It’s Sunday — so maybe it’s time to write an article to break the flow I’ve been in lately. I’ve been deep into researching design patterns for Oqtane, the web application framework created by Shaun Walker.
Today I woke up really early, around 4:30 a.m. I went downstairs, made coffee, and decided to play around with some applications I had on my list. One of them was HotKey Typer by James Montemagno.
I ran it for the first time and instantly loved it. It’s super simple and useful — but I had a problem. I started using glasses a few years ago, and I generally have trouble with small UI elements on the computer. I usually work at 150% scaling. Unfortunately, James’s app has a fixed window size, so everything looked cut off.
Since I’ve been coding a lot lately, I figured it would be an easy fix. I tweaked it — and it worked! Everything looked better, but a bit too large, so I adjusted it again… and again… and again. Before I knew it, I had turned it into a totally different application.
I was vibe coding for four or five hours straight. In the end, I added a lot of new functionality because I genuinely loved the app and the idea behind it. I added sets (or collections) — basically groups of snippets you can assign to keys 1–9. Then I added autosave, a settings screen, and a reset option for the collections. Every time I finished one feature, I said, “Just one more thing.” Five minutes turned into five hours.
When I was done, I recorded a demo video. It was a lot of fun — and the result was genuinely useful. I even want to create an installer for myself so I can easily reinstall it if I ever reformat my computer. (I used to be that guy who formatted his PC every month. Not anymore… but you never know.)
Lessons From Vibe Coding
I learned a lot from this little experiment. I’ve been vibe coding nonstop for about three months now — I’ve even used up all my Copilot credits before the 25th of the month more than once! Vibe coding is a lot of fun, but it can easily spiral out of control and take you in the wrong direction.
Next week, I want to change my approach a bit — maybe follow a more structured pattern.
Another thing this reminded me of is how important it is to work in a team. My business partner, José Javier Columbie, has always helped me with that. We’ve been working together for about 10 years now. I’m the kind of developer who keeps rewriting, refactoring, optimizing, making things faster, reusable, turning them into plugins or frameworks — and sometimes the original task was actually quite small.
That’s where Javier comes in. He’s the one who says, “José, it’s done. This is what they asked for, and this is what we’re delivering.” He keeps me grounded. Every developer needs that — or at least needs to learn how to set that boundary for themselves.
Final Thoughts
So that’s my takeaway from today’s vibe coding session: have fun, but know when to stop.
I’ll include below the links to:
James Montemagno’s original HotKey Typer repository
If you hang out around developers long enough, you’ll notice we don’t just use tools — we nickname them, mispronounce them, and sometimes turn them into full-blown mascots. Here are three favorites: WSL, SQL, and GitHub Copilot’s Spec Kit.
WSL → “Weasel”
English reality: WSL stands for Windows Subsystem for Linux.
Nickname: Said quickly as “double-u S L,” it echoes weasel, so the meme stuck.
Spanish (El Salvador / Latin America): In El Salvador and many Latin American countries, the letter W is read as “doble be” (not doble u). So WSL is pronounced “doble be, ese, ele.”
SQL → “Sequel”
English reality: SQL stands for Structured Query Language.
Pronunciation: Both “S-Q-L” and “sequel” are used in English.
Spanish (LatAm): Most developers say it letter by letter: “ese cu e ele.” Bilingual teams sometimes mix in “sequel.”
Spec Kit → “Speckified” (Spooky Spell)
English reality: GitHub Copilot’s Spec Kit helps scaffold code from specs.
Community fun: Projects get “speckified,” a word that mischievously echoes “spookified.” Our playful mascot idea is a wizard enchanting a codebase: You have been Speckified!
Spanish (LatAm): Phonetically, SPEC is “ese, pe, e, ce.” In casual talk many devs just say “espec” (es-pek) to keep the pun alive.
