
by Joche Ojeda | Oct 10, 2021 | Data Synchronization
In the last post, we talked about what are deltas and how by using them we can synchronize data structures.
So, in this post, I will describe the necessary parts needed to implement Delta-based synchronization, let’s start
- Data Object: any database, object, graph, or file system that we are tracking for synchronization
- Delta: a delta is a data difference between the original and the current state of a data object
- Node: is a point of the synchronization network, there are 2 types of nodes
- Client node: a node that is able to produce and process deltas
- Server node: a node that is used only to exchange deltas, it can optionally process deltas too.
- Delta Store: storage where you can save deltas so you can later exchange them with other nodes
- Delta Processor: a utility that helps you includes the deltas created in other nodes in your current copy of the data object
Now let’s implement this concept to synchronize a database
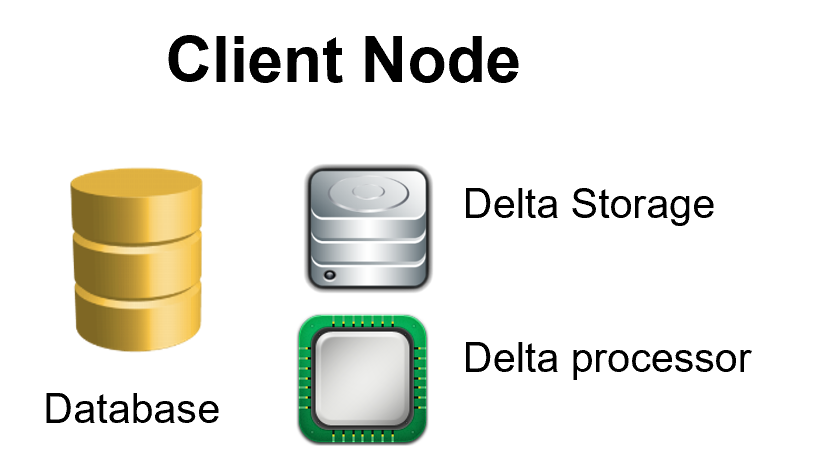
Ok so each database that we want to synchronize will be a client node and a client node should be able to produce and store deltas and to process deltas produced by other nodes, so our database node should look like the following diagram
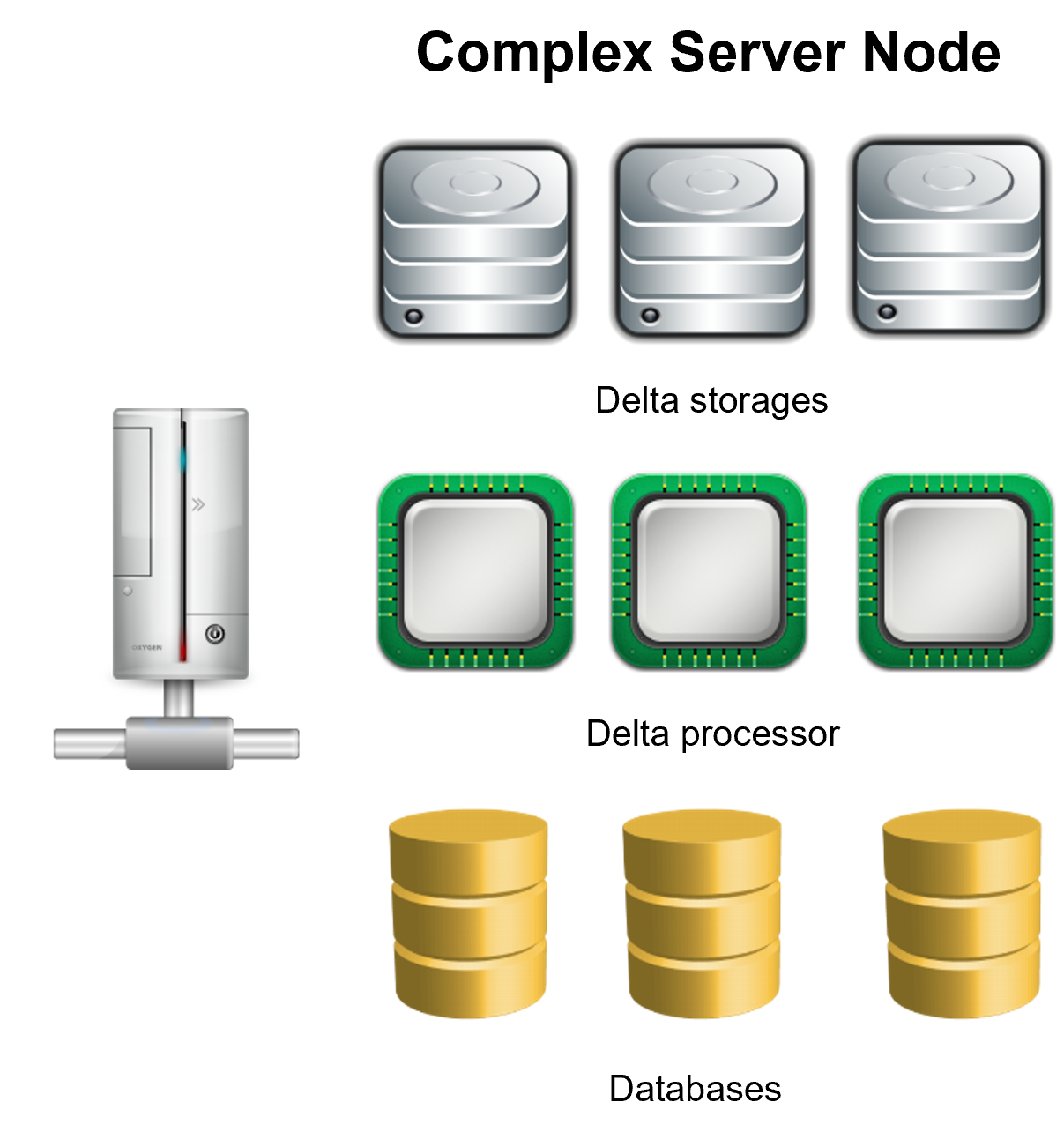
The server node can be as simple as just delta storage exposed in an HTTP API as you can see in the basic server node diagram or use several delta storages and delta processors as show on the complex server node diagram

