Teaching a Machine Your House Style

I have been writing software for a long time. Long enough to have a house style — that
collection of small, stubborn opinions about how a thing should be built that you accumulate
over the years and can no longer fully explain. You just know it when you see it. A junior joins
the team, writes something that compiles, passes the tests, ships — and you still feel a little
itch on the back of your neck, because it isn't how we do it here.
For most of my career that itch was a human problem. You fix it with code review, with pairing,
with a long lunch where you explain why the thing the framework lets you do is not the thing you
should do. It takes months. Sometimes years. And then the person leaves and takes half of it with
them.
So a few weeks ago I asked myself a question that turned out to be more interesting than I
expected: could I teach a machine my house style? Not "can it write code" — they can all write
code now, that part is boring. I mean the itch. Could I get an assistant to write code that
doesn't make me itch?
This is the story of how I got there. I'm going to keep it deliberately abstract — no framework
names, no product names, no vendor. Pretend I maintain some large, old line-of-business toolkit
that my team built over a decade and has Strong Opinions about. The shape of the solution is the
part worth sharing, and the shape is general.
The thing that doesn't work
The obvious first move — the one everybody tries — is to write a giant prompt. "You are an expert
in our framework. Always use the repository pattern. Never hardcode strings. Prefer composition
over inheritance." You know the genre. You write three pages of thou shalts and you paste them
in front of every request.
It sort of works, the way a horoscope sort of works. The model nods along and then, on the third
file, quietly does the thing you told it never to do, because the example it half-remembers from
its training data did it that way and your three pages of scripture lost the argument.
The problem is that I was describing my house style instead of showing it. And I was trusting
the output instead of grading it. Both of those turned out to be the mistake.
Show, don't tell: learning from the real code
The first shift was to stop writing prose about my preferences and start pointing the assistant at
the actual code. Not curated examples — the real repositories, the ones with the warts.
The assistant reads through them and does something humble and useful: it writes itself notes. Not
"here is the whole codebase" (nobody can hold that in their head, machine or otherwise) but short,
distilled observations. In this codebase, this kind of object is almost always built this way. When
people need a calculated value, they reach for this. And — crucially — here are the three things
that show up in the old, bad code and never in the new, good code.
That last part is the one I underestimated. Half of a house style isn't what you do; it's what you
refuse to do. So the notes come in two flavors: the patterns to imitate, and the anti-patterns
— the deprecated API, the copy-paste boilerplate, the user-facing string frozen into a source file
where no translator will ever find it. The assistant mines those out of the real code too, because
the real code is full of old mistakes, and old mistakes are a fantastic teacher.
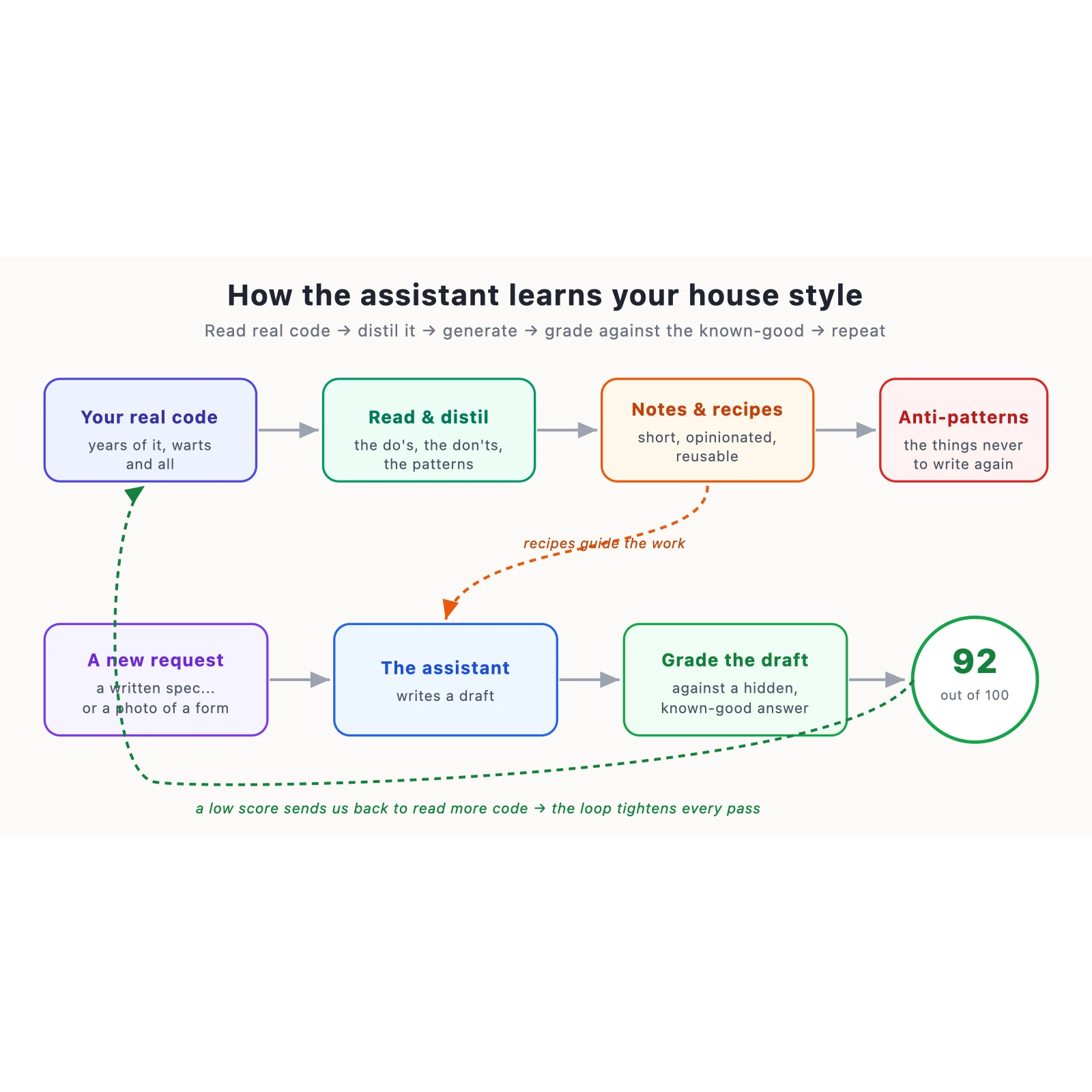
Out of those notes I distil recipes — tight, opinionated how-to guides for the handful of things
the assistant will be asked to do over and over. A recipe is the thing I'd say to a new hire in two
