC – a standardized way to access the data from outside the FoxPro ecosystem
This article focuses on that second option.
What Is ODBC?
ODBC (Open Database Connectivity) is a standardized API for accessing databases.
Instead of applications talking directly to a specific database engine, they talk to an ODBC driver,
which translates generic database calls into database-specific commands.
The promise was simple:
One API, many databases.
And for its time, this was revolutionary.
Supported Operating Systems and Use Cases
ODBC is still relevant today and supported across major platforms:
- Windows – native support, mature tooling
- Linux – via unixODBC and vendor drivers
- macOS – supported through driver managers
Typical use cases include:
- Legacy systems that must remain stable
- Reporting and BI tools
- Data migration and ETL pipelines
- Cross-vendor integrations
- Long-lived enterprise systems
ODBC excels where interoperability matters more than elegance.
The Lowest Common Denominator Problem
Although ODBC is a standard, it does not magically unify databases.
Each database has its own:
- SQL dialect
- Data types
- Functions
- Performance characteristics
ODBC standardizes access, not behavior.
You can absolutely open an ODBC connection and still:
- Call native database functions
- Use vendor-specific SQL
- Rely on engine-specific behavior
This makes ODBC flexible—but not truly database-agnostic.
ODBC vs True Abstraction Layers
This is where ODBC differs from ORMs or persistence frameworks that aim for full abstraction.
- ODBC: Gives you a common door and does not prevent database-specific usage
- ORM-style frameworks: Try to hide database differences and enforce a common conceptual model
ODBC does not protect you from database specificity—it permits it.
ODBC in .NET: Avoiding Native Database Dependencies
This is an often-overlooked advantage of ODBC, especially in .NET applications.
ADO.NET is interface-driven:
IDbConnectionIDbCommandIDataReader
However, each database requires its own concrete provider:
- SQL Server
- Oracle
- DB2
- Pervasive
- PostgreSQL
- MySQL
Each provider introduces:
- Native binaries
- Vendor SDKs
- Version compatibility issues
- Deployment complexity
Your code may be abstract — your deployment is not.
ODBC as a Binary Abstraction Layer
When using ODBC in .NET, your application depends on one provider only:
System.Data.Odbc
Database-specific dependencies are moved:
- Out of your application
- Into the operating system
- Into driver configuration
This turns ODBC into a dependency firewall.
Minimal .NET Example: ODBC vs Native Provider
Native ADO.NET Provider (Example: SQL Server)
using System.Data.SqlClient;
using var connection =
new SqlConnection("Server=.;Database=AppDb;Trusted_Connection=True;");
connection.Open();
Implications:
- Requires SQL Server client libraries
- Ties the binary to SQL Server
- Changing database = new provider + rebuild
ODBC Provider (Database-Agnostic Binary)
using System.Data.Odbc;
using var connection =
new OdbcConnection("DSN=AppDatabase");
connection.Open();
Implications:
- Same binary works for SQL Server, Oracle, DB2, etc.
- No vendor-specific DLLs in the app
- Database choice is externalized
The SQL inside the connection may still be database-specific — but your application binary is not.
Trade-Offs (And Why They’re Acceptable)
Using ODBC means:
- Fewer vendor-specific optimizations
- Possible performance differences
- Reliance on driver quality
But in exchange, you gain:
- Simpler deployments
- Easier migrations
- Longer application lifespan
- Reduced vendor lock-in
For many enterprise systems, this is a strategic win.
What’s Next – Phase 2: Customer Polish
Phase 1 is about making it work.
Phase 2 is about making it survivable for customers.
In Phase 2, ODBC shines by enabling:
- Zero-code database switching
- Cleaner installers
- Fewer runtime surprises
- Support for customer-controlled environments
- Reduced friction in on-prem deployments
This is where architecture meets reality.
Customers don’t care how elegant your abstractions are — they care that your software runs on their infrastructure without drama.
Project References
Minimal and explicit:
System.Data
System.Data.Odbc
Optional (native providers, when required):
System.Data.SqlClient
Oracle.ManagedDataAccess
IBM.Data.DB2
ODBC allows these to become optional, not mandatory.