Quick Reference (Latin American / El Salvador Spanish)
Acronym
English Pronunciation
Spanish (LatAm / El Salvador) Phonetics
Nickname / Mascot
WSL
“double-u S L” (sounds like weasel)
“doble be, ese, ele”
Weasel
SQL
“S-Q-L” or “sequel”
“ese cu e ele”
Sequel Robot
SPEC
“spec” → “speckified”
“ese, pe, e, ce” (or “espec”)
Spec Wizard (spell)
Why This Matters
These playful twists — weasel, sequel robot, speckified wizard — show how dev culture works:
Acronyms turn into characters.
English vs. Spanish pronunciations add layers of humor.
Memes make otherwise dry tools easier to talk about.
Next time someone says their project is fully speckified on WSL with SQL, you might be hearing about a weasel, a robot, and a wizard casting spooky spec spells.
Most of us have fallen into the trap of what I like to call vibe coding. It’s that moment when you’re excited about an idea, you open your editor, call on your favorite AI assistant, and just… vibe. You throw half-baked requirements at the model, it spits out a lot of code, and for a while, it feels like progress.
The problem is, vibe coding usually leads to garbage code, wasted time, and mounting frustration. I know this because I recently spent six hours vibe coding a feature I could have completed in under ten minutes—once I stopped vibing and started documenting.
What Is Vibe Coding?
Vibe coding is coding without a plan. It’s asking an AI to build something from incomplete context, hoping it magically fills in the blanks.
It can look like:
Pasting vague prompts into an LLM: “Build me an activity stream module.”
Copy-pasting stack overflow snippets without really understanding them.
Letting AI hallucinate structures, dependencies, and business rules you never specified.
And it feels productive, because you see code flying across your screen. But what’s really happening is that the AI is guessing. It compiles imaginary versions of your system in its “head,” tries different routes, and produces lots of words that look like solutions but don’t actually fit your framework or needs. The result: chaos disguised as progress.
My Oqtane Activity Stream Story
Here’s a concrete example.
I wanted to build an activity stream—basically, a social-network-style feed—on top of Oqtane, a .NET-based CMS. Now, I know the domain of activity streams really well, but I decided to test how far I could get if I let AI build an Oqtane module for me as if I knew nothing about the framework.
For six hours, I vibe coded. I kept prompting the AI with fragments like:
“Make an Oqtane module for an activity feed.”
“Add a timeline of user events.”
“Hook this up to Oqtane’s structure.”
And the AI did what it does best: it generated code. Lots of it. But the code didn’t fit the Oqtane module lifecycle. It missed important patterns, created unnecessary complexity, and left me stuck in a trial-and-error spiral.
Six hours later, I had nothing usable. Just a pile of messy code and a headache.
The Switch to Vibe Documenting
Then I stepped back. Instead of continuing to let the AI guess, I wrote down what I already knew:
How an Oqtane module is structured.
What the activity stream needed to display.
The key integration points with the CMS.
In other words, I documented the requirements as if I were teaching someone new to Oqtane. Then, I fed that documentation to the AI.
The result? In about eight minutes, I had a clean, working Oqtane module for my activity stream. No trial and error. No hallucinated patterns. Just code that fit perfectly into the framework.
Why Documentation Beats Guesswork
The lesson was obvious: the AI is only as good as the clarity of its input. Documentation gives it structure, reducing the entropy of the problem. Without it, you’re effectively asking the AI to be psychic. With it, you’re giving the AI a blueprint it can execute on with precision.
Think about it this way:
Vibe coding = lots of code, little progress.
Vibe documenting = clear plan, fast progress.
The irony is that documentation often feels slower up front—but it saves exponential time later. In my case, it turned six wasted hours into eight minutes of actual productivity.
The Human Programmer’s Role
This experience reinforced something important: the human programmer isn’t going anywhere. Our role is to act as the bridge between vague ideas and structured requirements.
We’re the ones who take messy, half-formed thoughts and turn them into clear steps. That’s not just busywork—that’s the essence of engineering. Once those steps exist, the AI can handle the grunt work of coding far more effectively than it can guess at our intentions.
In other words: humans reduce chaos; AI executes clarity.
