
by Joche Ojeda | Feb 24, 2025 | Linux, Postgres, SyncFrameworkV2, Ubuntu, WSL
After a problematic Windows update on my Surface computer that prevented me from compiling .NET applications, I spent days trying various fixes without success. Eventually, I had to format my computer and start fresh. This meant setting up everything again – Visual Studio, testing databases, and all the other development tools.To make future setups easier, I created a collection of WSL 2 scripts that automate the installation of tools I frequently use, like PostgreSQL and MySQL for testing purposes. While these scripts contain some practices that wouldn’t be recommended for production (like hardcoded passwords), they’re specifically designed for testing environments. The passwords used are already present in the sync framework source code, so there’s no additional security risk.I decided to share these scripts not as a perfect solution, but as a starting point for others who might need to set up similar testing environments. You can use them as inspiration for your own scripts or modify the default passwords to match your needs.
Note that these are specifically for testing purposes – particularly for working with the sync framework – and the hardcoded credentials should never be used in a production environment.
https://github.com/egarim/MyWslScripts
LDAP Scripts
MyWslScripts/ldap-setup.sh at master · egarim/MyWslScripts
MyWslScripts/add-ldap-user.sh at master · egarim/MyWslScripts
MySQL
MyWslScripts/install_mysql.sh at master · egarim/MyWslScripts
Postgres
MyWslScripts/install_postgres.sh at master · egarim/MyWslScripts
Redis
MyWslScripts/redis-install.sh at master · egarim/MyWslScripts
Let me know if you’d like me to share the actual scripts in a follow-up post!

by Joche Ojeda | Jan 22, 2025 | ADO, ADO.NET, C#, Data Synchronization, EfCore, XPO, XPO Database Replication
Working with the SyncFramework, I’ve noticed a recurring pattern when discussing schema design with customers. One crucial question that often surprises them is about their choice of primary keys: “Are you using auto-incremental integers or unique identifiers (like GUIDs)?”
Approximately 90% of users rely on auto-incremental integer primary keys. While this seems like a straightforward choice, it can create significant challenges for data synchronization. Let’s dive deep into how different database engines handle auto-increment values and why this matters for synchronization scenarios.
Database Implementation Deep Dive
SQL Server
SQL Server uses the IDENTITY property, storing current values in system tables (sys.identity_columns) and caching them in memory for performance. During restarts, it reads the last used value from these system tables. The values are managed as 8-byte numbers internally, with new ranges allocated when the cache is exhausted.
MySQL
MySQL’s InnoDB engine maintains auto-increment counters in memory and persists them to the system tablespace or table’s .frm file. After a restart, it scans the table to find the maximum used value. Each table has its own counter stored in the metadata.
PostgreSQL
PostgreSQL takes a different approach, using separate sequence objects stored in the pg_class catalog. These sequences maintain their own relation files containing crucial metadata like last value, increment, and min/max values. The sequence data is periodically checkpointed to disk for durability.
Oracle
Oracle traditionally uses sequences and triggers, with modern versions (12c+) supporting identity columns. The sequence information is stored in the SEQ$ system table, tracking the last number used, cache size, and increment values.
The Synchronization Challenge
This diversity in implementation creates several challenges for data synchronization:
- Unpredictable Sequence Generation: Even within the same database engine, gaps can occur due to rolled-back transactions or server restarts.
- Infrastructure Dependencies: The mechanisms for generating next values are deeply embedded within each database engine and aren’t easily accessible to frameworks like Entity Framework or XPO.
- Cross-Database Complexity: When synchronizing across different database instances, coordinating auto-increment values becomes even more complex.
The GUID Alternative
Using GUIDs (Globally Unique Identifiers) as primary keys offers a solution to these synchronization challenges. While GUIDs come with their own set of considerations, they provide guaranteed uniqueness across distributed systems without requiring centralized coordination.