Closing Thought
ODBC never promised purity.
It promised compatibility.
Just like FoxPro once gave us everything in one place, ODBC gave us a way out — without burning everything down.
Decades later, that trade-off still matters.

by Joche Ojeda | Jan 22, 2025 | ADO, ADO.NET, C#, Data Synchronization, EfCore, XPO, XPO Database Replication
Working with the SyncFramework, I’ve noticed a recurring pattern when discussing schema design with customers. One crucial question that often surprises them is about their choice of primary keys: “Are you using auto-incremental integers or unique identifiers (like GUIDs)?”
Approximately 90% of users rely on auto-incremental integer primary keys. While this seems like a straightforward choice, it can create significant challenges for data synchronization. Let’s dive deep into how different database engines handle auto-increment values and why this matters for synchronization scenarios.
Database Implementation Deep Dive
SQL Server
SQL Server uses the IDENTITY property, storing current values in system tables (sys.identity_columns) and caching them in memory for performance. During restarts, it reads the last used value from these system tables. The values are managed as 8-byte numbers internally, with new ranges allocated when the cache is exhausted.
MySQL
MySQL’s InnoDB engine maintains auto-increment counters in memory and persists them to the system tablespace or table’s .frm file. After a restart, it scans the table to find the maximum used value. Each table has its own counter stored in the metadata.
PostgreSQL
PostgreSQL takes a different approach, using separate sequence objects stored in the pg_class catalog. These sequences maintain their own relation files containing crucial metadata like last value, increment, and min/max values. The sequence data is periodically checkpointed to disk for durability.
Oracle
Oracle traditionally uses sequences and triggers, with modern versions (12c+) supporting identity columns. The sequence information is stored in the SEQ$ system table, tracking the last number used, cache size, and increment values.
The Synchronization Challenge
This diversity in implementation creates several challenges for data synchronization:
- Unpredictable Sequence Generation: Even within the same database engine, gaps can occur due to rolled-back transactions or server restarts.
- Infrastructure Dependencies: The mechanisms for generating next values are deeply embedded within each database engine and aren’t easily accessible to frameworks like Entity Framework or XPO.
- Cross-Database Complexity: When synchronizing across different database instances, coordinating auto-increment values becomes even more complex.
The GUID Alternative
Using GUIDs (Globally Unique Identifiers) as primary keys offers a solution to these synchronization challenges. While GUIDs come with their own set of considerations, they provide guaranteed uniqueness across distributed systems without requiring centralized coordination.
Traditional GUID Concerns
- Index fragmentation
- Storage size
- Performance impact
Modern Solutions
These concerns have been addressed through:
- Sequential GUID generation techniques
- Improved indexing in modern databases
- Optimizations in .NET 9
Recommendations
When designing systems that require data synchronization:
- Consider using GUIDs instead of auto-increment integers for primary keys
- Evaluate sequential GUID generation for better performance
- Understand that auto-increment values, while simple, can complicate synchronization scenarios
- Plan for the infrastructure needed to maintain consistent primary key generation across your distributed system
Conclusion
The choice of primary key strategy significantly impacts your system’s ability to handle data synchronization effectively. While auto-increment integers might seem simpler at first, understanding their implementation details across different databases reveals why GUIDs often provide a more robust solution for distributed systems.
Remember: Data synchronization is not a trivial problem, and your primary key strategy plays a crucial role in its success. Take the time to evaluate your requirements and choose the appropriate approach for your specific use case.
Till next time, happy delta encoding.

by Joche Ojeda | Jan 20, 2025 | ADO, ADO.NET, Database, dotnet
When I first encountered the challenge of migrating hundreds of Visual Basic 6 reports to .NET, I never imagined it would lead me down a path of discovering specialized data analytics tools. Today, I want to share my experience with ADOMD.NET and how it could have transformed our reporting challenges, even though we couldn’t implement it due to our database constraints.
The Challenge: The Sales Gap Report
The story begins with a seemingly simple report called “Sales Gap.” Its purpose was critical: identify periods when regular customers stopped purchasing specific items. For instance, if a customer typically bought 10 units monthly from January to May, then suddenly stopped in June and July, sales representatives needed to understand why.