The Guru Lesson
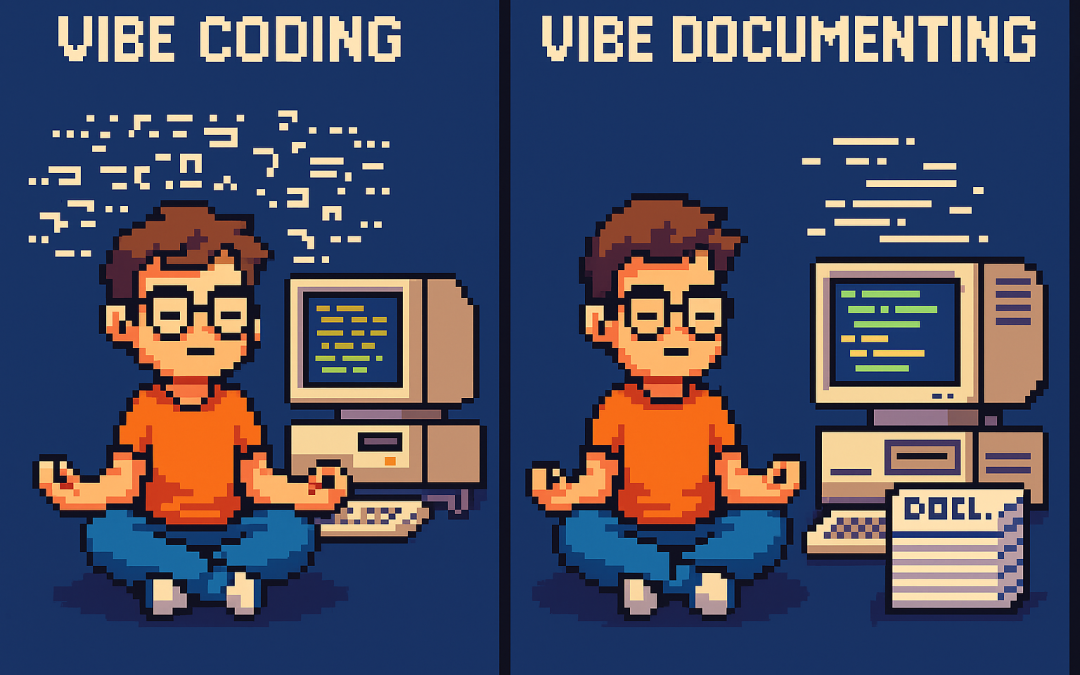
I like to think of it as a guru’s journey. On one side, the vibe coder sits cross-legged in front of a retro computer, letting chaotic lines of code swirl around them. On the other, the vibe documenter floats serenely, armed with neat stacks of documentation, watching clean code flow effortlessly.
The wisdom is simple: don’t vibe code. Vibe document. It’s the difference between six hours of chaos and eight minutes of clarity.
Conclusion
AI coding assistants are incredible, but they’re not mind readers. If you skip documentation, you’ll spend hours wrestling with hallucinated code. If you take the time to document, you’ll unlock the real power of AI: rapid, reliable execution.
So the next time you feel the urge to vibe code, pause. Write down your requirements. Document your framework. Then let the AI do what it does best: build from clarity.
Because vibe coding wastes time—but vibe documenting saves it.
In modern application development, managing user authentication and authorization across multiple systems has become a significant challenge. Keycloak emerges as a compelling solution to address these identity management complexities, offering particular value for .NET developers seeking flexible authentication options.
What is Keycloak?
Keycloak is an open-source Identity and Access Management (IAM) solution developed by Red Hat. It functions as a centralized authentication and authorization server that manages user identities and controls access across multiple applications and services within an organization.
Rather than each application handling its own user authentication independently, Keycloak provides a unified identity provider that enables Single Sign-On (SSO) capabilities. Users authenticate once with Keycloak and gain seamless access to all authorized applications without repeated login prompts.
Core Functionality
Keycloak serves as a comprehensive identity management platform that handles several critical functions. It manages user authentication through various methods including traditional username/password combinations, multi-factor authentication, and social login integration with providers like Google, Facebook, and GitHub.