Traditional GUID Concerns
- Index fragmentation
- Storage size
- Performance impact
Modern Solutions
These concerns have been addressed through:
- Sequential GUID generation techniques
- Improved indexing in modern databases
- Optimizations in .NET 9
Recommendations
When designing systems that require data synchronization:
- Consider using GUIDs instead of auto-increment integers for primary keys
- Evaluate sequential GUID generation for better performance
- Understand that auto-increment values, while simple, can complicate synchronization scenarios
- Plan for the infrastructure needed to maintain consistent primary key generation across your distributed system
Conclusion
The choice of primary key strategy significantly impacts your system’s ability to handle data synchronization effectively. While auto-increment integers might seem simpler at first, understanding their implementation details across different databases reveals why GUIDs often provide a more robust solution for distributed systems.
Remember: Data synchronization is not a trivial problem, and your primary key strategy plays a crucial role in its success. Take the time to evaluate your requirements and choose the appropriate approach for your specific use case.
Till next time, happy delta encoding.
by Joche Ojeda | Jan 9, 2025 | dotnet
While researching useful features in .NET 9 that could benefit XAF/XPO developers, I discovered something particularly interesting: Version 7 GUIDs (RFC 9562 specification). These new GUIDs offer a crucial feature – they’re sortable.
This discovery brought me back to an issue I encountered two years ago while working on the SyncFramework. We faced a peculiar problem where Deltas were correctly generated but processed in the wrong order in production environments. The occurrences seemed random, and no clear pattern emerged. Initially, I thought using Delta primary keys (GUIDs) to sort the Deltas would ensure they were processed in their generation order. However, this assumption proved incorrect. Through testing, I discovered that GUID generation couldn’t be trusted to be sequential. This issue affected multiple components of the SyncFramework. Whether generating GUIDs in C# or at the database level, there was no guarantee of sequential ordering. Different database engines could sort GUIDs differently. To address this, I implemented a sequence service as a solution.Enter .NET 9 with its Version 7 GUIDs (conforming to RFC 9562 specification). These new GUIDs are genuinely sequential, making them reliable for sorting operations.
