Brownfield Projects Are a Gold Mine for Training Agents

In my last post I wrote about teaching a
code-generation assistant my house style — not by lecturing it in a giant prompt, but by showing
it real code and then grading what it produced against hidden golden cases: known-good files it
never gets to see, only get measured against.
A friend read it and asked the obvious question: "Okay, but where do you get the gold? Do you have
to sit down and write all those perfect example files by hand?"
And that's the thing I want to talk about today, because the answer surprised me too. You don't
write the gold. You already have it. It's sitting in the worst-looking repository you own — the
big, old, line-of-business beast that everyone calls "the legacy system" in a slightly lowered
voice. The brownfield project. The one nobody wants to be assigned to.
That project is not your shame. For training an agent, it is the single richest asset you have.
The instinct that's exactly backwards
When people decide to "ground" or "train" an assistant on their way of doing things, the instinct is
almost always the same: let me start a clean little reference repo. A few tidy, exemplary files. No
mess, no history, just the good stuff.
I understand the instinct. I had it too. And it's exactly backwards.
A greenfield project is a desert. Think about what's actually in it: a handful of files. No
consensus yet — the team is still arguing about the shape of things, so there's no repeated pattern
to learn from. No mistakes, which sounds good until you remember that half of a house style is
knowing what not to do, and a project with no mistakes can't teach you that. No history worth
mining. And almost nothing you can hide and grade against, because there's barely anything there.
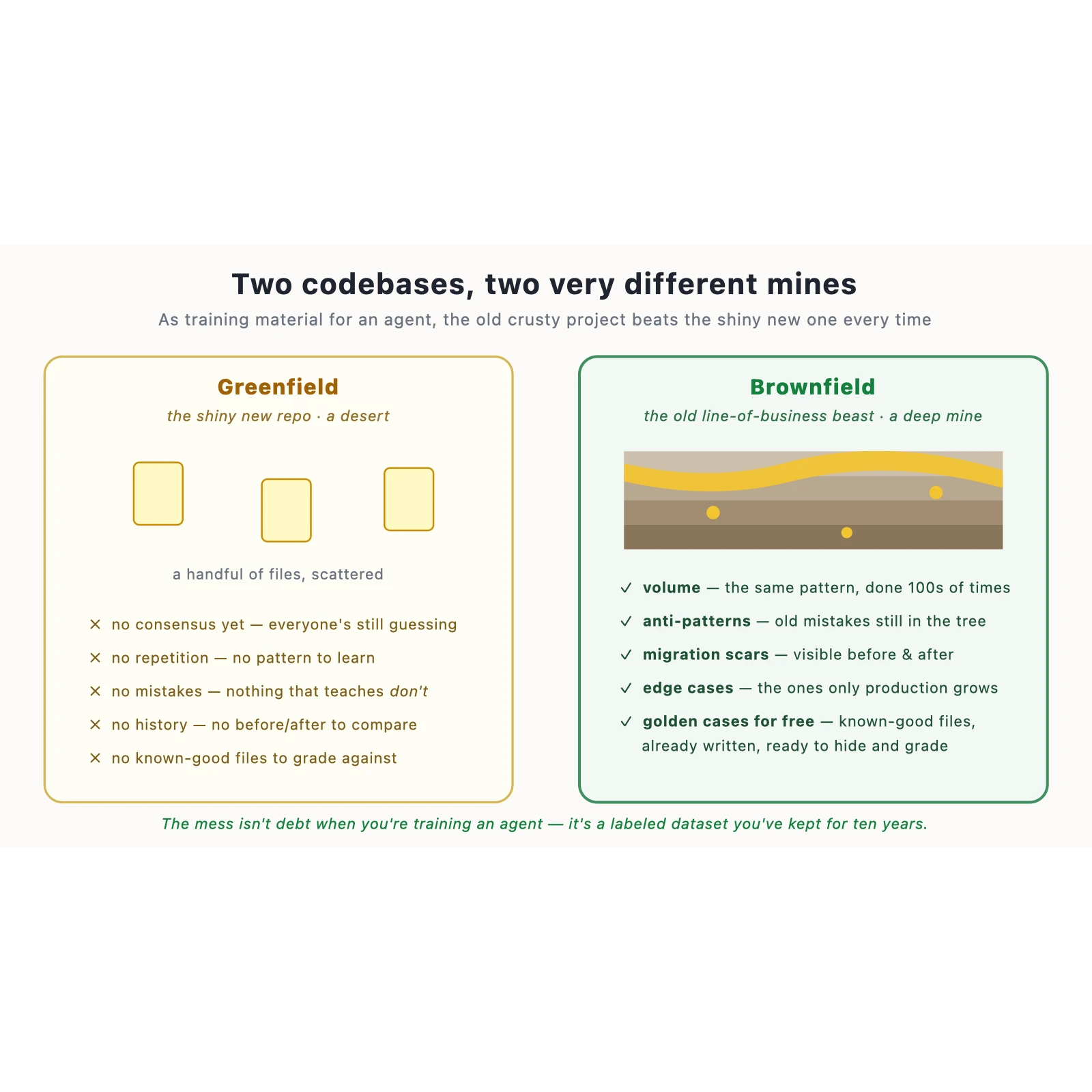
Now look at the brownfield beast. It is a deep mine.
