
by Joche Ojeda | Feb 23, 2025 | A.I
I’ve been thinking about this topic for a while and have collected numerous notes and ideas about how to present abstractions that allow large language models (LLMs) to interact with various systems – whether that’s your database, operating system, word documents, or other applications.
Before diving deeper, let’s review some fundamental concepts:
Key Concepts
First, let’s talk about APIs (Application Programming Interface). In simple terms, an API is a way to expose methods, functions, and procedures from your application, independent of the programming language being used.
Next is the REST API concept, which is a method of exposing your API using HTTP verbs. As IT professionals, we hear these terms – HTTP, REST, API – almost daily, but we might not fully grasp their core concepts. Let me explain how they relate to software automation using AI.
HTTP (Hypertext Transfer Protocol) is fundamentally a way for two applications to communicate using text. This is its beauty – text serves as the basic layer of understanding between systems, meaning almost any system or programming language can produce a client or server that can interact via HTTP.
REST (Representational State Transfer) is a methodology for systems to communicate and either change or read the state of another system.
Levels of System Interaction
When implementing LLMs for system automation, we first need to determine our desired level of interaction. Here are several approaches:
- Human-like Interaction: An LLM can interact with your operating system using mouse and keyboard inputs, effectively mimicking human behavior.
- REST API Integration: Your application can communicate using HTTP verbs and the REST protocol.
- SDK Implementation: You can create a software development kit that describes your application’s functionality and expose this to the LLM.
The connection method will vary depending on your chosen technology. For instance:
- Microsoft Semantic Kernel allows you to create plugins that interact with your system through REST API, database, or SDK.
- Microsoft AI extensions require you to decide on your preferred interaction level before implementation.
- The Model Context Protocol is a newer approach that enables application exposure for LLM agents, with Claude from Anthropic being a notable example.
Implementation Considerations
When automating your system, you need to consider:
- Available Integration Options: Not all systems provide an SDK or API, which can limit automation possibilities.
- Interaction Protocol Choice: You’ll need to decide between REST API, HTTP, or Model Context Protocol.
This overview should help you understand the various levels of resolution needed to automate your application. What’s your preferred method for integrating LLMs with your applications? I’d love to hear your thoughts and experiences.

by Joche Ojeda | Feb 7, 2025 | Uncategorized
I recently had the privilege of conducting a training session in Cairo, Egypt, focusing on modern application development approaches. The session covered two key areas that are transforming how we build business applications: application frameworks and AI integration.
Streamlining Development with Application Frameworks
One of the highlights was demonstrating DevExpress’s eXpressApp Framework (XAF). The students were particularly impressed by how quickly we could build fully-functional Line of Business (LOB) applications. XAF’s approach eliminates much of the repetitive coding typically associated with business application development:
- Automatic CRUD operations
- Built-in security system
- Consistent UI across different platforms
- Rapid prototyping capabilities
Seamless Integration: XAF Meets Microsoft Semantic Kernel
What made this training unique was demonstrating how XAF’s capabilities extend into AI territory. We built the entire AI interface using XAF itself, showcasing how a traditional LOB framework can seamlessly incorporate advanced AI features. The audience, coming primarily from JavaScript backgrounds with Angular and React experience, was particularly impressed by how this approach simplified the integration of AI into business applications.
During the demonstrations, we explored practical implementations using Microsoft Semantic Kernel. The students were fascinated by practical demonstrations of:
- Natural language processing for document analysis
- Automated content generation for business documentation
- Intelligent decision support systems
- Context-aware data processing
Student Engagement and Outcomes
The response from the students, most of whom came from JavaScript development backgrounds, was overwhelmingly positive. As experienced frontend developers using Angular and React, they were initially skeptical about a different approach to application development. However, their enthusiasm peaked when they saw how these technologies could solve real business challenges they face daily. The combination of XAF’s rapid development capabilities and Semantic Kernel’s AI features, all integrated into a cohesive development experience, opened their eyes to new possibilities in application development.
Looking Forward
This training session in Cairo demonstrated the growing appetite for modern development approaches in the region. The intersection of efficient application frameworks and AI capabilities is proving to be a powerful combination for next-generation business applications.