This report required complex queries across multiple transactional tables:
- Invoicing
- Sales
- Returns
- Debits
- Credits
Initially, the report took about a minute to run. As our data grew, so did the execution time—eventually reaching an unbearable 15 minutes. We were stuck with a requirement to use real-time transactional data, making traditional optimization techniques like data warehousing off-limits.
Enter ADOMD.NET: A Specialized Solution
ADOMD.NET (ActiveX Data Objects Multidimensional .NET) emerged as a potential solution. Here’s why it caught my attention:
Key Features:
-
Multidimensional Analysis
Unlike traditional SQL queries, ADOMD.NET uses MDX (Multidimensional Expressions), specifically designed for analytical queries. Here’s a basic example:
string mdxQuery = @"
SELECT
{[Measures].[Sales Amount]} ON COLUMNS,
{[Date].[Calendar Year].MEMBERS} ON ROWS
FROM [Sales Cube]
WHERE [Product].[Category].[Electronics]";
-
Performance Optimization
ADOMD.NET is built for analytical workloads, offering better performance for complex calculations and aggregations. It achieves this through:
- Specialized data structures for multidimensional analysis
- Efficient handling of hierarchical data
- Built-in support for complex calculations
-
Advanced Analytics Capabilities
The tool supports sophisticated analysis patterns like:
string mdxQuery = @"
WITH MEMBER [Measures].[GrowthVsPreviousYear] AS
([Measures].[Sales Amount] -
([Measures].[Sales Amount], [Date].[Calendar Year].PREVMEMBER)
)/([Measures].[Sales Amount], [Date].[Calendar Year].PREVMEMBER)
SELECT
{[Measures].[Sales Amount], [Measures].[GrowthVsPreviousYear]}
ON COLUMNS...";
Lessons Learned
While we couldn’t implement ADOMD.NET due to our use of Pervasive Database instead of SQL Server, the investigation taught me valuable lessons about report optimization:
- The importance of choosing the right tools for analytical workloads
- The limitations of running complex analytics on transactional databases
- The value of specialized query languages for different types of data analysis
Modern Applications
Today, ADOMD.NET continues to be relevant for organizations using:
- SQL Server Analysis Services (SSAS)
- Azure Analysis Services
- Power BI Premium datasets
If I were facing the same challenge today with SQL Server, ADOMD.NET would be my go-to solution for:
- Complex sales analysis
- Customer behavior tracking
- Performance-intensive analytical reports
Conclusion
While our specific situation with Pervasive Database prevented us from using ADOMD.NET, it remains a powerful tool for organizations using Microsoft’s analytics stack. The experience taught me that sometimes the solution isn’t about optimizing existing queries, but about choosing the right specialized tools for analytical workloads.
Remember: Just because you can run analytics on your transactional database doesn’t mean you should. Tools like ADOMD.NET exist for a reason, and understanding when to use them can save countless hours of optimization work and provide better results for your users.

by Joche Ojeda | May 26, 2023 | ADO, ADO.NET, ORM
ORM is a technique for converting data between incompatible type systems using object-oriented programming languages. In the context of database management, an ORM provides a way to interact with a database using objects and methods, rather than writing raw SQL queries. This allows for a higher level of abstraction, reducing the amount of repetitive and error-prone code that needs to be written, and making it easier to maintain the application.
ORM and RDBMS
Object-Relational Mapping (ORM) tools and RDBMS have different approaches to querying data.
RDBMS uses SQL which is a low-level, language-agnostic query language that is used to communicate with relational databases. When using SQL, developers write raw SQL statements that are executed directly against the database. The results of the query are then returned in the form of a table or set of tables, which must be manually mapped to objects in code.
On the other hand, an ORM tool abstracts the underlying SQL code, allowing developers to query data using an object-oriented syntax that is similar to the programming language used in the application.
The ORM tool automatically generates the necessary SQL statements and executes them against the database, and then maps the resulting data to objects in code.