Beyond authentication, Keycloak provides robust authorization capabilities, controlling what authenticated users can access within applications through role-based access control and fine-grained permissions. The platform supports industry-standard protocols including OpenID Connect, OAuth 2.0, and SAML 2.0, ensuring compatibility with a wide range of applications and services.
User federation capabilities allow Keycloak to integrate with existing user directories such as LDAP and Active Directory, enabling organizations to leverage their current user stores rather than requiring complete migration to new systems.
The Problem Keycloak Addresses
Modern users often experience “authentication fatigue” – the exhaustion that comes from repeatedly logging into multiple systems throughout their workday. A typical enterprise user might need to authenticate with email systems, project management tools, CRM platforms, cloud storage, HR portals, and various internal applications, each potentially requiring different credentials and authentication flows.
This fragmentation leads to several problems: users struggle with password management across multiple systems, productivity decreases due to time spent on authentication processes, security risks increase as users resort to password reuse or weak passwords, and IT support costs rise due to frequent password reset requests.
Keycloak eliminates these friction points by providing seamless SSO while simultaneously improving security through centralized identity management and consistent security policies.
Keycloak and .NET Integration
For .NET developers, Keycloak offers excellent compatibility through its support of standard authentication protocols. The platform’s adherence to OpenID Connect and OAuth 2.0 standards means it integrates naturally with .NET applications using Microsoft’s built-in authentication middleware.
.NET Core and .NET 5+ applications can integrate with Keycloak using the Microsoft.AspNetCore.Authentication.OpenIdConnect package, while older .NET Framework applications can utilize OWIN middleware. Blazor applications, both Server and WebAssembly variants, support the same integration patterns, and Web APIs can be secured using JWT tokens issued by Keycloak.
The integration process typically involves configuring authentication middleware in the .NET application to communicate with Keycloak’s endpoints, establishing client credentials, and defining appropriate scopes and redirect URIs. This standards-based approach ensures that .NET developers can leverage their existing knowledge of authentication patterns while benefiting from Keycloak’s advanced identity management features.
Benefits for .NET Development
Keycloak offers several advantages for .NET developers and organizations. As an open-source solution, it provides cost-effectiveness compared to proprietary alternatives while offering extensive customization capabilities that proprietary solutions often restrict.
The platform reduces development time by handling complex authentication scenarios out-of-the-box, allowing developers to focus on business logic rather than identity management infrastructure. Security benefits include centralized policy management, regular security updates, and implementation of industry best practices.
Keycloak’s vendor-neutral approach provides flexibility for organizations using multiple cloud providers or seeking to avoid vendor lock-in. The solution scales effectively through clustered deployments and supports high-availability configurations suitable for enterprise environments.
Comparison with Microsoft Solutions
When compared to Microsoft’s identity offerings like Entra ID (formerly Azure AD), Keycloak presents different trade-offs. Microsoft’s solutions provide seamless integration within the Microsoft ecosystem and offer managed services with minimal maintenance requirements, but come with subscription costs and potential vendor lock-in considerations.
Keycloak, conversely, offers complete control over deployment and data, extensive customization options, and freedom from licensing fees. However, it requires organizations to manage their own infrastructure and maintain the necessary technical expertise.
When Keycloak Makes Sense
Keycloak represents an ideal choice for .NET developers and organizations that prioritize flexibility, cost control, and customization capabilities. It’s particularly suitable for scenarios involving multiple cloud providers, integration with diverse systems, or requirements for extensive branding and workflow customization.
Organizations with the technical expertise to manage infrastructure and those seeking vendor independence will find Keycloak’s open-source model advantageous. The solution also appeals to teams building applications that need to work across different technology stacks and cloud environments.
Conclusion
Keycloak stands as a robust, flexible identity management solution that integrates seamlessly with .NET applications through standard authentication protocols. Its open-source nature, comprehensive feature set, and standards-based approach make it a compelling alternative to proprietary identity management solutions.
