
by Joche Ojeda | Apr 23, 2024 | C#, Uncategorized
Castle.Core: A Favourite Among C# Developers
Castle.Core, a component of the Castle Project, is an open-source project that provides common abstractions, including logging services. It has garnered popularity in the .NET community, boasting over 88 million downloads.
Dynamic Proxies: Acting as Stand-Ins
In the realm of programming, a dynamic proxy is a stand-in or surrogate for another object, controlling access to it. This proxy object can introduce additional behaviours such as logging, caching, or thread-safety before delegating the call to the original object.
The Impact of Dynamic Proxies
Dynamic proxies are instrumental in intercepting method calls and implementing aspect-oriented programming. This aids in managing cross-cutting concerns like logging and transaction management.
Castle DynamicProxy: Generating Proxies at Runtime
Castle DynamicProxy, a feature of Castle.Core, is a library that generates lightweight .NET proxies dynamically at runtime. It enables operations to be performed before and/or after the method execution on the actual object, without altering the class code.
Dynamic Proxies in the Realm of ORM Libraries
Dynamic proxies find significant application in Object-Relational Mapping (ORM) Libraries. ORM allows you to interact with your database, such as SQL Server, Oracle, or MySQL, in an object-oriented manner. Dynamic proxies are employed in ORM libraries to create lightweight objects that mirror database records, facilitating efficient data manipulation and retrieval.
Here’s a simple example of how to create a dynamic proxy using Castle.Core:
using Castle.DynamicProxy;
public class SimpleInterceptor : IInterceptor
{
public void Intercept(IInvocation invocation)
{
Console.WriteLine("Before target call");
try
{
invocation.Proceed(); //Calls the decorated instance.
}
catch (Exception)
{
Console.WriteLine("Target threw an exception!");
throw;
}
finally
{
Console.WriteLine("After target call");
}
}
}
public class SomeClass
{
public virtual void SomeMethod()
{
Console.WriteLine("SomeMethod in SomeClass called");
}
}
public class Program
{
public static void Main()
{
ProxyGenerator generator = new ProxyGenerator();
SimpleInterceptor interceptor = new SimpleInterceptor();
SomeClass proxy = generator.CreateClassProxy(interceptor);
proxy.SomeMethod();
}
}
Conclusion
Castle.Core and its DynamicProxy feature are invaluable tools for C# programmers, enabling efficient handling of cross-cutting concerns through the creation of dynamic proxies. With over 825.5 million downloads, Castle.Core’s widespread use in the .NET community underscores its utility. Whether you’re a novice or an experienced C# programmer, understanding and utilizing dynamic proxies, particularly in ORM libraries, can significantly boost your programming skills. Dive into Castle.Core and dynamic proxies in your C# projects and take your programming skills to the next level. Happy coding!

by Joche Ojeda | Apr 18, 2024 | Carbon Credits, Uncategorized
As we face the urgent need to address climate change, innovative solutions are crucial. One such solution lies in using blockchain technology, similar to Ethereum, Polygon, or TON, to manage carbon credits. In this article, we’ll break down what carbon credits are, how blockchain can revolutionize their management, and why it matters to you.
What Are Carbon Credits?
Carbon credits are like digital tokens representing a company’s right to emit a specific amount of carbon dioxide. The goal is to reduce overall emissions by making these credits tradeable. Here’s how blockchain can help:
- Transparency and Trust: Blockchain operates as a decentralized digital ledger, recording transactions securely and transparently. This ensures that every carbon credit is unique and not double-counted. Imagine it as a tamper-proof ledger that tracks emissions accurately.
- Efficiency: Automating the tracking and management of carbon credits using smart contracts reduces errors and speeds up the process. It’s like having an automated carbon accountant!
- Security: Blockchain ensures the integrity of each credit. No one can manipulate the system, making it reliable for investors and companies alike.
Use Cases
- Carbon Credit Trading: Blockchain can amplify voluntary carbon markets, channeling billions of dollars toward green investments. It allows seamless trading of credits, benefiting both the environment and investors.
- Parametric Insurance: Smart contracts can facilitate the adoption of parametric insurance for climate events. Imagine insurance payouts triggered automatically based on predefined conditions (e.g., extreme weather events).
- Open Data Infrastructure: Blockchain can create an open data infrastructure for climate information. Reliable climate data helps businesses identify investment opportunities and assess risks related to climate change.
Why Should You Care?
As an American around 50 years old, you’ve witnessed environmental changes. Blockchain can empower you to:
- Invest Responsibly: Understand where your investments go and support companies with sustainable practices.