To demonstrate this improvement, I created a test solution for XAF with a custom base object. The key implementation occurs in the OnSaving method:
protected override void OnSaving()
{
base.OnSaving();
if (!(Session is NestedUnitOfWork) && Session.IsNewObject(this) && oid.Equals(Guid.Empty))
{
oid = Guid.CreateVersion7();
}
}
Notice the use of CreateVersion7() instead of the traditional NewGuid(). For comparison, I also created another domain object using the traditional GUID generation:
protected override void OnSaving()
{
base.OnSaving();
if (!(Session is NestedUnitOfWork) && Session.IsNewObject(this) && oid.Equals(Guid.Empty))
{
oid = Guid.NewGuid();
}
}
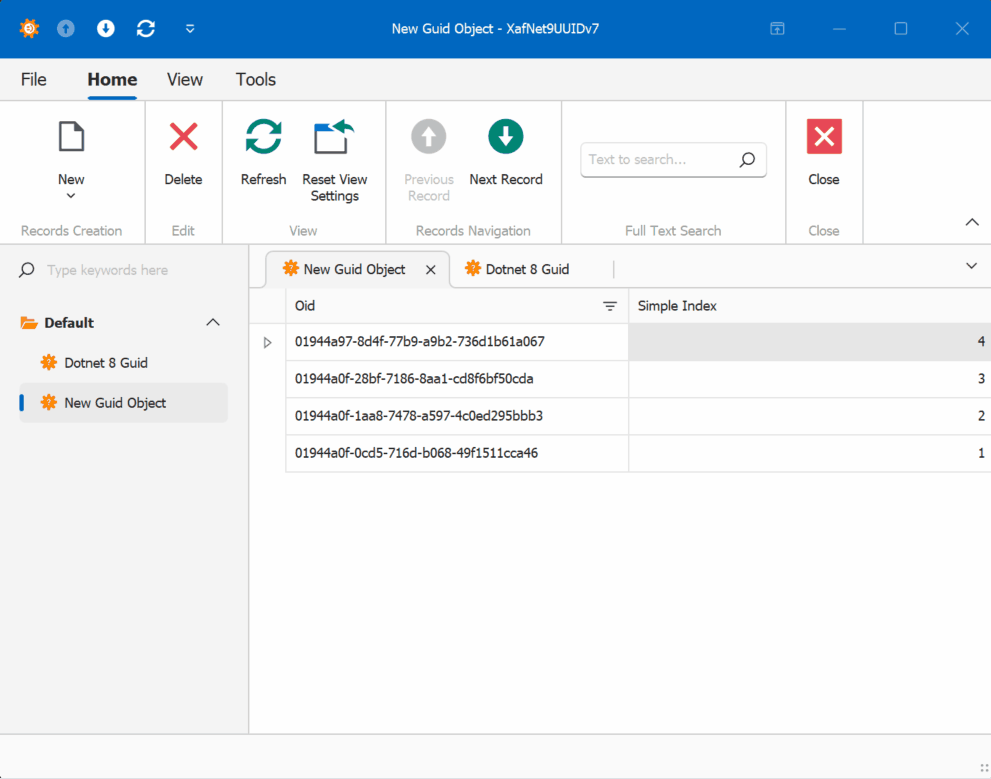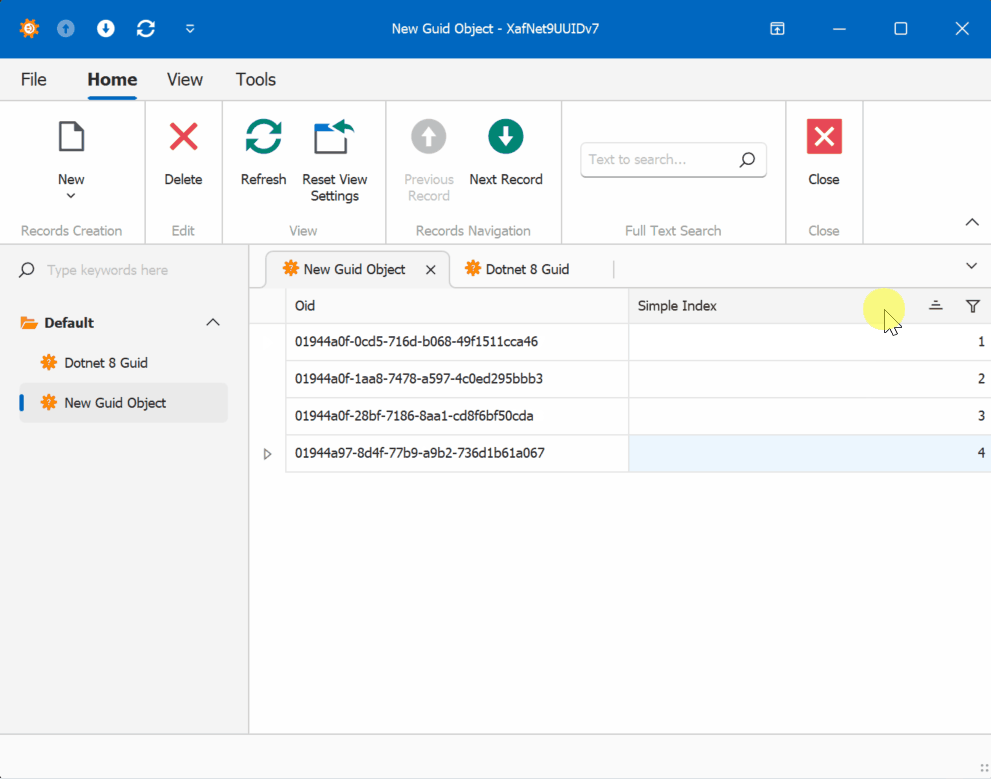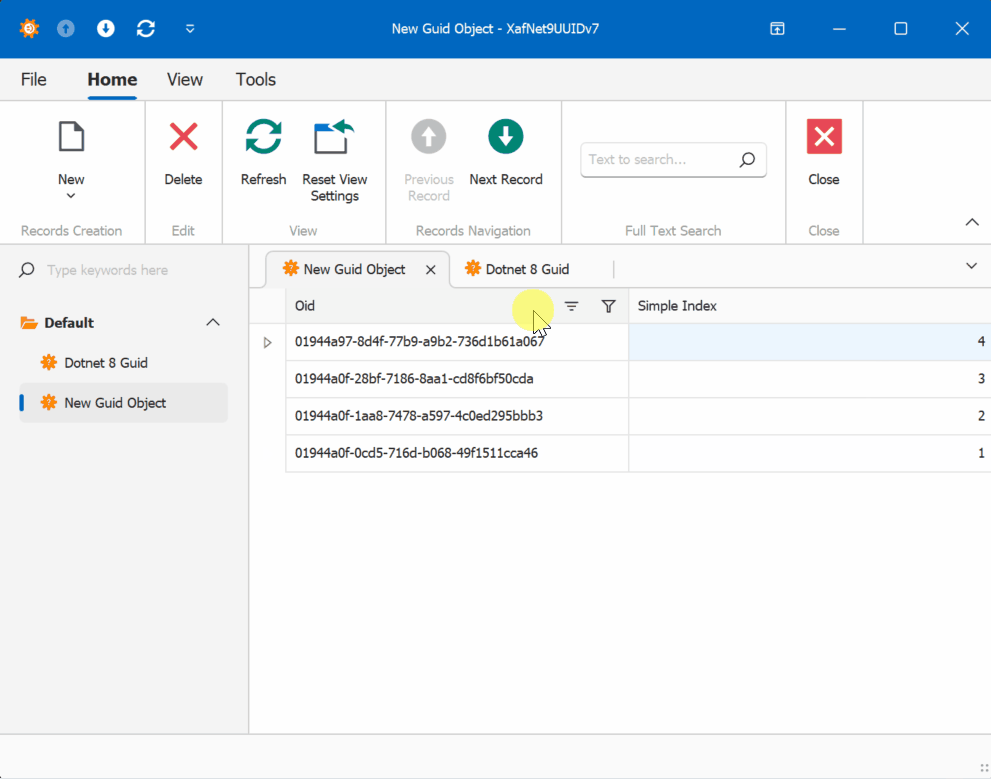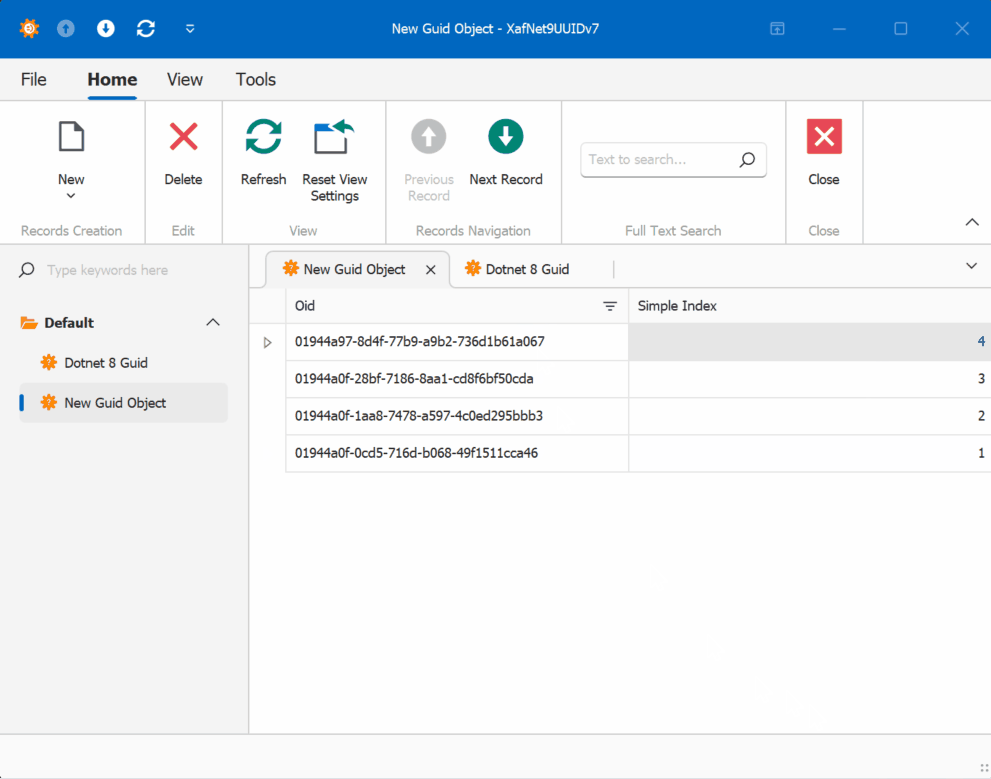
When creating multiple instances of the traditional GUID domain object, you’ll notice that the greater the time interval between instance creation, the less likely the GUIDs will maintain sequential ordering.