For .NET developers seeking powerful identity management capabilities without vendor lock-in, Keycloak provides the tools necessary to implement secure, scalable authentication solutions while maintaining the flexibility to adapt to changing requirements and diverse technology environments.
Imagine you’re running a blog website and want to display a list of all blogs along with how many posts each one has. The N+1 problem is a common database performance issue that happens when your application makes way too many database trips to get this simple information.
Our Test Database Setup
Our test suite creates a realistic blog scenario with:
3 different blogs
Multiple posts for each blog
Comments on posts
Tags associated with blogs
This mirrors real-world applications where data is interconnected and needs to be loaded efficiently.
Test Case 1: The Classic N+1 Problem (Lazy Loading)
What it does: This test demonstrates how “lazy loading” can accidentally create the N+1 problem. Lazy loading sounds helpful – it automatically fetches related data when you need it. But this convenience comes with a hidden cost.
The Code:
[Test]
public void Test_N_Plus_One_Problem_With_Lazy_Loading()
{
var blogs = _context.Blogs.ToList(); // Query 1: Load blogs
foreach (var blog in blogs)
{
var postCount = blog.Posts.Count; // Each access triggers a query!
TestLogger.WriteLine($"Blog: {blog.Title} - Posts: {postCount}");
}
}
The SQL Queries Generated:
-- Query 1: Load all blogs
SELECT "b"."Id", "b"."CreatedDate", "b"."Description", "b"."Title"
FROM "Blogs" AS "b"
-- Query 2: Load posts for Blog 1 (triggered by lazy loading)
SELECT "p"."Id", "p"."BlogId", "p"."Content", "p"."PublishedDate", "p"."Title"
FROM "Posts" AS "p"
WHERE "p"."BlogId" = 1
-- Query 3: Load posts for Blog 2 (triggered by lazy loading)
SELECT "p"."Id", "p"."BlogId", "p"."Content", "p"."PublishedDate", "p"."Title"
FROM "Posts" AS "p"
WHERE "p"."BlogId" = 2
-- Query 4: Load posts for Blog 3 (triggered by lazy loading)
SELECT "p"."Id", "p"."BlogId", "p"."Content", "p"."PublishedDate", "p"."Title"
FROM "Posts" AS "p"
WHERE "p"."BlogId" = 3
The Problem: 4 total queries (1 + 3) – Each time you access blog.Posts.Count, lazy loading triggers a separate database trip.
Test Case 2: Alternative N+1 Demonstration
What it does: This test manually recreates the N+1 pattern to show exactly what’s happening, even if lazy loading isn’t working properly.
The Code:
[Test]
public void Test_N_Plus_One_Problem_Alternative_Approach()
{
var blogs = _context.Blogs.ToList(); // Query 1
foreach (var blog in blogs)
{
// This explicitly loads posts for THIS blog only (simulates lazy loading)
var posts = _context.Posts.Where(p => p.BlogId == blog.Id).ToList();
TestLogger.WriteLine($"Loaded {posts.Count} posts for blog {blog.Id}");
}
}
The Lesson: This explicitly demonstrates the N+1 pattern with manual queries. The result is identical to lazy loading – one query per blog plus the initial blogs query.
Test Case 3: N+1 vs Include() – Side by Side Comparison
What it does: This is the money shot – a direct comparison showing the dramatic difference between the problematic approach and the solution.
The Bad Code (N+1):
// BAD: N+1 Problem
var blogsN1 = _context.Blogs.ToList(); // Query 1
foreach (var blog in blogsN1)
{
var posts = _context.Posts.Where(p => p.BlogId == blog.Id).ToList(); // Queries 2,3,4...
}
The Good Code (Include):
// GOOD: Include() Solution
var blogsInclude = _context.Blogs
.Include(b => b.Posts)
.ToList(); // Single query with JOIN
foreach (var blog in blogsInclude)
{
// No additional queries needed - data is already loaded!
var postCount = blog.Posts.Count;
}
The SQL Queries:
Bad Approach (Multiple Queries):
-- Same 4 separate queries as shown in Test Case 1
Good Approach (Single Query):
SELECT "b"."Id", "b"."CreatedDate", "b"."Description", "b"."Title",
"p"."Id", "p"."BlogId", "p"."Content", "p"."PublishedDate", "p"."Title"
FROM "Blogs" AS "b"
LEFT JOIN "Posts" AS "p" ON "b"."Id" = "p"."BlogId"
ORDER BY "b"."Id"
What it does: This test removes any doubt by explicitly demonstrating the N+1 pattern with clear step-by-step output.