Volume. The same kind of thing has been built three hundred times. That repetition is exactly
what lets a pattern emerge statistically instead of from your say-so. The house style isn't your
opinion in there — it's the visible center of gravity of three hundred examples.
Anti-patterns, for free. The old, bad ways are still in the tree. The deprecated call nobody got
around to ripping out. The copy-pasted block that predates the helper. The hardcoded message that
will never be translated. This is the don't half of the house style, and the brownfield project is
absolutely full of it — which is a gift, because now the agent can learn the difference.
Edge cases. Production grows weeds that no clean design ever anticipates. The brownfield code has
survived a decade of real users doing real, unreasonable things, and every one of those scars is a
lesson a greenfield project simply hasn't lived long enough to teach.
And golden cases you didn't have to write. This is the punchline. A mature codebase is wall-to-wall
with files you already know are good. You don't author exam answers — you reach in, pick a file the
team is proud of, hide it, and ask the assistant to produce its own version from the same brief. The
gold was already mined. You're just deciding which nuggets to grade against.
The seam nobody mentions: your git history
Here's the part I didn't see coming, and it's my favorite.
It isn't only the current state of a brownfield project that's valuable. The history is a second
mine, and in some ways a richer one — because git has already done the most expensive part of
building a training set: it labeled the data for you.
Every refactor commit in that decade-long history is a perfectly labeled pair. On the left, the
"before" — the old way, full of exactly the signals you want the assistant to avoid. On the right,
the "after" — the way the team eventually settled on, full of the signals you want it to learn. And
in the commit message, in plain language, why.
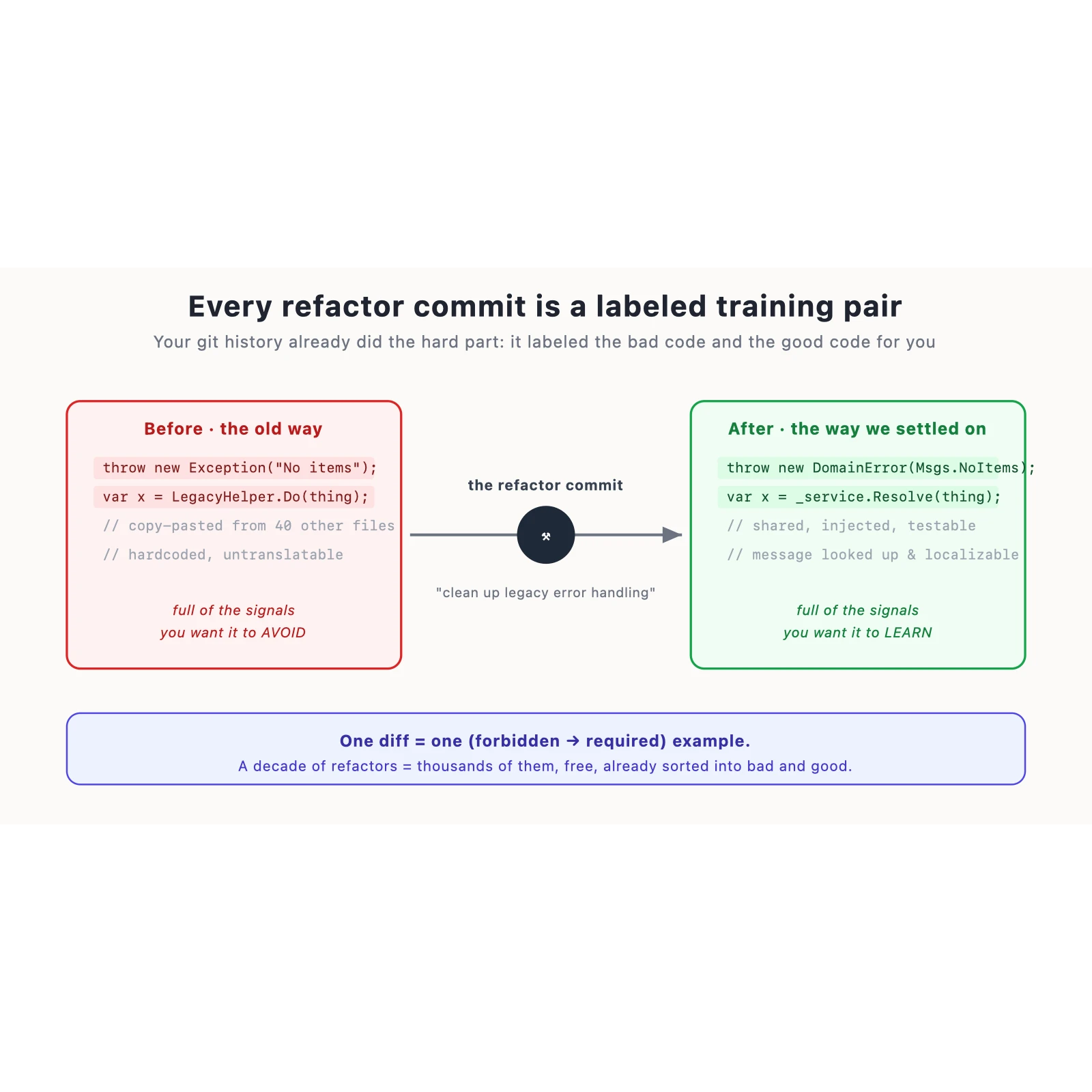