minutes flat: when you build one of these, it's an interface not a class, the rules live up here not
down there, and for the love of god don't hardcode the message. Short enough to actually be read.
Opinionated enough to actually be useful.
Now the part I'm proud of: give it an exam it can fail
Here's where it stopped being a prompt-engineering exercise and started being something I'd trust.
Reading code and writing recipes is the teaching. But how do you know it learned? You give it a
test. And not a soft test — a real exam, with an answer key it never gets to see.
I call each one a golden case, and it works like this. I take a real file from my own codebase —
something I already know is right, a piece of the gold standard. I hide it. Then I describe the task
to the assistant in plain language, the same way I'd describe it in a ticket, and I let it write its
own version from scratch. It has the recipes. It does not have my answer.
Then I grade what it produced. Three ways at once:

What must be present. Did it reach for the right pattern? Are the rules declared where my house
style puts them? Did it look things up instead of hardcoding them? Each of these is a green check it
has to earn.
What must be absent. Did it sneak in the deprecated API? The boilerplate? The frozen string?
These are the anti-patterns, and every one of them is a red mark.
The gate. Does the thing actually build? And did it cross any line that is simply
non-negotiable? Because here is the rule that changed everything for me: a draft that fails the
gate scores zero. Not "minus a few points." Zero.
That gives me two numbers for every attempt. The raw score — how close it got to the gold, in
spirit. And the adjusted score — the raw score, unless it tripped the gate, in which case all
that lovely, plausible, almost-right code is worth exactly nothing.
I cannot overstate how much that second number matters. Early on I had a case that scored 92 on the
raw number — gorgeous, idiomatic, exactly my style — and zero adjusted, because it had quietly left
a couple of method bodies in a state that would never survive a build. A pretty wrong answer. The
whole point of the exam is to refuse to be charmed by a pretty wrong answer. A human reviewer,
tired on a Friday, gets charmed. The exam doesn't.
And when a case scores low? That's not a failure of the experiment — that's the experiment working.
A low score is a signpost that says go read more code, write a better recipe, and come back. The
loop tightens every time around.
A small magic trick: it can read a picture
One afternoon, mostly to see if it would work, I stopped describing a screen in words and just
handed the assistant a picture of one — a rough mockup, the kind of thing you'd sketch in a
meeting. Boxes, labels, a couple of tabs.
It read the picture and built the layout. The tab strip became tabs. The little side-by-side panels
became side-by-side panels. The labels became field names, properly cased, with a polite note
listing the two it wasn't sure about. And — this is the part that made me laugh out loud — I made
that a golden case too. I drew a synthetic mockup, hid the real layout that matched it, and graded
the assistant's reading of my drawing against the truth. It scored in the nineties. You can grade
vision the exact same way you grade text, as long as you have a hidden answer to grade against.
One more thing: let it run anywhere
The last piece is unglamorous but it's the reason this is practical instead of a science project.
The assistant isn't one brain. It's a set of jobs, and each job gets to pick the brain that fits
it.