One of the main advantages of using an ORM tool is that it eliminates the need for manual data mapping, making it easier for developers to write data-access code and reducing the chances of errors. Additionally, because ORM tools use a higher-level syntax, they can also be more intuitive and easier to use than raw SQL.
However, ORM tools can also introduce performance overhead and complexity, as they must manage the mapping between the database and objects in code. In some cases, raw SQL may still be necessary to achieve the desired performance or to perform complex data manipulation that is not supported by the ORM tool.
As a simple example we will use the database table “customer”. It has four columns:
- id: A unique identifier for each customer, usually an auto-incrementing integer.
- name: The name of the customer, represented as a string.
- email: The email address of the customer, represented as a string.
- address: The address of the customer, represented as a string.
Each row in the table represents a single customer, and each column represents a piece of information about that customer. The table is used to store the data for the customer objects created in the code. The ORM maps the table to a class, allowing you to interact with the data using objects and methods.
Here is an example of how an ORM can map a database table named “customer” to a class representation in C#:
class Customer
{
public int Id { get; set; }
public string Name { get; set; }
public string Email { get; set; }
public string Address { get; set; }
}
// The ORM maps the customer table in the database to the Customer class.
// The columns of the table become properties of the class, and each row in the table becomes an instance of the class.
In this example, the ORM abstracts away the underlying database and provides a high-level, object-oriented interface for working with the data.
The main advantage of using an ORM (Object-Relational Mapping) instead of using the direct results from the database in C# is increased abstraction and convenience. This provides several benefits:
- Improved readability and maintainability: Code written using an ORM is easier to understand and maintain, as it uses a higher-level, object-oriented interface, rather than raw SQL.
- Reduced code duplication: With an ORM, you can encapsulate database-related logic in reusable classes and methods, reducing the amount of repetitive code that needs to be written.
- Increased safety: An ORM can help prevent SQL injection attacks by automatically escaping user input, ensuring that data is safely inserted into the database.
- Increased flexibility: An ORM provides a layer of abstraction between the application code and the database, allowing you to switch between different database systems without changing the application code.
Direct database access
var connection = new SqlConnection("connection string");
connection. Open();
var command = new SqlCommand("SELECT * FROM customers", connection);
var reader = command.ExecuteReader();
List < Customer > customers = new List < Customer > ();
while (reader. Read()) {
var customer = new Customer {
Id = reader.GetInt32(0),
Name = reader.GetString(1),
Email = reader.GetString(2),
Address = reader.GetString(3)
};
customers. Add(customer);
}
reader.Close();
connection. Close();
ORM access
var customers = ORM.Query<Customer>().ToList();
As you can see, using an ORM simplifies the code and makes it more readable, while also providing additional safety and flexibility benefits.
Different types of O.R.M
Micro O.R.M
A micro ORM is a type of Object-Relational Mapping (ORM) library that is designed to be lightweight and simple, offering a minimalistic and easy-to-use interface for interacting with a relational database.
Micro ORMs are typically faster and require less configuration and setup than full-featured ORMs, but also have fewer features and less advanced capabilities.
Micro ORMs provide a higher-level, object-oriented interface for working with databases, allowing you to interact with the data using classes, properties, and methods, rather than writing raw SQL queries as well but they typically offer a smaller, more focused set of features than full-featured ORMs, including support for basic CRUD (Create, Read, Update, Delete) operations, and often provide basic querying and data mapping capabilities.
Micro ORMs are often used in small projects or in environments where performance is critical. They are also commonly used in microservices and other architectures that prioritize simplicity, scalability, and ease of deployment.
Full-fledged Object-Relational Mapping (ORM)
A full-fledged Object-Relational Mapping (ORM) is a software library that provides a convenient and efficient way of working with relational databases.
A full-fledged ORM typically has the following characteristics:
- Object Mapping: The ORM maps database tables to object-oriented classes, allowing developers to interact with the database using objects instead of tables.
- Query Generation: The ORM generates SQL statements based on the object-oriented query syntax, reducing the need for developers to write and manage raw SQL.
- Data Validation: The ORM provides built-in data validation and type checking, reducing the risk of incorrect data being written to the database.