One diff is one example of this was wrong, this is right, and here's the reason. A decade of
refactors is thousands of those examples, free, already sorted into bad and good by the people who
lived it. You couldn't pay for a cleaner dataset, and it's been sitting in your repo the whole time,
disguised as git log.
The one catch: not all of the mine is gold
I have to be honest about the trap, because it's a real one.
A brownfield project is full of good code and bad code, and if you point an agent at it naively, it
will cheerfully learn to imitate the worst of it with the same enthusiasm as the best. The mess is an
asset only if you can tell the gold from the rubble.
That's the whole reason the previous post mattered. The grading — the golden cases, the anti-patterns
marked as forbidden, the gate — is what turns a pile of inconsistent legacy code into signal. You use
the recent, frequent, agreed-upon code as the gold; you mark the old deprecated shapes as the
anti-patterns; and you let the exam, not your memory, decide which is which. Without that, the
brownfield project is just noise. With it, the inconsistency itself becomes the lesson: here is what
we used to do, here is what we do now, and you can see the team change its mind in the diff.
What I actually learned
We carry our brownfield projects around like a backpack full of bricks. Technical debt. The thing
we'd rewrite if we ever had a quarter free. And for shipping features, fine, maybe it is a burden.
But the moment you stop trying to extend that old system and start trying to teach from it,
the whole thing flips. The volume becomes a pattern. The mistakes become the don't. The scars
become edge cases. The git history becomes a labeled dataset. The mess — the exact mess you've been
apologizing for — turns out to be the most honest, most complete record of how your team actually
builds software that exists anywhere.
You don't have to write the gold. You've been mining it for ten years. You just never called it that.