And last, but not least, some pictures )))
by Joche Ojeda | Nov 2, 2024 | A.I, Semantic Kernel
Today, when I woke up, it was sunny but really cold, and the weather forecast said that snow was expected.
So, I decided to order ramen and do a “Saturday at home” type of project. My tools of choice for this experiment are:
1) DevExpress Chat Component for Blazor
I’m thrilled they have this component. I once wrote my own chat component, and it’s a challenging task, especially given the variety of use cases.
2) Semantic Kernel
I’ve been experimenting with Semantic Kernel for a while now, and let me tell you—it’s a fantastic tool if you’re in the .NET ecosystem. It’s so cool to have native C# code to interact with AI services in a flexible way, making your code mostly agnostic to the AI provider—like a WCF for AIs.
Goal of the Experiment
The goal for today’s experiment is to render a list of products as a carousel within a chat conversation.
Configuration
To accomplish this, I’ll use prompt execution settings in Semantic Kernel to ensure that the response from the LLM is always in JSON format as a string.
var Settings = new OpenAIPromptExecutionSettings
{
MaxTokens = 500,
Temperature = 0.5,
ResponseFormat = "json_object"
};
The key part here is the response format. The chat completion can respond in two ways:
- Text: A simple text answer.
- JSON Object: This format always returns a JSON object, with the structure provided as part of the prompt.
With this approach, we can deserialize the LLM’s response to an object that helps conditionally render the message content within the DevExpress Chat Component.
Structure
Here’s the structure I’m using:
public class MessageData
{
public string Message { get; set; }
public List Options { get; set; }
public string MessageTemplateName { get; set; }
}
public class OptionSet
{
public string Name { get; set; }
public string Description { get; set; }
public List Options { get; set; }
}
public class Option
{
public string Image { get; set; }
public string Url { get; set; }
public string Description { get; set; }
};
- MessageData: This structure will always be returned by our LLM.
- Option: A list of options for a message, which also serves as data for possible responses.
- OptionSet: A list of possible responses to feed into the prompt execution settings.
Prompt Execution Settings
One more step on the Semantic Kernel side is configuring the prompt execution settings:
var Settings = new OpenAIPromptExecutionSettings
{
MaxTokens = 500,
Temperature = 0.5,
ResponseFormat = "json_object"
};
Settings.ChatSystemPrompt = $"You need to answer using this JSON format with this structure {Structure} " +
$"Before giving an answer, check if it exists within this list of option sets {OptionSets}. " +
$"If your answer does not include options, the message template value should be 'Message'; otherwise, it should be 'Options'.";
In the prompt, we specify the structure {Structure} we want as a response, provide a list of possible options for the message in the {OptionSets} variable, and add a final line to guide the LLM on which template type to use.
Example Requests and Responses
For example, when executing the following request:
- Prompt: “Show me a list of Halloween costumes for cats.”