- Caching: The ORM may provide caching of data to improve performance, reducing the number of databases round trips.
- Transactions: The ORM supports transactions, making it easier to ensure that database operations are atomic and consistent.
- Database Independence: The ORM is typically designed to be database agnostic, allowing developers to switch between different database platforms without changing the application code.
- Lazy Loading: The ORM supports lazy loading, which can improve performance by loading related objects only when they are needed.
- Performance: A comprehensive ORM is crafted to deliver satisfactory performance, and we can customize each aspect of the ORM to enhance its performance. However, it is important to note that a solid understanding of how the ORM operates is necessary to make these customizations effective.
One of the disadvantages of using an Object-Relational Mapping (ORM) tool is that you may not be able to create specialized, fine-tuned queries with the same level of precision as you can with raw SQL. This is because ORMs typically abstract the underlying database and expose a higher-level, more object-oriented API for querying data.
For example, it may not be possible to use specific SQL constructs, such as subqueries or window functions, in your ORM queries. Additionally, some ORMs may not provide a way to optimize query performance, such as by specifying index hints or controlling the execution plan.
As a result, developers who need to write specialized or fine-tuned queries may find it easier and more efficient to write raw SQL statements. However, this comes at the cost of having to manually manage the mapping between the database and the application, which is one of the main benefits of using an ORM in the first place.
ORM and Querying data
Before the existence of LINQ, Object-Relational Mapping (ORM) tools used a proprietary query language to query data. This meant that each ORM had to invent its own criteria or query language, and developers had to learn the specific syntax of each ORM in order to write queries.
For example, in XPO, developers used the Criteria API to write queries. The Criteria API allowed developers to write queries in a type-safe and intuitive manner, but the syntax was specific to XPO and not easily transferable to other ORMs.
Similarly, in NHibernate, developers used the Hibernate Query Language (HQL) to write queries. Like the Criteria API in XPO, HQL was a proprietary query language specific to NHibernate, and developers had to learn the syntax in order to write queries.
This lack of a standardized query language was one of the main limitations of ORMs before the introduction of LINQ. LINQ provided a common, language-agnostic query language that could be used with a variety of data sources, including relational databases. This made it easier for developers to write data-access code, as they only had to learn one query language, regardless of the ORM or data source being used.
The introduction of LINQ, a new era for O.R.M in dot net
Language Integrated Query (LINQ) is a Microsoft .NET Framework component that was introduced in .NET Framework 3.5. It is a set of language and library features that enables developers to write querying and manipulation operations over data in a more intuitive and readable way.
LINQ was created to address the need for a more unified and flexible approach to querying and manipulating data in .NET applications. Prior to LINQ, developers had to write separate code to access and manipulate data in different data sources, such as databases, XML documents, and in-memory collections. This resulted in a fragmented and difficult-to-maintain codebase, with different syntax and approaches for different data sources.
With LINQ, developers can now write a single querying language that works with a wide range of data sources, including databases, XML, in-memory collections, and more.
In addition, LINQ also provides a number of other benefits, such as improved performance, better type safety, and integrated support for data processing operations, such as filtering, grouping, and aggregating.
using (var context = new DbContext())
{
var selectedCustomers = context.Customers
.Where(c => c.Address.Contains("San Salvador"))
.Select(c => new
{
c.Id,
c.Name,
c.Email,
c.Address
})
.ToList();
foreach(var customer in selectedCustomers)
foreach(var customer in selectedCustomers)
{
Console.WriteLine($"Id: {customer.Id}, Name: {customer.Name}, Email: {customer.Email}, Address: {customer. Address}");
}
}
And that’s all for this post, until next time ))
We are excited to announce that we are currently in the process of writing a comprehensive book about DevExpress XPO. As we work on this project, we believe it is essential to involve our readers and gather their valuable feedback. Therefore, we have decided to share articles from the book as we complete them, giving you an opportunity to provide input and suggestions that we can consider for inclusion in the final release. Keep in mind that the content presented is subject to change. We greatly appreciate your participation in this collaborative effort.
Related Articles
ADO The origin of data access in .NET
Relational database systems: the holy grail of data