And with those diagrams, I finish this post, in the next post we will implement those concepts in C# code
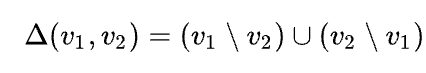
by Joche Ojeda | Oct 10, 2021 | Data Synchronization
To Synchronize data is one of the most challenging tasks out there, especially if you are working with LOB applications
There are many ways to synchronize data, the most common technique is to compare records by modification date and then merge the data to create a master record.
Here the main problem is that you have to have a way to compare each type of record, so it gets cumbersome as soon as the number of types in your application begins to grow.
Also, you have to have a log of what gets created and what gets deleted so you can do the same changes on the other nodes
Delta-based synchronization
delta-based synchronization is a problem of identifying “what changed” between each execution of a sync process
A directed delta also called a change, is a sequence of (elementary) change operations which, when applied to one version V1, yields another version V2 (note the correspondence to transaction logs in databases). In computer implementations
In delta synchronization, there are 2 main tasks
- Record the deltas (or small difference of data between nodes)
- Transmit these differences to the other nodes so they can process them
Implementing Delta-based synchronization for relational databases
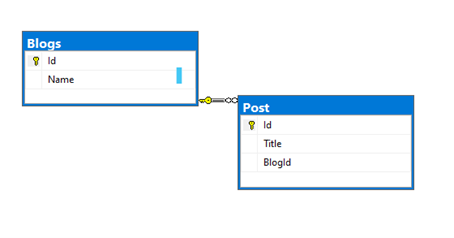
The schema above represents a blog’s database, it’s a really simple schema so its easy to understand, now this is the scenario
We have the main database that we will call “Master” and 2 other databases named client A and client B.
Now let insert data in the master

Each DML statement should be converted in a delta (or a data difference)

Δ1

Δ2

Δ3

Copy deltas Δ 1, Δ 2, Δ 3 to the clients
So, after processing the deltas on each client, the data in all databases should look like the picture below
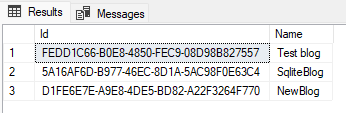
So that’s it for this post, in the next post we will be examing each part that is necessary to do delta-based synchronization