The Code:
[Test]
public void Test_Guaranteed_N_Plus_One_Problem()
{
var blogs = _context.Blogs.ToList(); // Query 1
int queryCount = 1;
foreach (var blog in blogs)
{
queryCount++;
// This explicitly demonstrates the N+1 pattern
var posts = _context.Posts.Where(p => p.BlogId == blog.Id).ToList();
TestLogger.WriteLine($"Loading posts for blog '{blog.Title}' (Query #{queryCount})");
}
}
Why it’s useful: This ensures we can always see the problem clearly by manually executing the problematic pattern, making it impossible to miss.
Test Case 5: Eager Loading with Include()
What it does: Shows the correct way to load related data upfront using Include().
The Code:
[Test]
public void Test_Eager_Loading_With_Include()
{
var blogsWithPosts = _context.Blogs
.Include(b => b.Posts)
.ToList();
foreach (var blog in blogsWithPosts)
{
// No additional queries - data already loaded!
TestLogger.WriteLine($"Blog: {blog.Title} - Posts: {blog.Posts.Count}");
}
}
The SQL Query:
SELECT "b"."Id", "b"."CreatedDate", "b"."Description", "b"."Title",
"p"."Id", "p"."BlogId", "p"."Content", "p"."PublishedDate", "p"."Title"
FROM "Blogs" AS "b"
LEFT JOIN "Posts" AS "p" ON "b"."Id" = "p"."BlogId"
ORDER BY "b"."Id"
The Benefit: One database trip loads everything. When you access blog.Posts.Count, the data is already there.
Test Case 6: Multiple Includes with ThenInclude()
What it does: Demonstrates loading deeply nested data – blogs → posts → comments – all in one query.
The Code:
[Test]
public void Test_Multiple_Includes_With_ThenInclude()
{
var blogsWithPostsAndComments = _context.Blogs
.Include(b => b.Posts)
.ThenInclude(p => p.Comments)
.ToList();
foreach (var blog in blogsWithPostsAndComments)
{
foreach (var post in blog.Posts)
{
// All data loaded in one query!
TestLogger.WriteLine($"Post: {post.Title} - Comments: {post.Comments.Count}");
}
}
}
The SQL Query:
SELECT "b"."Id", "b"."CreatedDate", "b"."Description", "b"."Title",
"p"."Id", "p"."BlogId", "p"."Content", "p"."PublishedDate", "p"."Title",
"c"."Id", "c"."Author", "c"."Content", "c"."CreatedDate", "c"."PostId"
FROM "Blogs" AS "b"
LEFT JOIN "Posts" AS "p" ON "b"."Id" = "p"."BlogId"
LEFT JOIN "Comments" AS "c" ON "p"."Id" = "c"."PostId"
ORDER BY "b"."Id", "p"."Id"
The Challenge: Loading three levels of data in one optimized query instead of potentially hundreds of separate queries.
Test Case 7: Projection with Select()
What it does: Shows how to load only the specific data you actually need instead of entire objects.