GUID Version 7
GUID Old Version
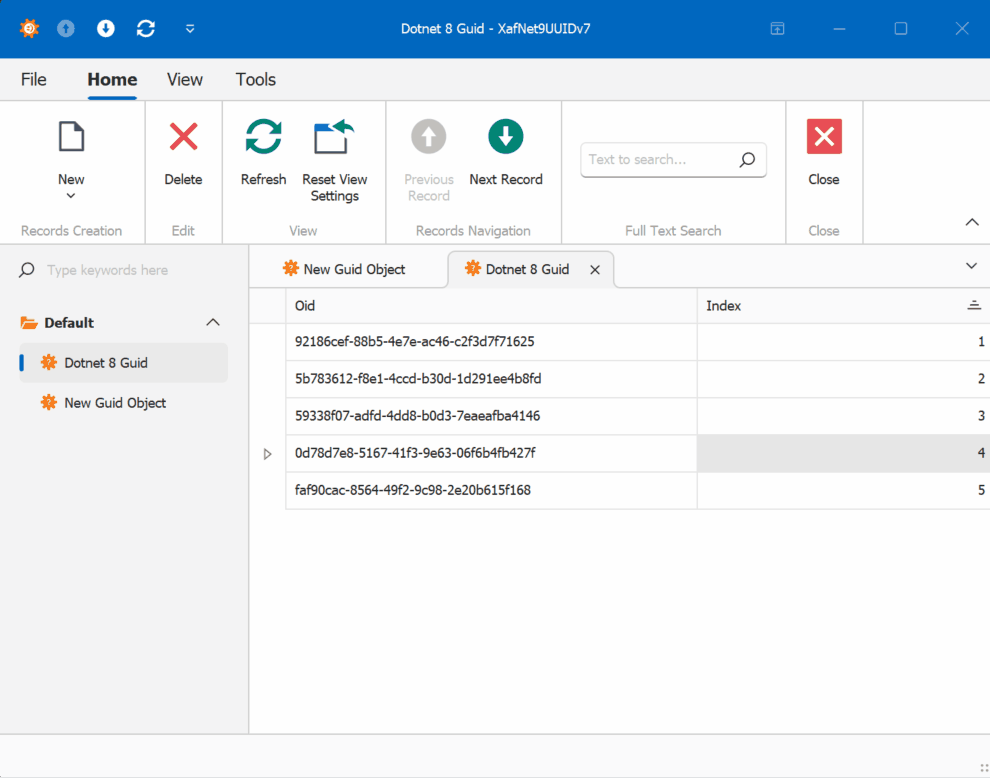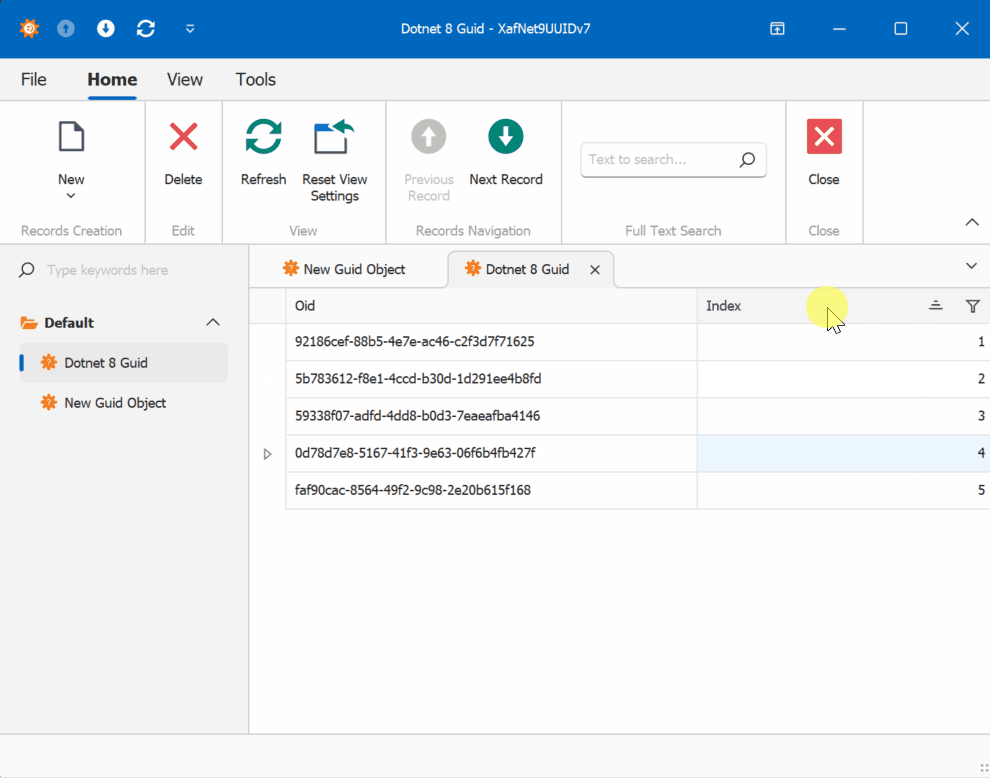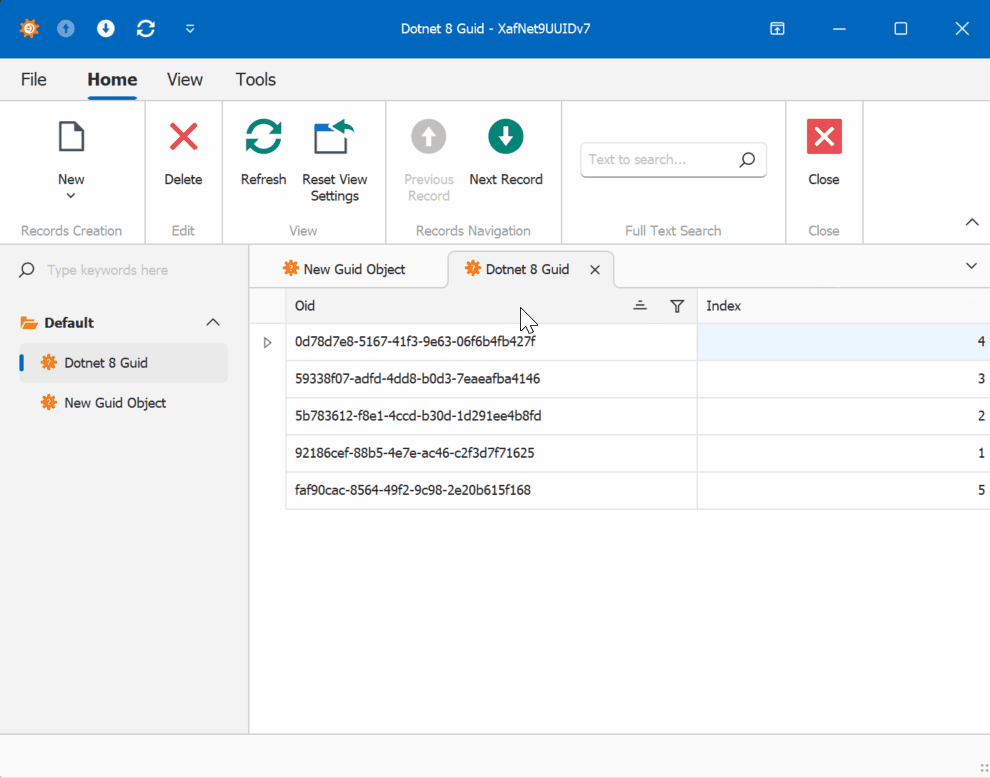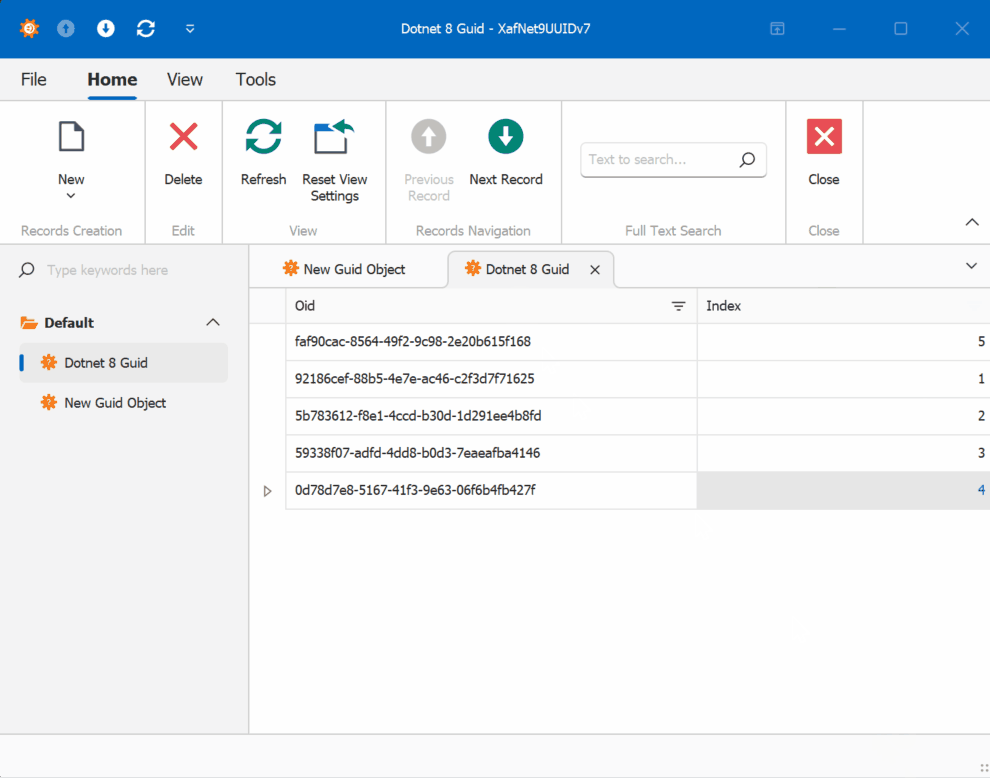
This new feature in .NET 9 could significantly simplify scenarios where sequential ordering is crucial, eliminating the need for additional sequence services in many cases. Here is the repo on GitHubHappy coding until next time!
Related article
On my GUID, common problems using GUID identifiers | Joche Ojeda

by Joche Ojeda | Oct 15, 2024 | A.I, Semantic Kernel, XAF, XPO
A few weeks ago, I forked the Semantic Kernel repository to experiment with it. One of my first experiments was to create a memory provider for XPO. The task was not too difficult; basically, I needed to implement the IMemoryStore interface, add some XPO boilerplate code, and just like that, we extended the Semantic Kernel memory store to support 10+ databases. You can check out the code for the XpoMemoryStore here.
My initial goal in creating the XpoMemoryStore was simply to see if XPO would be a good fit for handling embeddings. Spoiler alert: it was! To understand the basic functionality of the plugin, you can take a look at the integration test here.
As you can see, usage is straightforward. You start by connecting to the database that handles embedding collections, and all you need is a valid XPO connection string:
using XpoMemoryStore db = await XpoMemoryStore.ConnectAsync("XPO connection string");
In my original design, everything worked fine, but I faced some challenges when trying to use my new XpoMemoryStore in XAF. Here’s what I encountered:
- The implementation of XpoMemoryStore uses its own data layer, which can lead to issues. This needs to be rewritten to use the same data layer as XAF.
- The XpoEntry implementation cannot be extended. In some use cases, you might want to use a different object to store the embeddings, perhaps one that has an association with another object.