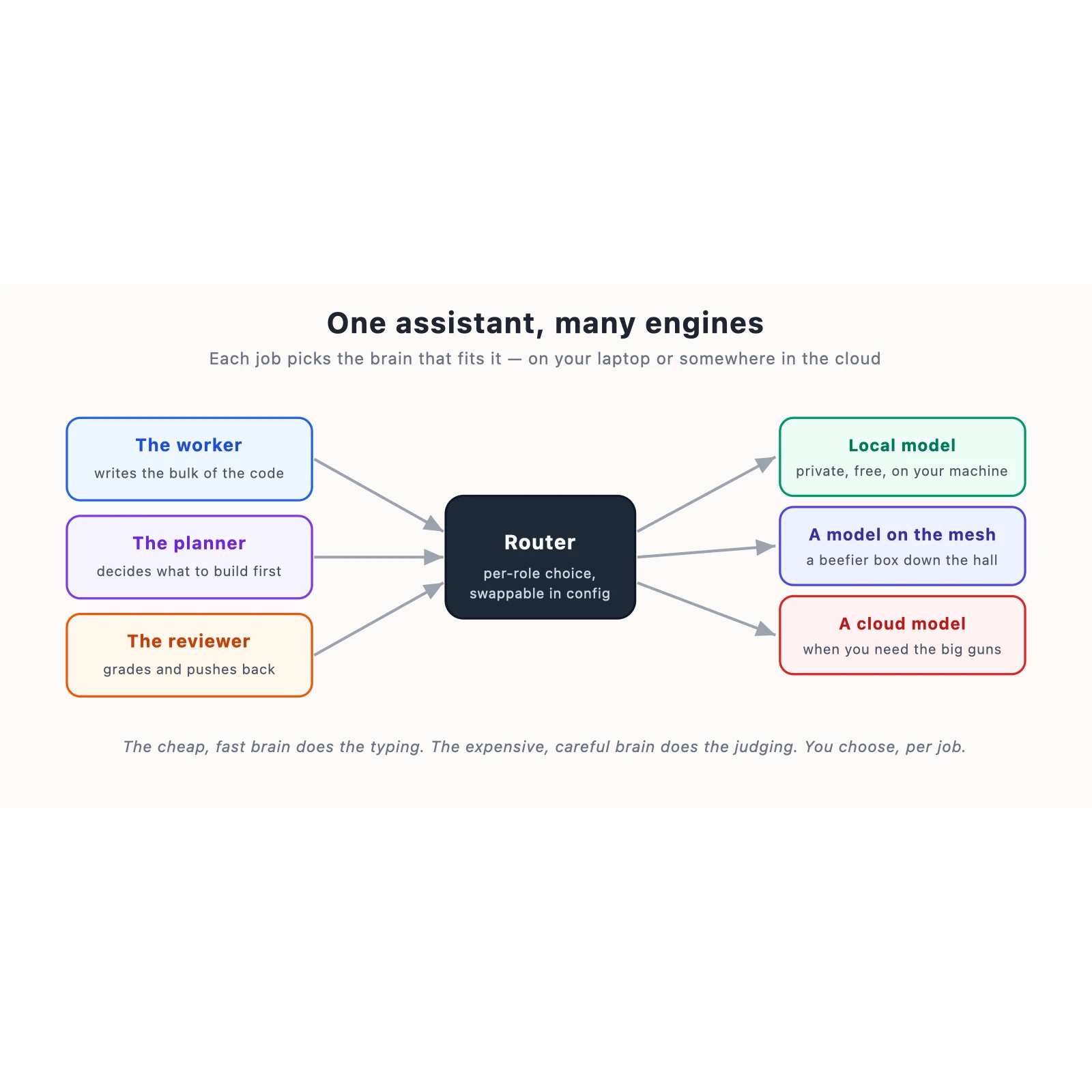
The worker — the one that does the bulk of the typing — can be a small, fast model running locally
on my own machine. Private, free, no round trip. The reviewer — the one whose job is to be skeptical
and grade hard — can be a bigger, more careful model in the cloud, because judgment is where you want
to spend the money. The planner can be something in between. And which is which is just a line in a
config file, swappable on a Tuesday afternoon when a better model comes out.
The cheap, fast brain does the typing. The expensive, careful brain does the judging. You decide,
per job, and you change your mind whenever you like.
What I actually learned
I set out to teach a machine my house style. What I learned is that I didn't really have my house
style written down anywhere — it lived in the itch on the back of my neck. The work of building this
thing was mostly the work of dragging those opinions out into the daylight where they could be
checked: a recipe instead of a feeling, a forbidden signal instead of a sigh, a gate instead of a
Friday-afternoon shrug.
The machine is the smaller half of the story. The bigger half is that an exam you can fail is worth
ten pages of an exam you can't. Describe less. Grade more. Hide the answer key. And when the score
comes back low, don't argue with it — go read more of your own code.
That, it turns out, is also pretty good advice for the humans.