The Code:
[Test]
public void Test_Projection_With_Select()
{
var blogData = _context.Blogs
.Select(b => new
{
BlogTitle = b.Title,
PostCount = b.Posts.Count(),
RecentPosts = b.Posts
.OrderByDescending(p => p.PublishedDate)
.Take(2)
.Select(p => new { p.Title, p.PublishedDate })
})
.ToList();
}
The SQL Query (from our test output):
SELECT "b"."Title", (
SELECT COUNT(*)
FROM "Posts" AS "p"
WHERE "b"."Id" = "p"."BlogId"), "b"."Id", "t0"."Title", "t0"."PublishedDate", "t0"."Id"
FROM "Blogs" AS "b"
LEFT JOIN (
SELECT "t"."Title", "t"."PublishedDate", "t"."Id", "t"."BlogId"
FROM (
SELECT "p0"."Title", "p0"."PublishedDate", "p0"."Id", "p0"."BlogId",
ROW_NUMBER() OVER(PARTITION BY "p0"."BlogId" ORDER BY "p0"."PublishedDate" DESC) AS "row"
FROM "Posts" AS "p0"
) AS "t"
WHERE "t"."row" <= 2
) AS "t0" ON "b"."Id" = "t0"."BlogId"
ORDER BY "b"."Id", "t0"."BlogId", "t0"."PublishedDate" DESC
Why it matters: This query only loads the specific fields needed, uses window functions for efficiency, and calculates counts in the database rather than loading full objects.
Test Case 8: Split Query Strategy
What it does: Demonstrates an alternative approach where one large JOIN is split into multiple optimized queries.
The Code:
[Test]
public void Test_Split_Query()
{
var blogs = _context.Blogs
.AsSplitQuery()
.Include(b => b.Posts)
.Include(b => b.Tags)
.ToList();
}
The SQL Queries (from our test output):
-- Query 1: Load blogs
SELECT "b"."Id", "b"."CreatedDate", "b"."Description", "b"."Title"
FROM "Blogs" AS "b"
ORDER BY "b"."Id"
-- Query 2: Load posts (automatically generated)
SELECT "p"."Id", "p"."BlogId", "p"."Content", "p"."PublishedDate", "p"."Title", "b"."Id"
FROM "Blogs" AS "b"
INNER JOIN "Posts" AS "p" ON "b"."Id" = "p"."BlogId"
ORDER BY "b"."Id"
-- Query 3: Load tags (automatically generated)
SELECT "t"."Id", "t"."Name", "b"."Id"
FROM "Blogs" AS "b"
INNER JOIN "BlogTag" AS "bt" ON "b"."Id" = "bt"."BlogsId"
INNER JOIN "Tags" AS "t" ON "bt"."TagsId" = "t"."Id"
ORDER BY "b"."Id"
When to use it: When JOINing lots of related data creates one massive, slow query. Split queries break this into several smaller, faster queries.
Test Case 9: Filtered Include()
What it does: Shows how to load only specific related data – in this case, only recent posts from the last 15 days.
The Code:
[Test]
public void Test_Filtered_Include()
{
var cutoffDate = DateTime.Now.AddDays(-15);
var blogsWithRecentPosts = _context.Blogs
.Include(b => b.Posts.Where(p => p.PublishedDate > cutoffDate))
.ToList();
}
The SQL Query:
SELECT "b"."Id", "b"."CreatedDate", "b"."Description", "b"."Title",
"p"."Id", "p"."BlogId", "p"."Content", "p"."PublishedDate", "p"."Title"
FROM "Blogs" AS "b"
LEFT JOIN "Posts" AS "p" ON "b"."Id" = "p"."BlogId" AND "p"."PublishedDate" > @cutoffDate
ORDER BY "b"."Id"
The Efficiency: Only loads posts that meet the criteria, reducing data transfer and memory usage.
Test Case 10: Explicit Loading
What it does: Demonstrates manually controlling when related data gets loaded.
The Code:
[Test]
public void Test_Explicit_Loading()
{
var blogs = _context.Blogs.ToList(); // Load blogs only
// Now explicitly load posts for all blogs
foreach (var blog in blogs)
{
_context.Entry(blog)
.Collection(b => b.Posts)
.Load();
}
}
The SQL Queries:
-- Query 1: Load blogs
SELECT "b"."Id", "b"."CreatedDate", "b"."Description", "b"."Title"
FROM "Blogs" AS "b"
-- Query 2: Explicitly load posts for blog 1
SELECT "p"."Id", "p"."BlogId", "p"."Content", "p"."PublishedDate", "p"."Title"
FROM "Posts" AS "p"
WHERE "p"."BlogId" = 1
-- Query 3: Explicitly load posts for blog 2
SELECT "p"."Id", "p"."BlogId", "p"."Content", "p"."PublishedDate", "p"."Title"
FROM "Posts" AS "p"
WHERE "p"."BlogId" = 2
-- ... and so on
When useful: When you sometimes need related data and sometimes don’t. You control exactly when the additional database trip happens.