We’ll get this response from the LLM:
{
"Message": "Please select one of the Halloween costumes for cats",
"Options": [
{"Image": "./images/catblack.png", "Url": "https://cat.com/black", "Description": "Black cat costume"},
{"Image": "./images/catwhite.png", "Url": "https://cat.com/white", "Description": "White cat costume"},
{"Image": "./images/catorange.png", "Url": "https://cat.com/orange", "Description": "Orange cat costume"}
],
"MessageTemplateName": "Options"
}
With this JSON structure, we can conditionally render messages in the chat component as follows:
<DxAIChat CssClass="my-chat" MessageSent="MessageSent">
<MessageTemplate>
<div>
@{
if (@context.Typing)
{
<span>Loading...</span>
}
else
{
MessageData md = null;
try
{
md = JsonSerializer.Deserialize<MessageData>(context.Content);
}
catch
{
md = null;
}
if (md == null)
{
<div class="my-chat-content">
@context.Content
</div>
}
else
{
if (md.MessageTemplateName == "Options")
{
<div class="centered-carousel">
<Carousel class="carousel-container" Width="280" IsFade="true">
@foreach (var option in md.Options)
{
<CarouselItem>
<ChildContent>
<div>
<img src="@option.Image" alt="demo-image" />
<Button Color="Color.Primary" class="carousel-button">@option.Description</Button>
</div>
</ChildContent>
</CarouselItem>
}
</Carousel>
</div>
}
else if (md.MessageTemplateName == "Message")
{
<div class="my-chat-content">
@md.Message
</div>
}
}
}
}
</div>
</MessageTemplate>
</DxAIChat>
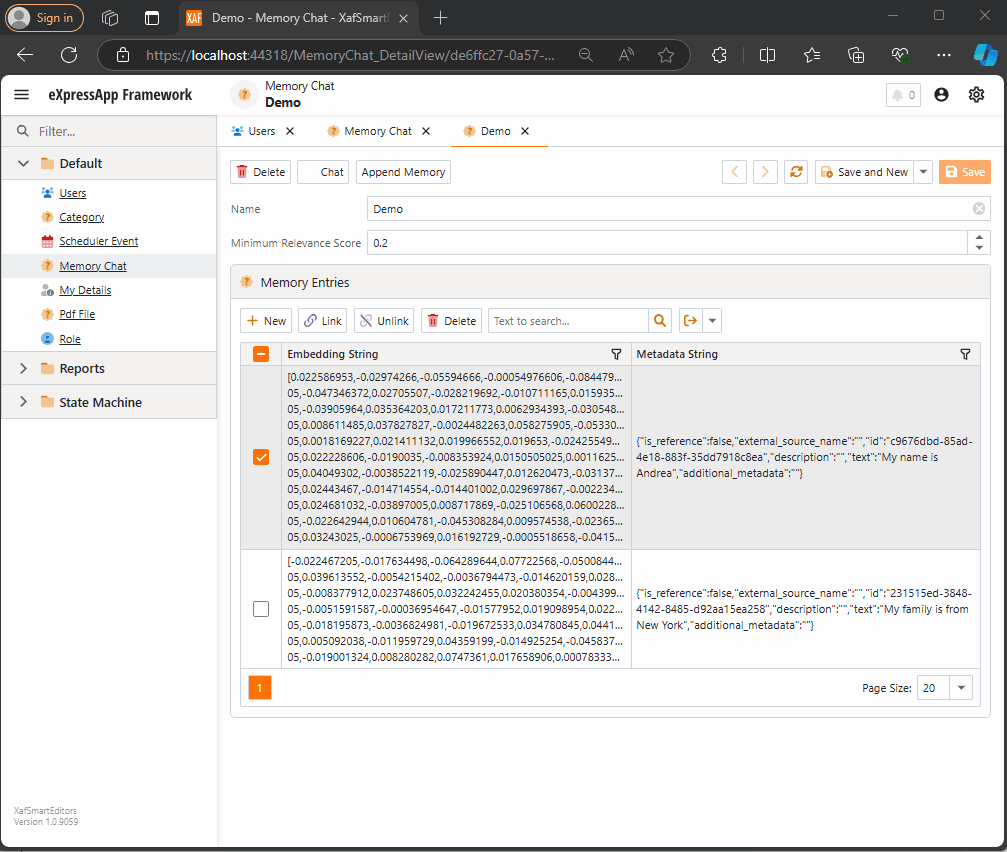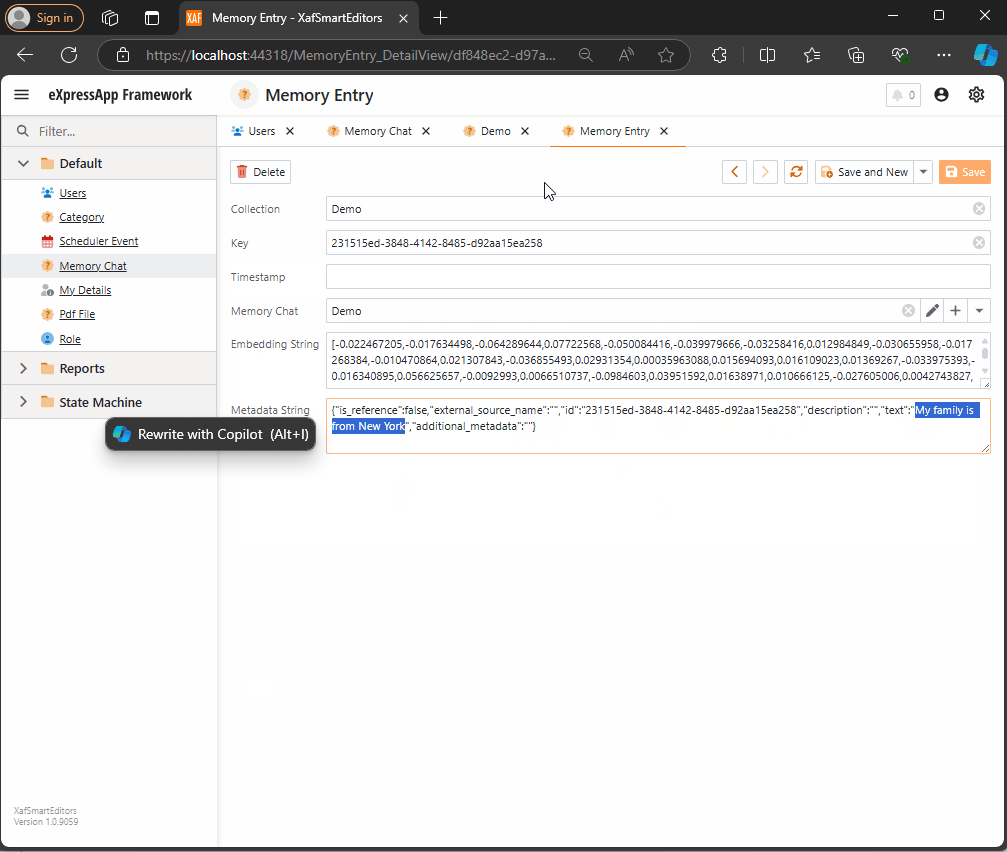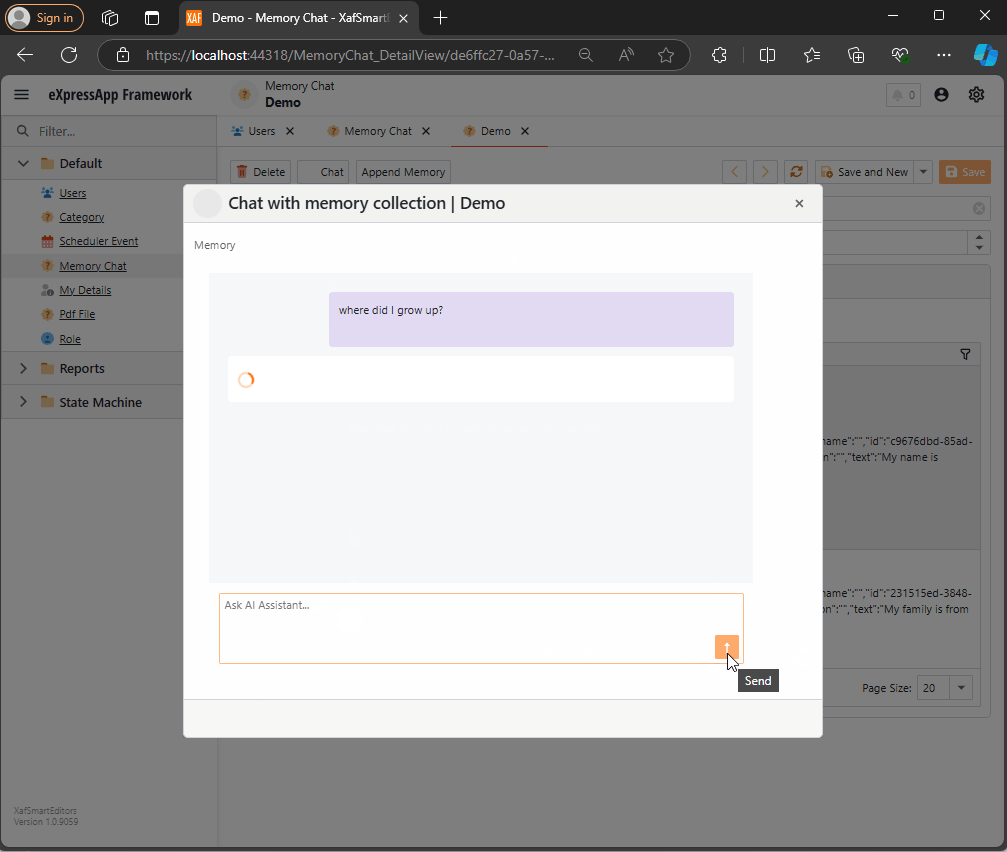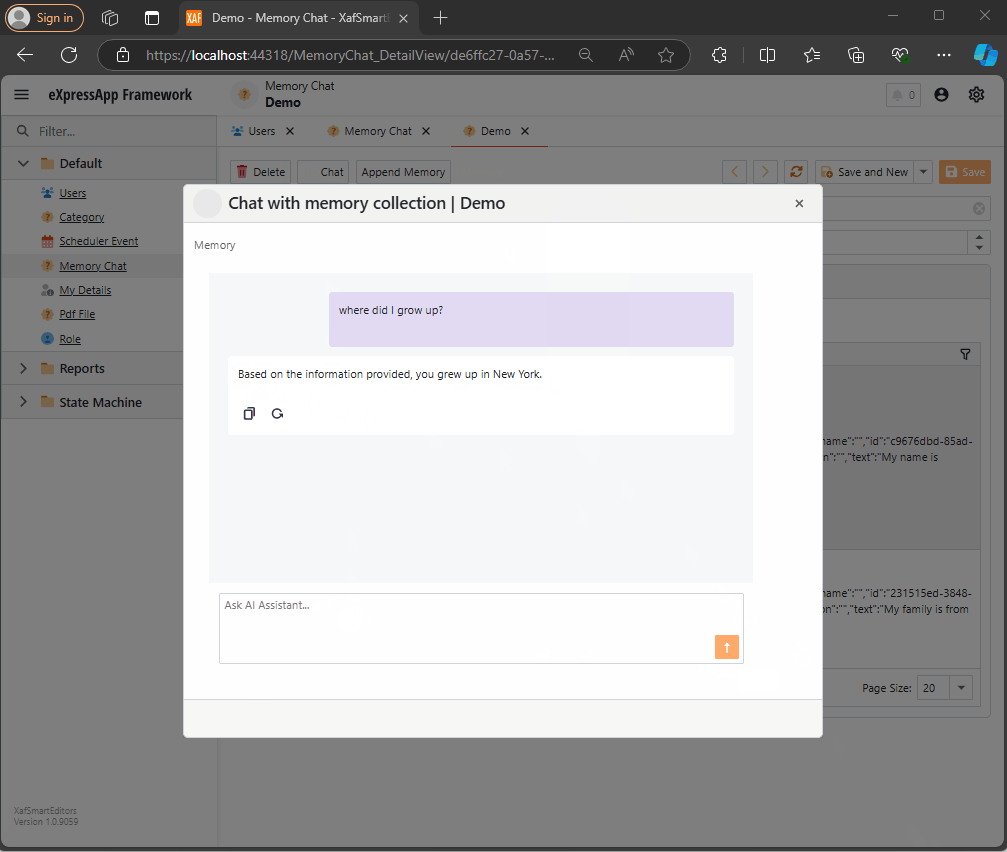
End Solution Example
Here’s an example of the final solution:
You can find the full source code here: https://github.com/egarim/devexpress-ai-chat-samples and a short video here https://youtu.be/dxMnOWbe3KA
by Joche Ojeda | Oct 21, 2024 | A.I, Semantic Kernel
A few weeks ago, I received the exciting news that DevExpress had released a new chat component (you can read more about it here). This was a big deal for me because I had been experimenting with the Semantic Kernel for almost a year. Most of my experiments fell into three categories:
- NUnit projects with no UI (useful when you need to prove a concept).
- XAF ASP.NET projects using a large textbox (String with unlimited size in XAF) to emulate a chat control.