- Track Your Carbon Footprint: Imagine a personal carbon ledger that shows your impact and helps you make greener choices.
- Advocate for Change: Educate others about blockchain’s potential in combating climate change.
Remember, blockchain isn’t just for tech enthusiasts—it’s a tool for everyone to create a greener future. So, let’s embrace it and contribute to a more sustainable world! ?✨
Previous Articles
Carbon Sequestration: A Vital Process for Climate Change Mitigation
Understanding Carbon Credit Allowances
Carbon Credits 101

by Joche Ojeda | Apr 18, 2024 | network, Uncategorized
In today’s digital age, ensuring the security of our online activities and expanding the capabilities of our home networks are more important than ever. Two powerful tools that can help you achieve these goals are OpenVPN and DD-WRT. Here’s a straightforward guide to understanding what these technologies are and how they can be beneficial.
What is OpenVPN?
OpenVPN is a software application that allows you to create a secure connection over the internet between your computer and a server. Think of it as a protective tunnel for your internet traffic, shielding your data from prying eyes. This is particularly useful if you often use public Wi-Fi networks, which can be less secure and more vulnerable to hacking. By using OpenVPN, you can ensure that your sensitive information, such as passwords and personal details, are encrypted and safe from cyber threats.
Key Benefits of OpenVPN:
- Security: Encrypts your internet connection to provide enhanced security.
- Privacy: Masks your IP address, which helps keep your online activities private.
- Accessibility: Allows you to access websites and services that may be restricted in your area.
What is DD-WRT?
DD-WRT is a type of firmware that can replace the default firmware on your wireless router. Firmware is essentially the operating system that runs on your router, managing everything from network traffic to security features. Many factory-installed firmwares provide only basic functionalities. DD-WRT, on the other hand, is an open-source alternative that boosts your router’s capabilities significantly.
Key Benefits of DD-WRT:
- Enhanced Performance: Improves Wi-Fi signal strength and extends the range of your network.
- Advanced Features: Offers features like bandwidth monitoring, access controls, and the ability to set up a virtual private network (VPN).
- Customization: Allows more control over your network’s behavior and settings.
Why Combine OpenVPN with DD-WRT?
Using OpenVPN in conjunction with DD-WRT can transform your router into a powerful gateway that secures your entire home’s internet traffic. By installing OpenVPN on a DD-WRT router, you can ensure that all data passing through your router is encrypted, which adds an extra layer of security to every device connected to your network.
How Can You Get Started?
Setting up OpenVPN and DD-WRT might sound daunting, but there are plenty of resources and guides available to help you. Many communities and forums are dedicated to DD-WRT and OpenVPN, where you can find detailed instructions and get advice from experienced users. Additionally, considering a professional setup might be a good idea if you’re not comfortable undertaking the installation yourself.
Troubleshooting Common OpenVPN Issues on DD-WRT Routers
DD-WRT routers are popular for their robust features and flexibility compared to standard firmware shipped with wireless routers. However, setting up advanced features like an OpenVPN client can sometimes lead to errors if not configured correctly. Two common issues encountered during OpenVPN setups on DD-WRT routers are: unrecognized options in the configuration and errors related to Data Channel Offload (DCO). Here, we’ll walk through solutions to these problems, ensuring a smoother VPN experience.
Issue 1: Unrecognized Option “block-outside-dns“
Problem Description:
The error “Options error: Unrecognized option or missing or extra parameter(s) in [PUSH-OPTIONS]:3: block-outside-dns (2.6.10)” typically indicates that the OpenVPN client on DD-WRT does not recognize or support the `block-outside-dns` directive. This directive is commonly used on Windows clients to prevent DNS leaks but is not applicable or necessary for DD-WRT setups.
Solution Steps:
- Access Your VPN Server Configuration: Log into your OpenVPN server where your VPN configuration files are stored. This might be a PiVPN setup on a Raspberry Pi or any other Linux-based server running OpenVPN.
- Modify the Server Configuration:
- Restart the OpenVPN Service: Apply the changes by restarting the OpenVPN service with
sudo systemctl restart openvpn@server.
- Verify on DD-WRT: Reconnect the DD-WRT router to your VPN to ensure the error does not reappear.
Issue 2: Error Installing Key Material in DCO
Problem Description:
The error “Impossible to install key material in DCO: No such file or directory” refers to problems involving the Data Channel Offload feature, which is intended to enhance VPN performance by offloading certain processing tasks from the CPU.
Solution Steps:
- Check VPN Configuration Files: Ensure all necessary certificates and keys (CA certificate, client certificate, and client key) are correctly placed and accurately referenced in your DD-WRT’s VPN configuration.