To address these problems, I introduced the IXpoEntryManager interface. The goal of this interface is to handle object creation and queries.
public interface IXpoEntryManager
{
T CreateObject();
public event EventHandler ObjectCreatedEvent;
void Commit();
IQueryable GetQuery(bool inTransaction = true);
void Delete(object instance);
void Dispose();
}
Now, object creation is handled through the CreateObject<T> method, allowing the underlying implementation to be changed to use a UnitOfWork or ObjectSpace. There’s also the ObjectCreatedEvent event, which lets you access the newly created object in case you need to associate it with another object. Lastly, the GetQuery<T> method enables redirecting the search for records to a different type.
I’ll keep updating the code as needed. If you’d like to discuss AI, XAF, or .NET, feel free to schedule a meeting: Schedule a Meeting with us.
Until next time, XAF out!
Related Article
https://www.jocheojeda.com/2024/09/04/using-the-imemorystore-interface-and-devexpress-xpo-orm-to-implement-a-custom-memory-store-for-semantic-kernel/

by Joche Ojeda | Jan 22, 2024 | Sqlite
SQLite and Its Journal Modes: Understanding the Differences and Advantages
SQLite, an acclaimed lightweight database engine, is widely used in various applications due to its simplicity, reliability, and open-source nature. One of the critical aspects of SQLite that ensures data integrity and supports various use-cases is its “journal mode.” This mode is a part of SQLite’s transaction mechanism, which is vital for maintaining database consistency. In this article, we’ll explore the different journal modes available in SQLite and their respective advantages.
Understanding Journal Modes in SQLite
Journal modes in SQLite are methods used to handle transactions and rollbacks. They dictate how the database engine logs changes and how it recovers in case of failures or rollbacks. There are several journal modes available in SQLite, each with unique characteristics suited for different scenarios.
1. Delete Mode
Description:
The default mode in SQLite, Delete mode, creates a rollback journal file alongside the database file. This file records a copy of the original unchanged data before any modifications.
Advantages:
- Simplicity: Easy to understand and use, making it ideal for basic applications.
- Reliability: It ensures data integrity by preserving original data until the transaction is committed.
2. Truncate Mode
Description:
Truncate mode operates similarly to Delete mode, but instead of deleting the journal file at the end of a transaction, it truncates it to zero length.
Advantages:
- Faster Commit: Reduces the time to commit transactions, as truncating is generally quicker than deleting.
- Reduced Disk Space Usage: By truncating the file, it avoids leaving large, unused files on the disk.
3. Persist Mode
Description:
In Persist mode, the journal file is not deleted or truncated but is left on the disk with its header marked as inactive.
Advantages:
- Reduced File Operations: This mode minimizes file system operations, which can be beneficial in environments where these operations are expensive.
- Quick Restart: It allows for faster restarts of transactions in busy systems.
4. Memory Mode
Description:
Memory mode stores the rollback journal in volatile memory (RAM) instead of the disk.
Advantages:
- High Performance: It offers the fastest possible transaction times since memory operations are quicker than disk operations.
- Ideal for Temporary Databases: Best suited for databases that don’t require data persistence, like temporary caches.
5. Write-Ahead Logging (WAL) Mode
Description:
WAL mode is a significant departure from the traditional rollback journal. It writes changes to a separate WAL file without changing the original database file until a checkpoint occurs.
Advantages:
- Concurrency: It allows read operations to proceed concurrently with write operations, enhancing performance in multi-user environments.
- Consistency and Durability: Ensures data integrity and durability without locking the entire database.
6. Off Mode
Description:
This mode disables the rollback journal entirely. Transactions are not atomic in this mode.
Advantages:
- Maximum Speed: It can be faster since there’s no overhead of maintaining a journal.
- Use Case Specific: Useful for scenarios where speed is critical and data integrity is not a concern, like intermediate calculations or disposable data.
Conclusion
Choosing the right journal mode in SQLite depends on the specific requirements of the application. While Delete and Truncate modes are suitable for most general purposes, Persist and Memory modes serve niche use-cases. WAL mode stands out for applications requiring high concurrency and performance. Understanding these modes helps developers and database administrators optimize SQLite databases for their particular needs, balancing between data integrity, speed, and resource utilization.
In summary, SQLite’s flexibility in journal modes is a testament to its adaptability, making it a preferred choice for a wide range of applications, from embedded systems to web applications.