- XAF applications using a custom chat component that I developed—which, honestly, didn’t look great because I’m more of a backend developer than a UI specialist. Still, the component did the job.
Once I got my hands on the new Chat component, the first thing I did was write a property editor to easily integrate it into XAF. You can read more about property editors in XAF here.
With the Chat component property editor in place, I had the necessary tool to accelerate my experiments with the Semantic Kernel (learn more about the Semantic Kernel here).
The Current Experiment
A few weeks ago, I wrote an implementation of the Semantic Kernel Memory Store using DevExpress’s XPO as the data storage solution. You can read about that implementation here. The next step was to integrate this Semantic Memory Store into XAF, and that’s now done. Details about that process can be found here.
What We Have So Far
- A Chat component property editor for XAF.
- A Semantic Kernel Memory Store for XPO that’s compatible with XAF.
With these two pieces, we can create an interesting prototype. The goals for this experiment are:
- Saving “memories” into a domain object (via XPO).
- Querying these memories through the Chat component property editor, using Semantic Kernel chat completions (compatible with all OpenAI APIs).
Step 1: Memory Collection Object
The first thing we need is an object that represents a collection of memories. Here’s the implementation:
[DefaultClassOptions]
public class MemoryChat : BaseObject
{
public MemoryChat(Session session) : base(session) {}
public override void AfterConstruction()
{
base.AfterConstruction();
this.MinimumRelevanceScore = 0.20;
}
double minimumRelevanceScore;
string name;
[Size(SizeAttribute.DefaultStringMappingFieldSize)]
public string Name
{
get => name;
set => SetPropertyValue(nameof(Name), ref name, value);
}
public double MinimumRelevanceScore
{
get => minimumRelevanceScore;
set => SetPropertyValue(nameof(MinimumRelevanceScore), ref minimumRelevanceScore, value);
}
[Association("MemoryChat-MemoryEntries")]
public XPCollection<MemoryEntry> MemoryEntries
{
get => GetCollection<MemoryEntry>(nameof(MemoryEntries));
}
}
This is a simple object. The two main properties are the MinimumRelevanceScore, which is used for similarity searches with embeddings, and the collection of MemoryEntries, where different memories are stored.
Step 2: Adding Memories
The next task is to easily append memories to that collection. I decided to use a non-persistent object displayed in a popup view with a large text area. When the user confirms the action in the dialog, the text gets vectorized and stored as a memory in the collection. You can see the implementation of the view controller here.
Let me highlight the important parts.
When we create the view for the popup window:
private void AppendMemory_CustomizePopupWindowParams(object sender, CustomizePopupWindowParamsEventArgs e)
{
var os = this.Application.CreateObjectSpace(typeof(TextMemory));
var textMemory = os.CreateObject<TextMemory>();
e.View = this.Application.CreateDetailView(os, textMemory);
}
The goal is to show a large textbox where the user can type any text. When they confirm, the text is vectorized and stored as a memory.
Next, storing the memory:
private async void AppendMemory_Execute(object sender, PopupWindowShowActionExecuteEventArgs e)
{
var textMemory = e.PopupWindowViewSelectedObjects[0] as TextMemory;
var currentMemoryChat = e.SelectedObjects[0] as MemoryChat;
var store = XpoMemoryStore.ConnectAsync(xafEntryManager).GetAwaiter().GetResult();
var semanticTextMemory = GetSemanticTextMemory(store);
await semanticTextMemory.SaveInformationAsync(currentMemoryChat.Name, id: Guid.NewGuid().ToString(), text: textMemory.Content);
}
Here, the GetSemanticTextMemory method plays a key role:
private static SemanticTextMemory GetSemanticTextMemory(XpoMemoryStore store)
{
var embeddingModelId = "text-embedding-3-small";
var getKey = () => Environment.GetEnvironmentVariable("OpenAiTestKey", EnvironmentVariableTarget.Machine);
var kernel = Kernel.CreateBuilder()
.AddOpenAIChatCompletion(ChatModelId, getKey.Invoke())
.AddOpenAITextEmbeddingGeneration(embeddingModelId, getKey.Invoke())
.Build();
var embeddingGenerator = new OpenAITextEmbeddingGenerationService(embeddingModelId, getKey.Invoke());
return new SemanticTextMemory(store, embeddingGenerator);
}
This method sets up an embedding generator used to create semantic memories.