- Disable DCO (If Unnecessary):
- DCO might not be supported adequately by all hardware or DD-WRT builds. To disable DCO, access the VPN configuration file on your router via the administration interface.
- Look for any DCO-related directives and disable them (comment out or remove). You can disable DCO by using the following line to the additional configuration section of your OpenVPN configuration
disable-dco
- Firmware Update: Confirm that your DD-WRT firmware is up to date, as updates may include fixes and enhancements for VPN functionalities.
- Check File Paths and Permissions: Use SSH to connect to your router and verify that all referenced files in your VPN configuration exist at the specified paths and have appropriate permissions.
- Consult Community Forums: If the issue persists, the DD-WRT community forums are a valuable resource for troubleshooting specific to your router model and firmware version.
Final Thoughts
Troubleshooting VPN issues on DD-WRT can be complex, but resolving these common errors can greatly enhance your network’s functionality and security. Ensuring that your VPN configuration is appropriate for your specific router and keeping your system up-to-date are critical steps in maintaining a secure and efficient network.
In conclusion, both OpenVPN and DD-WRT are excellent tools to enhance the security and functionality of your home network. Whether you’re looking to protect your personal information or simply want to boost your internet connection across your household, these technologies offer practical solutions that are worth considering. Embrace these tools to take control of your digital home environment and enjoy a safer, more efficient online experience.

by Joche Ojeda | Mar 8, 2024 | Uncategorized
Navigating the Challenges of Event-Based Systems
Event-based systems have emerged as a powerful architectural paradigm, enabling applications to be more scalable, flexible, and decoupled. By orchestrating system behaviors through events, these architectures facilitate the design of responsive, asynchronous systems that can easily adapt to changing requirements and scale. However, the adoption of event-based systems is not without its challenges. From debugging complexities to ensuring data consistency, developers must navigate a series of hurdles to leverage the full potential of event-driven architectures effectively. This article delves into the critical challenges associated with event-based systems and provides insights into addressing them.
Debugging and Testing Complexities
One of the most daunting aspects of event-based systems is the complexity involved in debugging and testing. The asynchronous and decoupled nature of these systems makes it challenging to trace event flows and understand how components interact. Developers must adopt sophisticated tracing and logging mechanisms to visualize event paths and diagnose issues, which can significantly increase the complexity of testing strategies.
Ensuring Event Ordering
Maintaining a correct sequence of event processing is crucial for the integrity of an event-based system. This becomes particularly challenging in distributed environments, where events may originate from multiple sources at different times. Implementing mechanisms to ensure the orderly processing of events, such as timestamp-based ordering or sequence identifiers, is essential to prevent race conditions and maintain system consistency.
Complex Error Handling
Error handling in event-driven architectures requires careful consideration. The loose coupling between components means errors need to be communicated and handled across different parts of the system, often necessitating comprehensive strategies for error detection, logging, and recovery.
Latency and Throughput Challenges
Balancing latency and throughput is a critical concern in event-based systems. While these architectures can scale effectively by adding more consumers, the latency involved in processing and reacting to events can become a bottleneck, especially under high load conditions. Designing systems with efficient event processing mechanisms and scaling strategies is vital to mitigate these concerns.
Mitigating Event Storms
Event storms, where a flood of events overwhelms the system, pose a significant risk to the stability and performance of event-based architectures. Implementing back-pressure mechanisms and rate limiting can help control the flow of events and prevent system overload.
Dependency Management
Although event-based systems promote decoupling, they can also introduce complex, hidden dependencies between components. Managing these dependencies requires a clear understanding of the event flow and interactions within the system to avoid unintended consequences and ensure smooth operation.
Data Consistency and Integrity
Maintaining data consistency across distributed components in response to events is a major challenge. Event-based systems often require strategies such as event sourcing or implementing distributed transactions to ensure that data remains consistent and accurate across the system.
Security Implications
The need to secure event-driven architectures cannot be overstated. Events often carry sensitive data that must be protected, necessitating robust security measures to ensure data confidentiality and integrity as it flows through the system.
Scalability vs. Consistency
Event-based systems face the classic trade-off between scalability and consistency. Achieving high scalability often comes at the cost of reduced consistency guarantees. Finding the right balance based on system requirements is critical to the successful implementation of event-driven architectures.
Tooling and Monitoring
Effective monitoring and management are essential for maintaining the health of an event-based system. However, the lack of visibility into asynchronous event flows and distributed components can make monitoring challenging. Selecting the right set of tools that offer comprehensive insights into the system’s operation is crucial.