Test Case 11: Batch Loading Pattern
What it does: Shows a clever technique to avoid N+1 by loading all related data in one query, then organizing it in memory.
The Code:
[Test]
public void Test_Batch_Loading_Pattern()
{
var blogs = _context.Blogs.ToList(); // Query 1
var blogIds = blogs.Select(b => b.Id).ToList();
// Single query to get all posts for all blogs
var posts = _context.Posts
.Where(p => blogIds.Contains(p.BlogId))
.ToList(); // Query 2
// Group posts by blog in memory
var postsByBlog = posts.GroupBy(p => p.BlogId).ToDictionary(g => g.Key, g => g.ToList());
}
The SQL Queries:
-- Query 1: Load all blogs
SELECT "b"."Id", "b"."CreatedDate", "b"."Description", "b"."Title"
FROM "Blogs" AS "b"
-- Query 2: Load ALL posts for ALL blogs in one query
SELECT "p"."Id", "p"."BlogId", "p"."Content", "p"."PublishedDate", "p"."Title"
FROM "Posts" AS "p"
WHERE "p"."BlogId" IN (1, 2, 3)
The Result: Just 2 queries total, regardless of how many blogs you have. Data organization happens in memory.
Test Case 12: Performance Comparison
What it does: Puts all the approaches head-to-head to show their relative performance.
The Code:
[Test]
public void Test_Performance_Comparison()
{
// N+1 Problem (Multiple Queries)
var blogs1 = _context.Blogs.ToList();
foreach (var blog in blogs1)
{
var count = blog.Posts.Count(); // Triggers separate query
}
// Eager Loading (Single Query)
var blogs2 = _context.Blogs
.Include(b => b.Posts)
.ToList();
// Projection (Minimal Data)
var blogSummaries = _context.Blogs
.Select(b => new { b.Title, PostCount = b.Posts.Count() })
.ToList();
}
The SQL Queries Generated:
N+1 Problem: 4 separate queries (as shown in previous examples)
Eager Loading: 1 JOIN query (as shown in Test Case 5)
Projection: 1 optimized query with subquery:
SELECT "b"."Title", (
SELECT COUNT(*)
FROM "Posts" AS "p"
WHERE "b"."Id" = "p"."BlogId") AS "PostCount"
FROM "Blogs" AS "b"
Real-World Performance Impact
Let’s scale this up to see why it matters:
Small Application (10 blogs):
N+1 approach: 11 queries (≈110ms)
Optimized approach: 1 query (≈10ms)
Time saved: 100ms
Medium Application (100 blogs):
N+1 approach: 101 queries (≈1,010ms)
Optimized approach: 1 query (≈10ms)
Time saved: 1 second
Large Application (1000 blogs):
N+1 approach: 1001 queries (≈10,010ms)
Optimized approach: 1 query (≈10ms)
Time saved: 10 seconds
Key Takeaways
The N+1 problem gets exponentially worse as your data grows
Lazy loading is convenient but dangerous – it can hide performance problems
Include() is your friend for loading related data efficiently
Projection is powerful when you only need specific fields
Different problems need different solutions – there’s no one-size-fits-all approach
SQL query inspection is crucial – always check what queries your ORM generates
The Bottom Line
This test suite shows that small changes in how you write database queries can transform a slow, database-heavy operation into a fast, efficient one. The difference between a frustrated user waiting 10 seconds for a page to load and a happy user getting instant results often comes down to understanding and avoiding the N+1 problem.
The beauty of these tests is that they use real database queries with actual SQL output, so you can see exactly what’s happening under the hood. Understanding these patterns will make you a more effective developer and help you build applications that stay fast as they grow.
You can find the source for this article in my here