Step 3: Querying Memories
To query the stored memories, I created a non-persistent type that interacts with the chat component:
public interface IMemoryData
{
IChatCompletionService ChatCompletionService { get; set; }
SemanticTextMemory SemanticTextMemory { get; set; }
string CollectionName { get; set; }
string Prompt { get; set; }
double MinimumRelevanceScore { get; set; }
}
This interface provides the necessary services to interact with the chat component, including ChatCompletionService and SemanticTextMemory.
Step 4: Handling Messages
Lastly, we handle message-sent callbacks, as explained in this article:
async Task MessageSent(MessageSentEventArgs args)
{
ChatHistory.AddUserMessage(args.Content);
var answers = Value.SemanticTextMemory.SearchAsync(
collection: Value.CollectionName,
query: args.Content,
limit: 1,
minRelevanceScore: Value.MinimumRelevanceScore,
withEmbeddings: true
);
string answerValue = "No answer";
await foreach (var answer in answers)
{
answerValue = answer.Metadata.Text;
}
string messageContent = answerValue == "No answer"
? "There are no memories containing the requested information."
: await Value.ChatCompletionService.GetChatMessageContentAsync($"You are an assistant queried for information. Use this data: {answerValue} to answer the question: {args.Content}.");
ChatHistory.AddAssistantMessage(messageContent);
args.SendMessage(new Message(MessageRole.Assistant, messageContent));
}
Here, we intercept the message, query the SemanticTextMemory, and use the results to generate an answer with the chat completion service.
This was a long post, but I hope it’s useful for you all. Until next time—XAF OUT!
You can find the full implementation on this repo

by Joche Ojeda | Oct 15, 2024 | A.I, Semantic Kernel, XAF, XPO
A few weeks ago, I forked the Semantic Kernel repository to experiment with it. One of my first experiments was to create a memory provider for XPO. The task was not too difficult; basically, I needed to implement the IMemoryStore interface, add some XPO boilerplate code, and just like that, we extended the Semantic Kernel memory store to support 10+ databases. You can check out the code for the XpoMemoryStore here.
My initial goal in creating the XpoMemoryStore was simply to see if XPO would be a good fit for handling embeddings. Spoiler alert: it was! To understand the basic functionality of the plugin, you can take a look at the integration test here.
As you can see, usage is straightforward. You start by connecting to the database that handles embedding collections, and all you need is a valid XPO connection string:
using XpoMemoryStore db = await XpoMemoryStore.ConnectAsync("XPO connection string");
In my original design, everything worked fine, but I faced some challenges when trying to use my new XpoMemoryStore in XAF. Here’s what I encountered:
- The implementation of XpoMemoryStore uses its own data layer, which can lead to issues. This needs to be rewritten to use the same data layer as XAF.
- The XpoEntry implementation cannot be extended. In some use cases, you might want to use a different object to store the embeddings, perhaps one that has an association with another object.
To address these problems, I introduced the IXpoEntryManager interface. The goal of this interface is to handle object creation and queries.
public interface IXpoEntryManager
{
T CreateObject();
public event EventHandler ObjectCreatedEvent;
void Commit();
IQueryable GetQuery(bool inTransaction = true);
void Delete(object instance);
void Dispose();
}
Now, object creation is handled through the CreateObject<T> method, allowing the underlying implementation to be changed to use a UnitOfWork or ObjectSpace. There’s also the ObjectCreatedEvent event, which lets you access the newly created object in case you need to associate it with another object. Lastly, the GetQuery<T> method enables redirecting the search for records to a different type.
I’ll keep updating the code as needed. If you’d like to discuss AI, XAF, or .NET, feel free to schedule a meeting: Schedule a Meeting with us.
Until next time, XAF out!
Related Article
https://www.jocheojeda.com/2024/09/04/using-the-imemorystore-interface-and-devexpress-xpo-orm-to-implement-a-custom-memory-store-for-semantic-kernel/