Conclusion
While event-based systems offer numerous advantages, successfully implementing them requires overcoming a range of challenges. By understanding and addressing these challenges, developers can build robust, scalable, and efficient event-driven architectures. The key lies in careful planning, adopting best practices, and leveraging appropriate tools and technologies to navigate the complexities of event-based systems. With the right approach, the benefits of event-driven architecture can be fully realized, leading to more responsive and adaptable applications.

by Joche Ojeda | Jul 4, 2023 | Uncategorized
Last week, I had two presentations, during both of which I was to present an example of data synchronization using the open-source framework we developed in our office, Xari/BitFrameworks. you can read more about the framework here https://github.com/egarim/SyncFramework
I practiced the demo several times and felt confident about it. After all, I was the one who made the last commit to the source. When the conference began, it was my time to shine. I eagerly spoke about the merits of the framework, then it was time for the technical demo.
Everything started well, but after a while, the framework stopped synchronizing data. I was baffled; I had practiced my demo multiple times. What could have gone wrong?
At the end of the demo, I did what everyone does when their presentation fails—I blamed the demo gods.
After resting for a few hours, I reset my computer and cleaned the Visual Studio solution. I practiced several more times and was ready for round two.
I repeated my presentation and reached the technical demo. There was nothing to fear, right? The previous failure was just a fluke… or so I thought. The demo failed even earlier this time. I cursed the demo gods and finished my presentation.
It was a hard week. I didn’t get the dopamine rush I usually got from presentations. It was a rainy Saturday morning, perfect weather to contemplate my failure. I decided not to give up and wrote some integration tests to determine what went wrong.
So why did my demo fail? The demo was about database synchronization using delta encoding theory. For a successful synchronization, I needed to process the deltas in the exact order they were sent to the server. I had a GUID type of index to sort the deltas, which seemed correct because every time I ran the integration test, it worked fine.
Still puzzled by why the demo failed, I decided to go deeper and wrote an integration test for the GUID generation process. I even wrote an article about it, which you can read here.
On my GUID, common problems using GUID identifiers
Now I was even more puzzled. The tests passed sometimes and failed other times. After a while, I realized there was a random element in how GUIDs are generated that introduced a little-known factor: probabilistic errors.
Probabilistic errors in software refer to a category of errors that occur due to the inherent randomness and uncertainty in some algorithms or systems. These errors are not deterministic, i.e., they may not happen every time the same operation is performed. Instead, they occur with a certain probability.
Here are a few examples of situations that could lead to probabilistic errors:
1. **Concurrency and Race Conditions**: In concurrent systems, the order in which operations are executed can be unpredictable and can lead to different outcomes. If the software is not designed to handle all possible execution orders, it can lead to probabilistic errors, such as race conditions, where the result depends on the timing of certain operations.
2. **Network Failures and Distributed Systems**: In distributed systems or systems that rely on network communications, network failures can lead to probabilistic errors. These can include lost messages, delays, and partial failures. As these events are inherently unpredictable, they can lead to errors that occur with a certain probability.
3. **Randomized Algorithms**: Some algorithms, such as those used in machine learning or optimization, involve an element of randomness. These algorithms can sometimes produce incorrect results due to this randomness, leading to probabilistic errors.
4. **Use of Unreliable Hardware**: Hardware failures can lead to probabilistic errors. For example, memory corruption, disk failures, or unreliable network hardware can cause unpredictable and probabilistic errors in the software that uses them.
5. **Birthday Paradox**: In probability theory, the birthday problem or birthday paradox concerns the probability that, in a set of n randomly chosen people, some pair of them will have the same birthday. Similarly, when generating random identifiers (like GUIDs), there is a non-zero chance that two of them might collide, even if the chance is extremely small.
Probabilistic errors can be difficult to diagnose and fix, as they often cannot be reproduced consistently. They require careful design and robust error handling to mitigate. Techniques for dealing with probabilistic errors can include redundancy, error detection and correction codes, robust software design principles, and extensive testing.
So tell me, have it ever happened to you? how did you detected the error? and how did you fix it?
Until next time, happy coding!!!!
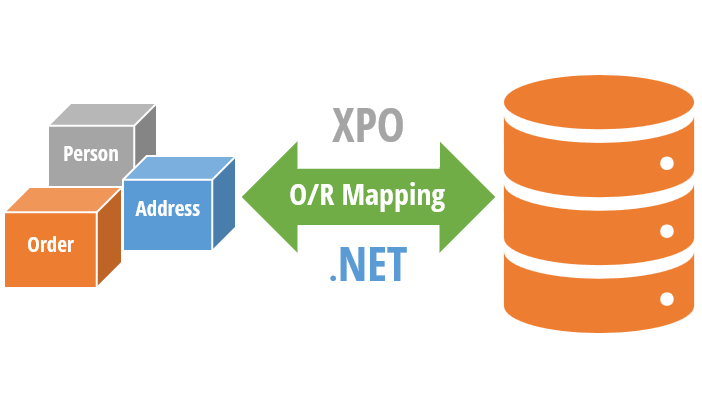
by Joche Ojeda | May 30, 2023 | Uncategorized
Let’s do a quick overview of the main features of XPO before we dive into details.
XPO (eXpress Persistent Objects) is a full-featured Object-Relational Mapping (ORM) framework developed by DevExpress. It is used to provide a mapping between the relational database tables and the objects used in a .NET application.
XPO allows developers to interact with a database in a more natural, object-oriented manner and eliminates the need to write complex SQL statements. It provides a high-level API for working with databases, automating common tasks such as connecting to a database, querying data, and committing changes.
With XPO, developers can focus on the business logic of the application rather than worrying about the low-level details of working with databases.
Throughout the book, we will explore each feature of XPO in depth, providing a comprehensive understanding of its capabilities. However, here are some of the most notable features of XPO that we will highlight:
- Object-Relational Mapping (ORM): XPO provides a mapping between the relational database tables and the objects used in a .NET application. This makes it easier for developers to interact with databases in a more natural, object-oriented manner.
- High-Level API: XPO provides a high-level API for working with databases, automating common tasks such as connecting to a database, querying data, and committing changes.
- Data Types Mapping: XPO automatically maps .NET data types to their corresponding SQL data types and vice versa, eliminating the need for manual data type conversion.
- LINQ Support: XPO includes built-in LINQ (Language Integrated Query) support, making it easier to write complex, fine-tuned queries.
- Customizable SQL Generation: XPO allows developers to customize the SQL generated by the framework, providing greater control over the database operations.
- Lazy Loading: XPO supports lazy loading, meaning that related objects can be loaded on demand, reducing the amount of data that needs to be loaded at once and improving performance.
- Change Tracking: XPO tracks changes made to objects and automatically updates the database as needed, eliminating the need to write manual update statements.
- Validation: XPO provides built-in support for validating objects, making it easier to enforce business rules and ensure data integrity.
- Caching: XPO provides caching capabilities, allowing frequently used data to be cached and reducing the number of database queries required.
- Support for Multiple Databases: XPO supports a wide range of relational databases, including SQL Server, Oracle, MySQL, PostgreSQL, and more.
Enhancing XPO with Metadata : Annotations
In C#, annotations are attributes that can be applied to classes, properties, methods, and other program elements to add metadata or configuration information.
In XPO, annotations are used extensively to configure the behavior of persistent classes.
XPO provides a number of built-in annotations that can be used to customize the behavior of persistent classes, making it easier to work with relational data using object-oriented programming techniques.
Some of the most commonly used annotations include:
- Persistent: Specifies the name of the database table that the persistent class is mapped to.
- PersistentAlias: Specifies the name of the database column that a property is mapped to.
- Size: Specifies the maximum size of a database column that a property is mapped to.
- Key: Marks a property as a key property for the persistent class.
- NonPersistent: Marks a property as not persistent, meaning it is not mapped to a database column.
- Association: Specifies the name of a database column that contains a foreign key for a one-to-many or many-to-many relationship.
In addition to the built-in annotations, XPO also provides a mechanism for defining custom annotations. You can define a custom annotation by defining a class that is inherited from the Attribute class.
Annotations can be applied using a variety of mechanisms, including directly in code, via configuration files, or through attributes on other annotations.
We will witness the practical implementation of annotations throughout the book, including our own custom annotations. However, we wanted to introduce them early on as they play a crucial role in the efficient mapping and management of data within XPO.
Now that we have refreshed our understanding of XPO’s main goal and features, let’s delve into the “O”, the “R”, and the “M” of an ORM.
And that’s all for this post, until next time ))
We are excited to announce that we are currently in the process of writing a comprehensive book about DevExpress XPO. As we work on this project, we believe it is essential to involve our readers and gather their valuable feedback. Therefore, we have decided to share articles from the book as we complete them, giving you an opportunity to provide input and suggestions that we can consider for inclusion in the final release. Keep in mind that the content presented is subject to change. We greatly appreciate your participation in this collaborative effort.
Related Articles
SOLID design pattern and XPO
What is an O.R.M (Object-Relational Mapping)
ADO The origin of data access in .NET
Relational database systems: the holy grail of data